
Introduction
Are you looking to learn python for data science but have a time crunch? Are you making your career shift into data science and want to learn python? In this blog, we will talk about learning python for data science in just 30 days. Also, we will look at weekly schedules and topics to cover in python.
Before directly jumping to python, let us understand about the usage of python in data science.
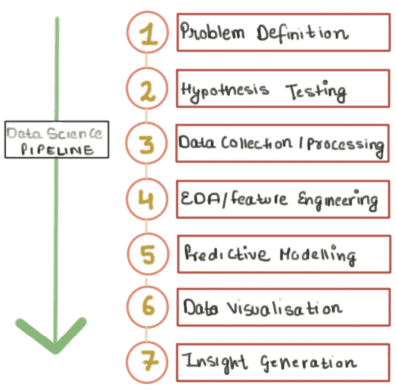
Data Science Pipeline
Data science is a multidisciplinary blend of data inference, algorithm development, and technology in order to solve analytically complex problems. It provides solutions to real-world problems using data available. But, data analysis is not a one-step process. It is a group of multiple techniques employed to reach a suitable solution for a problem. Also, a data scientist may need to go through multiple stages to arrive at some insights for a particular problem. This series of stages collectively is known as a data science pipeline. Let us have a look at various stages involved.
Click on picture to zoom in
Stages
-
Problem Definition
Contrary to common belief, the hardest part of data science isn’t building an accurate model or obtaining good, clean data. It is much harder to define feasible problems and come up with reasonable ways of measuring solutions. Problem definition aims at understanding, in depth, a given problem at hand. Multiple brainstorming sessions are organized to correctly define a problem because of your end goal with depending upon what problem you are trying to solve. Hence, if you go wrong during the problem definition phase itself, you will be delivering a solution to a problem which never even existed at first
-
Hypothesis Testing
Hypothesis testing is an act in statistics whereby an analyst tests an assumption regarding a population parameter. The methodology employed by the analyst depends on the nature of the data used and the reason for the analysis. Hypothesis testing is used to infer the result of a hypothesis performed on sample data from a larger population. In simple words, we form some assumptions during problem definition phase and then validate those assumptions statistically using data.
-
Data collection and processing
Data collection is the process of gathering and measuring information on variables of interest, in an established systematic fashion that enables one to answer stated research questions, test hypotheses, and evaluate outcomes. Moreover, the data collection component of research is common to all fields of study including physical and social sciences, humanities, business, etc. While methods vary by discipline, the emphasis on ensuring accurate and honest collection remains the same. Furthermore, Data processing is more about a series of actions or steps performed on data to verify, organize, transform, integrate, and extract data in an appropriate output form for subsequent use. Methods of processing must be rigorously documented to ensure the utility and integrity of the data.
-
EDA and feature Engineering
Once you have clean and transformed data, the next step for machine learning projects is to become intimately familiar with the data using exploratory data analysis (EDA). EDA is about numeric summaries, plots, aggregations, distributions, densities, reviewing all the levels of factor variables and applying general statistical methods. A clear understanding of the data provides the foundation for model selection, i.e. choosing the correct machine learning algorithm to solve your problem. Also, Feature engineering is the process of determining which predictor variables will contribute the most to the predictive power of a machine learning algorithm. The process of feature engineering is as much of an art as a science. Often feature engineering is a give-and-take process with exploratory data analysis to provide much-needed intuition about the data. It’s good to have a domain expert around for this process, but it’s also good to use your imagination.
-
Modelling and Prediction
Machine learning can be used to make predictions about the future. You provide a model with a collection of training instances, fit the model on this data set, and then apply the model to new instances to make predictions. Predictive modelling is useful for startups because you can make products that adapt based on expected user behaviour. For example, if a viewer consistently watches the same broadcaster on a streaming service, the application can load that channel on application startup.
-
Data Visualisation
Data visualization is the process of displaying data/information in graphical charts, figures, and bars. It is used as a means to deliver visual reporting to users for the performance, operations or general statistics of data and model prediction.
