
Summary: IBM’s Watson now to do your taxes at H&R Block? This is a good opportunity to explore the differences between Question Answering Machines (Watson) and Expert Systems.
 If you were paying attention during the Super Bowl you saw something unprecedented, an advertisement aimed at data scientists. OK, well almost. It was the H&R Block announcement that it was rolling out IBM’s Watson to all 80,000 of its tax preparers.
If you were paying attention during the Super Bowl you saw something unprecedented, an advertisement aimed at data scientists. OK, well almost. It was the H&R Block announcement that it was rolling out IBM’s Watson to all 80,000 of its tax preparers.
So far we’ve seen Watson deployed primarily on more complex and obscure data like chemical reactions, cancer diagnoses, and environmental engineering. There have been some apps on the very simple end of the scale. Macy’s for example is using it to power a mobile app to answer questions like ‘where are the red dresses’. These simpler applications don’t really seem to tax Watson’s capabilities and the medical and scientific apps are difficult to generalize into everyday business use cases.
What’s particularly interesting about using Watson to do taxes is that it’s a very mainstream business application from a company with a long history of using man-made expert systems. It’s a good example for drawing comparisons with what Watson can and can’t do.
Question Answering Machine Versus Expert Systems
Watson and its competitor products are categorized as Question Answering Machines (QAMs). That’s fundamentally different from search. Search algorithms return a list of resources where an answer may be found. A QAM must return a single answer that is demonstrably the best answer to the question that’s been posed.
That might sound very much like an ‘Expert System’ but there’s a valuable distinction here. Expert Systems have been around for decades. These are basically branching logic programs very much like decision trees designed to lead a user from the beginning of the question to the correct answer by asking a series of intermediate questions answered by the user which guide the branching logic.
Not only is this much less ‘automatic’ than QAMs but the entire branching logic has to be determined by deep subject matter experts and programmed by hand.
Great examples are the tax preparation programs used by many of us from H&R Block (TaxCut) or Intuit (TurboTax). These clearly meet the definition of Expert Systems and importantly, Watson will not replace them. Or at least not yet.
QAM (Watson) Basics
QAMs embody three of the currently most popular capabilities of Artificial Intelligence (AI):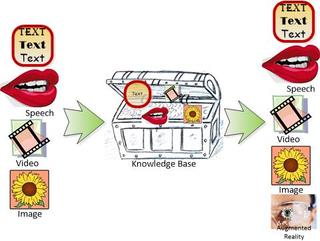
- Image and Video Processing
- Text and Speech Processing
- Knowledge Retrieval
The image and text/speech capabilities enable very user friendly input and output systems for QAMs. It’s in the less well known area of knowledge retrieval that QAMs stand out.
In the most simple terms, QAMs follow these steps:
NLP Input: From the natural language (or image) inputs they must decipher the most accurate meaning of the question posed. This means interpreting all the possible linguistic complexities of phrasing plus mastering any special vocabulary or special syntax unique to the area being trained.
Hypothesis Generation: It’s almost inevitable that the NLP interpretation will have more than one potential meaning and more likely that there will be a dozen or more. The QAM generates a number of hypotheses about what these questions might be then searches the knowledge base to find potential matches for each.
Hypothesis Evaluation: By applying advanced analytics to weight and evaluate a number of potential responses based on only relevant evidence the QAM arrives at the single most likely conclusion.
NLP Output: The QAM must then present the finding using a string of text (or image) that is meaningful to the context of the question and presents the answer.
Evidence Based Learning: Based on feedback from the human user, the QAM can fine tune itself becoming smarter with each iteration and interaction.
What is less obvious from this UX perspective is all the work that went into training the QAM.
Body of Knowledge: Tax law and regulation, both federal and state is a perfect example of a large complex body of data that consistently requires expert interpretation. According to Bill Cobb, H&R Block CEO there are about 74,000 pages of tax code. All of this knowledge must be loaded into Watson and maintained by subject matter experts so that new material is added, but importantly, so that old and contradictory information is removed.
Ingestion: After the corpus of knowledge is loaded, Watson will build a variety of metadata tables and indexes to make retrieval more efficient. It may also build and utilize knowledge graphs.
Training for Understanding: Training the algorithms that evaluate the hypotheses within Watson may be the most difficult part. The QAM developers load a series of questions and answers that are relevant to the body of knowledge. This is not so that Watson can simply parrot these answers back but so that the weighting algorithms can learn what topics typically go together. The volume of training data required is very much like image processing. It may take hundreds of thousands or millions of possible Q&A pairs for the QAM to successfully train. David Kenny, IBM Watson & Cloud Platform SVP explains that there were 600 Million data points created for this project.
Why H&R Block Was Well Positioned to Implement Watson
Two factors worked in their favor:
First, the tax code itself, while voluminous, is already accurately digitized and has for many years been provided with an update service that adds and subtracts material already reviewed by SMEs.
Second, two types of training data were already on hand in large volumes. The first are the millions of already digitized and standardized tax returns that Block has prepared for its customers over recent years. Personally identifying information was of course removed, but each return represents a unique pattern and also contains significant profile data. That includes geo location, type of wage earning activity, marital status, number of dependents, and so forth so that a married professional in New York can be easily discerned from a single accounting manager in Texas. This in turn suggests patterns of deductions associated with these specific profiles.
The second type of training data is actually something that many companies have but don’t think much about. These are the transcripts of the interactions between Block’s preparers and their customer regarding what sort of specific questions or unique issues they had during the preparation of their returns. Many companies have similar data in the form of recorded CSR logs that could also be processed by NLP and used as training input to similar systems.
What Will Watson Actually Do During Tax Preparation
 First off, your tax return will be prepared using Block’s Expert System not by Watson directly. The initial goal of Watson is to try to ensure that no deductions go unnoticed.
First off, your tax return will be prepared using Block’s Expert System not by Watson directly. The initial goal of Watson is to try to ensure that no deductions go unnoticed.
Even professional tax preparers are only human and may occassionally overlook a deduction. Even more likely is that the client failed to mention some element of their financial life that would have suggested a deduction.
The application of Watson at the preparer’s desk starts with the same interview form used for regular tax prep. The preparer is also enabled to ask questions directly of the system. Most specifically, Watson can access not only tax law but also the thousands of returns that look most like the client sitting there which may suggest additional questions the preparer should ask.
What Watson is not designed to do, or at least at this point, is to suggest the more arcane or elaborate tax reduction strategies that might be applicable. If the client does not suggest, or if the preparer does not ask, then Watson cannot answer. It’s a tool to avoid omission, not to invent new tax strategy.
It is however one more major step that AI takes into our day-to-day lives and allows us to become more comfortable with this augmented human intelligence.
About the author: Bill Vorhies is Editorial Director for Data Science Central and has practiced as a data scientist and commercial predictive modeler since 2001. He can be reached at:
{kind=link}