
Summary: At least one instance of Real Time Predictive Model development in a streaming data problem has been shown to be more accurate than its batch counterpart. Whether this can be generalized is still an open question. It does challenge the assumption that Time-to-Insight can never be real time.
A few months back I was making my way through the latest literature on “real time analytics” and “in stream analytics” and my blood pressure was rising. The cause was the developer-driven hyperbole that claimed that the creation of brand new insights using advanced analytics has become “real time”. My reaction at the time, Humbug.
The issue then as now is the failure to differentiate between time-to-action and time-to-insight. Not infrequently the statements about ‘fast data’ are accompanied by a diagram like this, which to me has a fatal flaw.
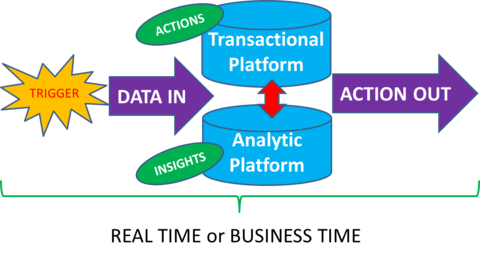
The flaw, to my way of thinking, is that there are really two completely different tasks here with very different time frames.
Time-to-Action: Typically the customer-generated trigger comes in one side, enters your transactional platform where it may be scored, next best offers formulated, recommenders updated, or any number of other automated tasks may take place. Based on these predetermined routines the desired and pre-planned action comes out, not infrequently in an action that is fed back to the customer. Time-to-Action can indeed be real time, right down to milliseconds.
Time-to-Insight: These actions and the algorithms that created them were preplanned. That is, a team of data scientist spent time and effort to explore the data, clean, transform, and perhaps normalize it, selected features, and then built a number of models until one proved to their satisfaction that it was sufficiently robust to be implemented in the transactional system. That is Time-to-Insight, and that is decidedly not real time.
Is Real Time Predictive Model Development Even Possible?
Especially now that streaming data processing has become such a hot topic I wanted to revisit my earlier conclusion and see if real time analytics, specifically the creation of new predictive models, could in fact be real-time, and truly on-the-fly.
Batch versus Streaming Fundamentals
First off, let me be clear that we’re talking about streaming data problems, or perhaps more correctly ‘unbound data’ problems. If it’s not streaming, it’s by definition batch.
- Batch processing has always been the paradigm for predictive analytics. This generally implied using the whole data set (or a large sample) that was sufficiently large to allow for good model development.
- Batch allowed time to consider, clean, and transform the data. Batch also allowed for data scientists to experiment with different machine learning tools to optimize accuracy.
- But perhaps most difficult to get around is that in streaming data the samples must necessarily be smaller than the whole. Even windowing techniques that amount to micro-batch must necessarily be only a small fraction of the total data. Yes, window size can be balanced with the need for decision latency. That is to say, a window can be several minutes’ worth, or even hours’ worth of data if that suits your business need. A window might contain several thousand or even a hundred thousand observations under these assumptions. This might work in modeling some kinds of human purchase behavior but not for fraud detection or many factory-floor fault detection problems, and it’s not the norm in streaming. Normally windows are measured in seconds or milliseconds with proportionately smaller data included.
The “Correctness” Problem and Lambda Architecture
Whether we are talking about quantitative analytics (sums, medians, top-N, standard deviations, and the like) or actual predictive models, streaming analytics was always said to have a “correctness” problem. That is, calculations produced on a subset of the data could only approximate the accuracy of the same calculation conducted on the whole data set.
This “correctness” argument has come under fire since both the streaming (subset) calculation and the batch (entire data set) calculations are approximations of the true condition. As a result, Tyler Akidau, a leading developer of streaming systems at Google says “Streaming systems have long been relegated [unfairly] to a somewhat niche market of providing low-latency, inaccurate/speculative results, often in conjunction with a more capable batch system to provide eventually correct results, i.e. the Lambda Architecture.
If you’re not familiar with the Lambda Architecture model, Akidau goes on to explain “the basic idea is that you run a streaming system alongside a batch system, both performing essentially the same calculation. The streaming system gives you low-latency, inaccurate results (either because of the use of an approximation algorithm, or because the streaming system itself does not provide correctness), and sometime later a batch system rolls along and provides you with correct output.”
The Surprising Finding
With all these factors seemingly raising insurmountable barriers to real-time predictive analytics I was surprised to find one example where it is not only successful, but actually claims greater accuracy than the same model run in batch.
