
Summary: In this Lesson 2 we continue to provide a complete foundation and broad understanding of the technical issues surrounding an IoT or streaming system so that the reader can make intelligent decisions and ask informed questions when planning their IoT system.
|
In Lesson 1 |
In This Article |
In Lesson 3 |
|
Is it IoT or Streaming |
Stream Processing – Open Source |
Three Data Handling Paradigms – Spark versus Storm |
|
Basics of IoT Architecture – Open Source |
What Can Stream Processors Do |
Streaming and Real Time Analytics |
|
Data Capture – Open Source with Options |
Open Source Options for Stream Processors |
Beyond Open Source for Streaming |
|
Storage – Open Source with Options |
Spark Streaming and Storm |
Competitors to Consider |
|
Query – Open Source Open Source with Options |
Lambda Architecture – Speed plus Safety |
Trends to Watch |
|
|
Do You Really Need a Stream Processor |
|
|
|
Four Applications of Sensor Data |
|
Continuing from Lesson 1, our intent is to provide a broad foundation for folks who are starting to think about streaming and IoT. In this lesson we’ll dive into Stream Processing the heart of IoT, then discuss Lambda architecture, whether you really need a Stream Processor, and offer a structure for thinking about what sensors can do.
Stream Processing – Open Source
Event Stream Processing platforms are the Swiss Army knives that can make data-in-motion do almost anything you want it to do.
The easiest way to understand ESP architecture is to see it as three layers or functions, input, processing, and output.
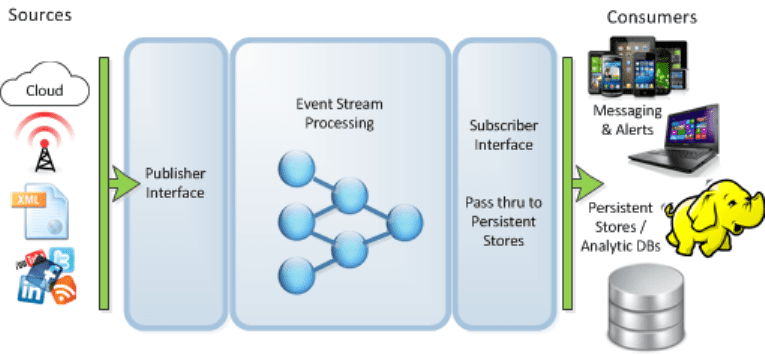
Input accepts virtually all types of time-based streaming data and multiple input streams are common. In the main ESP processor occur a variety of actions called programs or operators. And the results of those programs are passed to the subscriber interface which can send alerts via human interfaces or create machine automated actions, and also pass the data to Fast and Forever data stores.
It is true that Stream Processing platforms can directly receive data streams, but recall that they are not good at preserving accidentally lost data so you will still want a Data Capture front end like Kafka that can rewind and replay lost data. It’s likely over the near future that many stream processors will resolve this problem and then you will need to revisit the need for a Kafka front end.
Stream Processing Requirements
The requirements for your stream processor are these:
- High Velocity: Capable of ingesting and processing millions of events per seconds depending on your specific business need.
- Scales Easily: These will all run on distributed clusters.
- Fault Tolerant: This is different than guaranteeing no lost data.
- Guaranteed Processing: This comes in two flavors: 1.) Process each event at least once, and 2. Process each event only once. The ‘only-once’ criteria is harder to guarantee. This is an advanced topic we will discuss a little later.
- Performs the Programs You Need for Your Application.
What Can ESP Programs Do
The real power is in the programs starting with the ability to do data cleansing on the front end (kind of a mini-MDM), then duplicate the stream of data multiple times so that each identical stream can be used in different analytic routines simultaneously without waiting for one to finish before the next begins. Here’s a diagram from a healthcare example used in a previous article describing how this works that illustrates multiple streams being augmented by static data, and processed by different logic types at the same time. Each block represents a separate program within the ESP that needs to be created by you.
