

No matter how intelligent and sophisticated your technology is, what you ultimately need for Big Data Analysis is data. Lots of data. Versatile and coming from many sources in different formats. In many cases, your data will come in a machine-readable format ready for processing — data from sensors is an example. Such formats and protocols for automated data transfer are rigidly structured, well-documented and easily parsed. But what if you need to analyze information meant for humans? What if all you have are numerous websites?
This is the place where data scraping, or web scraping steps in: the process of importing information from a website into a spreadsheet or local file saved on your computer. In contrast to regular parsing, data scraping processes output intended for display to an end-user, rather than as input to another program, usually neither documented nor structured. To successfully process such data, data scraping often involves ignoring binary data, such as images and multimedia, display formatting, redundant labels, superfluous commentary, and other information which is doomed irrelevant.
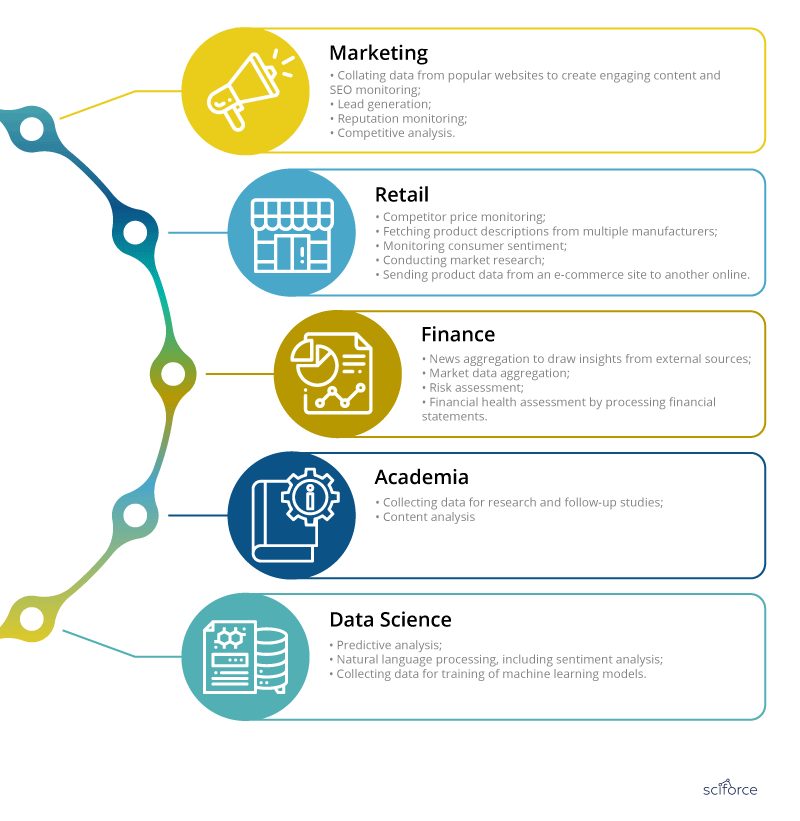
Applications of Data Scraping
When we start thinking about data scraping the first and irritating application that comes to mind is email harvesting — uncovering people’s email addresses to sell them on to spammers or scammers. In some jurisdictions, it is even made illegal to use automated means like data scraping to harvest email addresses with commercial intent.
Nevertheless, data scraping applications are numerous and it may be useful in every industry or business:
Data Scraping Tools
The basic — and easiest — way to data scrape is to use dynamic web queries in Microsoft Excel, or install the Chrome Data Scraper plugin. However, for more sophisticated data scraping, you need other tools.
Here we share some of the top data scraping tools:
1. Scraper API
Scraper API is a tool for developers building web scrapers. It handles proxies, browsers, and CAPTCHAs so developers can get the raw HTML from any website with a simple API call.
Pros:
It manages its own and impressive internal pool of proxies from a dozen proxy providers, and has smart routing logic that routes requests through different subnets and automatically throttles requests in order to avoid IP bans and CAPTCHAs, so you don’t need to think about proxies.
Drawback:
Pricing starts from $29 per month.
2. Cheerio
Cherio is the most popular tool for NodeJS developers who want a straightforward way to parse HTML.
Pros:
- Cheerio offers an API similar to jQuery, so developers familiar with jQuery will have no difficulties with it.
- It offers many helpful methods to extract text, html, classes, ids, and more.
Drawback:
Cheerio (and ajax requests) is not effective in fetching dynamic content generated by javascript websites.
3. Scrapy
Scrapy is the most powerful library for Python. Among its features is HTML parsing with CSS selectors, XPath or regular expressions or any combination of the above. It has an integrated data processing pipeline and provides monitoring and extensive logging out of the box. There’s also a paid service to launch Scrapy spiders in the cloud.
Pros:
- Scrapy has multiple helpful features and highly customizable settings.
- It is easy to extend.
Drawback:
- In the free version, you still have to manage proxies, CAPTCHAs and JS rendering by yourself.
- Documentation can be confusing.
4. Beautiful Soup
Sometimes Scrapy is an overkill for simple HTML parsing. In such cases, Beautiful Soup is a good choice. It is intended for Python developers who want an easy interface to parse HTML. Like Cheerio for NodeJS developers, Beautiful Soup is one of the most popular HTML parsers for Python.
Pros:
- It is easy to use even for inexperienced developers;
- It is ex tremely well documented, with many tutorials on using it to scrape various website in both Python 2 and Python 3.
Drawback:
- Beautiful Soup does not support web crawling with only HTML parser included.
- The performance of the built-in html.parser is rather poor, though it can be solved by integration of Beautiful Soup with the lxml library.
5. ParseHub
Parsehub is a powerful tool for building web scrapers without coding, so it can be used by analysts, journalists, academicians and everyone interested. It has many features such as automatic IP rotation, allowing scraping behind login walls, going through dropdowns and tabs, getting data from tables and maps, and more.
Pros:
- It is extremely easy to use: you click on the data and it is exported in JSON or Excel format.
- It has a generous free tier, that allows users to scrape up to 200 pages of data in just 40 minutes.
Drawback:
Of course, it is not the best option for developers as it requires additional steps to import its output and does not provide the usual flexibility.

Bonus: Diffbot
Diffbot is different from most web scraping tools, since it uses computer vision instead of html parsing to identify relevant information on a page. In this way, even if the HTML structure of a page changes, your web scrapers will not break as long as the page looks the same visually.
Pros:
Thanks to its relying on computer vision, it is best suited for long running mission critical web scraping jobs.
Drawback:
For non-trivial websites and transformations you will have to add custom rules and manual code.
Like all other aspects of Data Science, data scraping evolves fast, adding machine learning to recognize inputs which only humans have traditionally been able to interpret — like images or videos. Coupled with text-based data scraping it will turn the world of data collection upside down.
Meaning that whether or not you intend to use data scraping in your work, it’s high time to educate yourself on the subject, as it is likely to go to the foreground in the next few years.
{kind=link}