The example comes from UK-based Mentat Innovations (ment.at) which in December 2015 published these results regarding their proprietary predictive modeling package called “Streaming Random Forests”. Without repeating all of their detail which you can see here, here is a brief summary.
Using a well-known public database (ELEC2) which is used as a benchmark in streaming data literature:
Each record contains a timestamp, as well as four covariates capturing aspects of electricity demand and supply for the Australian New South Wales (NSW) Electricity Market from May 1996 to December 1998.
To quote directly from their findings:
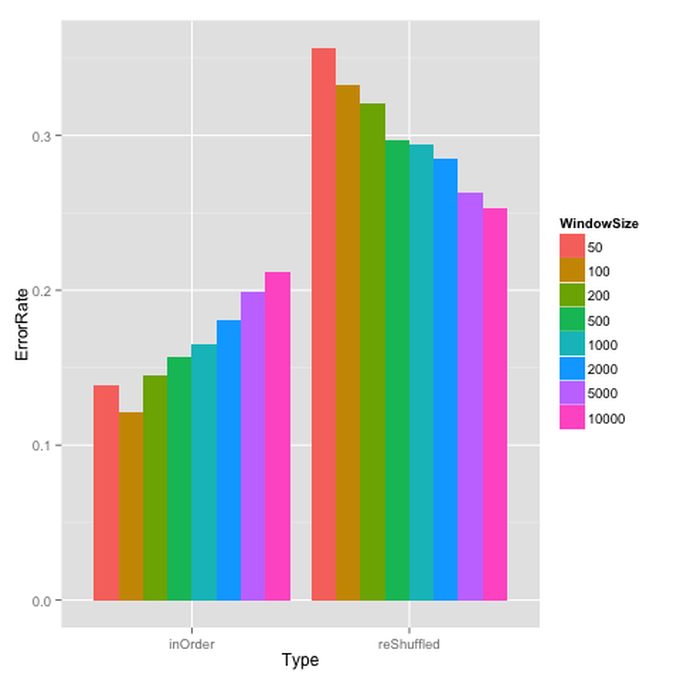
Below we report the error rate (lower is better) achieved by a sliding window implementation of random forests using the randomForest package in R, for 8 different window sizes (left group of bars in the Figure below). When the dataset is ordered by timestamp, the best performing window size is 100, on the lower end of the scale. This is classic case of “more data does not equal more information”: using 100 times more data (w=10,000 vs w=100) almost doubles (175%) the error rate!!
To drive the point home, we took the same data, but presented it to the classifier in random order so that it was no longer possible to take advantage of temporal effects. In this case, without any temporal effects, indeed the accuracy improved with larger window sizes.
The advantage that a well-calibrated streaming method can have over its offline counterpart in a streaming context is quite dramatic: in this case, the best-performing streaming classifier has an error rate of 12%, whereas a random forest trained on the entire dataset (minus 10% withheld for testing) achieves an error rate of 24%. A fraction of the data, double the accuracy!
Let me repeat the central finding. They have built a more accurate real time classifier using a very small amount of windowed data that lends itself to very low latency real time streaming systems. And they have demonstrated that the accuracy is greater than for the same data run in batch.
What we have here is a breakthrough in real time predictive analytics. In fairness, presenting any gradient decent tool such as neural nets with the data sorted in time sequence is not a new idea. This is a procedure that’s been used for some time to reduce the likelihood of overfitting to local optima, a problem extremely common in gradient decent tools.
Does it Generalize?
Here are the claims that Mentat makes:
- No need for classifier selection and tuning (window size or otherwise).
- No need for you to host the decision engine for your web app.
- No need for you to monitor the performance of your model and decide when and how to retrain it – the self-tuning engine monitors performance and ensures it remains optimal at all times.
- No need for you to scale out as you get more data.
These strike me as generally supportable claims based on their demonstration experiment. Providing the data in time series means less probability of overfitting. The problem of temporal drift in your models is eliminated as each recalculation includes the next data points and means your model remains up to date.
Whether this approach is appropriate for your specific situation is open for consideration.
- One issue would be the need for extremely low latency.
- Another would be the assumption that your model is prone to drift in fairly short time frames that would make the constant updating a worthwhile feature.
- Still a third would be the apparent simplicity and elimination of other ‘moving parts’ in a traditional system.
Taking nothing away from their accomplishment this is the first and indeed the only example of real time predictive modeling I have personally been able to find. If you know of others please add a comment and reference to this article.
About the author: Bill Vorhies is Editorial Director for Data Science Central and has practiced as a data scientist and commercial predictive modeler since 2001. He can be reached at:
{kind=link}