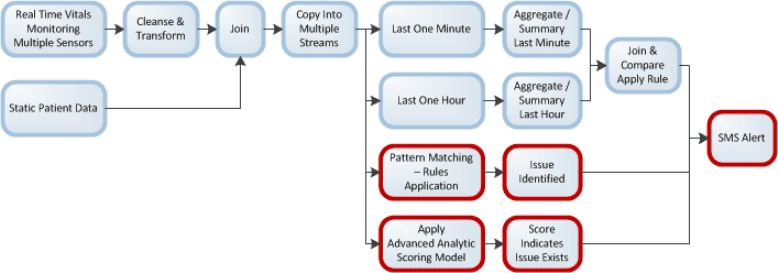
There are a very large number of different logic types that can be applied through these ESP programs including:
- Compute
- Copy, to establish multiple processing paths – each with different retention periods of say 5 to 15 minutes
- Aggregate
- Count
- Filter – allows you to keep only the data from the stream that is useful and discard the rest, greatly reducing storage.
- Function (transform)
- Join
- Notification email, text, or multimedia
- Pattern (detection) (specify events of interest EOIs)
- Procedure (apply advanced predictive model)
- Text context – could detect for example Tweet patterns of interest
- Text Sentiment – can monitor for positive or negative sentiments in a social media stream
There is some variation in what open source and proprietary packages can do so check the details against what you need to accomplish.
Open Source Options for Stream Processing
The major open source options (all Apache) are these:
Samza: A distributed stream processing framework. It uses Kafka for messaging, and YARN to provide fault tolerance, processor isolation, security, and resource management.
NiFi: This is a fairly new project still in incubation. It is different because of its user-friendly drag-and-drop graphical user interface and the ease with which it can be customized on the fly for specific needs.
Storm: A well tested event based stream processor originally developed by Twitter.
SPARK Streaming: SPARK Streaming is one of the four components of SPARK which is the first to integrate batch and streaming in a single enterprise capable platform.
SPARK Streaming and Storm Are the Most Commonly Used Open Source Packages
SPARK has been around for several years but in the last year it’s had an amazing increase in adoption, now replacing Hadoop/MapReduce in most new projects and with many legacy Hadoop/MapReduce systems migrating to SPARK. SPARK development is headed toward being the only stack you would need for an IoT application.
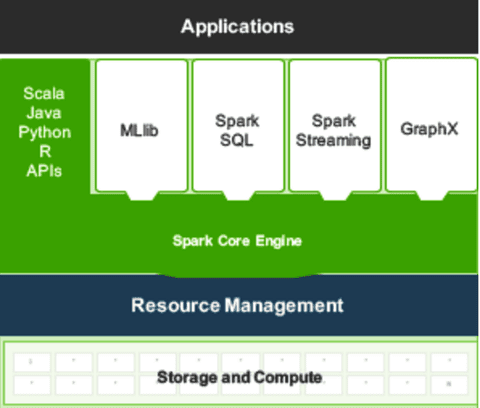
SPARK consists of five components all of which support Scala, Java, Python, and R.
- SPARK: The core application is a batch processing engine that is compatible with HDFS and other NoSQL DBs. Its popularity is driven by the fact that it is 10X to 100X times faster than Hadoop/MapReduce.
- ML.lib: A powerful on-board library of machine learning algorithms for data science.
- SPARK SQL: For direct support of SQL queries.
- SPARK Streaming: Its integrated stream processing engine.
- GraphX: A powerful graph database engine useful outside of streaming applications.
Storm by contrast is a pure event stream processor. The differences between Storm and SPARK Streaming are minor except in the area of how they partition the incoming data. This is an advanced topic discussed later.
If after you’ve absorbed the lesson about data partitioning and you determine this does not impact your application then in open source SPARK / SPARK Streaming is the most likely choice.
Lambda Architecture – Speed Plus Safety
The standard reference architecture for an IoT streaming application is known as the Lambda architecture which incorporates a Speed Layer and a Safety Layer.
The inbound data stream is duplicated by the Data Capture app (Kafka) and sent in two directions, one to the safety of storage, and the other into the Stream Processing platform (SPARK Streaming or Storm). This guarantees that any data lost can be replayed to ensure that all data is processed at least once.
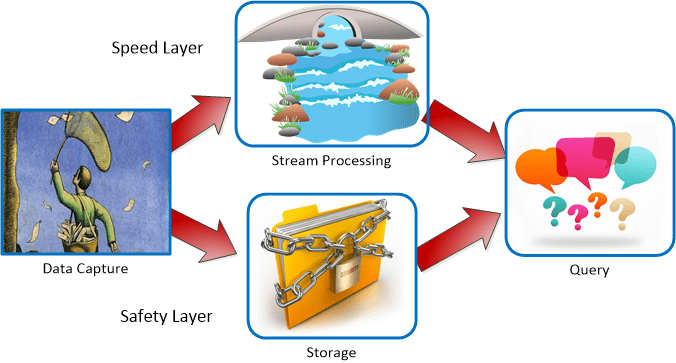
The queries on the Stream Processing side may be extracting static data to add to the data stream in the Stream Processor or they may be used to send messages, alerts, and data to the consumers via any number of media including email, SMS, customer applications, or dashboards. Alerts are also natively produced within the Stream Processor.
Queries on the Storage safety layer will be batch used for creating advanced analytics to be embedded in the Stream Processor or to answer ad hoc inquiries, for example to develop new predictive models.
Do You Really Need a Stream Processor?
As you plan your IoT platform you should consider whether a Stream Processor is actually required. For certain scenarios where the message to the end user is required only infrequently or for certain sensor uses it may be possible to skip the added complexity of a Stream Processor altogether.
When Real Time is Long
When real time is fairly long, for example when notifying the end user of any new findings can occur only once a day or even less often it may be perfectly reasonable to process the sensor data in batch.
From an architecture standpoint the sensor data would arrive at the Data Capture app (Kafka) and be sent directly to storage. Using regular batch processing routines today’s data would be analyzed overnight and any important signals sent to the user the following day.
Batch processing is a possibility where ‘real time’ is 24 hours or more and in some cases perhaps as short as 12 hours. Shorter than this and Stream Processing becomes more attractive.
It is possible to configure Stream Processing to evaluate data over any time period including days, weeks, and even months but at some point the value of simplifying the system outweighs the value of Stream Processing.
Four Applications of Sensor Data
There are four broad applications of sensor data that may also impact your decision as to whether or not to incorporate Stream Processing as illustrated by these examples.
Sensor Direct: For example, reading the GPS coordinates directly from the sensor and dropping them on to a map can readily create a ‘where’s my phone’ style app. It may be necessary to join static data regarding the user (their home address in order to limit the map scale) and that could be accomplished external to a Stream Processor using a standard table join or it could be accomplished within a Stream Processor.
Expert Rules: Without the use of data science, it may be possible to write rules that give meaning to the inbound stream of data. For example, when combined with the patient’s static data an expert rule might be to summon medical assistance if the patient’s temperature reaches 103°.
Predictive Analytics: The next two applications are both within the realm of data science. Predictive analytics are used by a data scientist to find meaningful information in the data.
Unsupervised Learning: In predictive analytics unsupervised learning means applying techniques like clustering and segmentation that don’t require historical data that would indicate a specific outcome. For example, an accelerometer in your FitBit can readily learn that you are now more or less active than you have been recently, or that you are more or less active than other FitBit users with whom you compare. Joining with the customer’s static data is a likely requirement to give the reading some context.
The advantage of unsupervised learning is that it can be deployed almost immediately after the sensor is placed since no long period of time is required to build up training data.
Some unsupervised modeling will be required to determine the thresholds at which the alerts should be sent. For example, a message might only be appropriate if the period of change was more than say 20% day-over-day, or more than one standard deviation greater than a similar group of users.
These algorithms would be determined by data scientists working from batch data and exported into the Stream Processor as a formula to be applied to the data as it streams by.
Supervised Learning: Predictive models are developed using training data in which the outcome is known. This requires some examples of the behavior or state to be detected and some examples where that state is not present.
For example we might record the temperature, vibration, and power consumption of a motor and also whether that motor failed within the next 12 hours following the measurement. A predictive model could be developed that predicts motor failure 12 hours ahead of time if sufficient training data is available.
The model in the form of an algebraic formula (a few lines of C, Java, Python, or R) is then exported to the Stream Processor to score data as it streams by, automatically sending alerts when the score indicates an impending failure.
The benefits of sophisticated predictive models used in Stream Processing are very high. The challenge may be in gathering sufficient training data if the event is rare as a percentage of all readings or rare over time meaning that much time may pass before adequate training data can be acquired.
Watch for our final installment, Lesson 3.
About the author: Bill Vorhies is Editorial Director for Data Science Central and has practiced as a data scientist and commercial predictive modeler since 2001. He can be reached at:
{kind=link}