-
Insight generation and implementation
Interpreting the data is more like communicating your findings to the interested parties. If you can’t explain your findings to someone believe me, whatever you have done is of no use. Hence, this step becomes very crucial. Furthermore, the objective of this step is to first identify the business insight and then correlate it to your data findings. Secondly, you might need to involve domain experts in correlating the findings with business problems. Domain experts can help you in visualizing your findings according to the business dimensions which will also aid in communicating facts to a non-technical audience.
Python usage in different data science stages
After having a look at various stages in a data science pipeline, we can figure out the usage of python in these stages. Hence, we can now understand the applications of python in data science in a much better way.
To begin with, stages like problem definition and insight generation do not require the use of any programming language as such. Both the stages are more based on research and decision making rather than implementation through code.
-
Python in data collection
Many data science projects require scraping websites to gather the data that you’ll be working with. The Python programming language is widely used in the data science community, and therefore has an ecosystem of modules and tools that you can use in your own projects.
-
Python in hypothesis testing
Hypothesis testing requires a lot of statistical knowledge and implementation. Python has libraries which can help users to perform statistical tests and computations easily. Using these libraries, like SciPy, can easily allow users to automate hypothesis testing tasks.
-
Python in EDA
Multiple libraries are available to perform basic EDA. You can use pandas and matplotlib for EDA. Pandas for data manipulation and matplotlib, well, for plotting graphs. Jupyter Notebooks to write code and other findings. Jupyter notebooks are kind of diary for data analysis and scientists, a web-based platform where you can mix Python, HTML, and Markdown to explain your data insights.
-
Python in Visualisation
One of the key skills of a data scientist is the ability to tell a compelling story, He should be able to visualize data and findings in an approachable and stimulating way. Also, learning a library to visualize data will also enable you to extract information, understand data and make effective decisions. Furthermore, there are libraries like matplotlib, seaborn which makes it easy for users to build pretty visualizations. Additionally, these libraries are easy to learn in not much time.
-
Python in modelling and prediction
Python boasts of libraries like sci-kit-learn which is an open source Python library that implements a range of machine learning, pre-processing, cross-validation and visualization algorithms using a unified interface. Such libraries abstract out the mathematical part of the model building. Hence, developers can focus on building reliable models rather than understanding the complex math implementation. If you are new to machine learning, then you can follow this link to know more about it.
Study Timeline
In this section, we will be looking at a week-wise distribution of python topics. This will help you in organizing your schedule and have a dedicated roadmap for 30 days

Click on picture to zoom in
Week 1
- Python Basics
Start with python basics here. You can start learning about variables and control flow. Then you can focus on learning about strings, dictionaries, tuples and other data structures in python.
Reference Links - Python Advanced
Once you are done with basic concepts, you can focus on concepts like multithreading, classes, and objects, regular expressions and networking etc. All these concepts may not be very much required at most of the times but it is something good to know.
Reference Links
Follow the link to get started with python basic and advanced.
Week 2
- Web scraping in python
It refers to gathering data from websites using a code, which is one of the most logical and easily accessible sources of data. Automating this process with a web scraper avoids manual data gathering, saves time and also allows you to have all the data in the required structure. You can start learning about libraries like BeatifulSoup and Scrapy. The libraries in python provide users with functionality to scrape data from websites. Having familiarity with these libraries will help you in utilizing python capabilities in data collection. - Pandas, numPy and SciPy in python
Python has its own set of libraries to deal with data management. Library-like Pandas allow you to access data in form of a data frame. This facilitates users with the ability to handle data with complex structures and perform numerical operations on them like data cleaning, data summarization etc. But, numPy is more about handling numerical methods and sciPy about scientific and statistical functions to perform math heavy calculations. These libraries are must to know when you are learning python for data science. Hence, a great deal of attention should be paid while learning these libraries. You can have a look at this link to learn more about above-mentioned libraries.
Week 3
Week 3 is about understanding the machine learning capabilities of python and getting fluent with it
-
Scikit-learn Package
Week 3 starts with understanding the machine learning capabilities in python. Scikit-learn is the must know package whenever we talk about machine learning and python. Invest your time in learning the methods provided by the scikit-learn package. It provides a uniform way of fitting different models and hence is a great hit among python based ml developers.
-
Keras
Theano and TensorFlow are two of the top numerical platforms in Python that provide the development in deep-learning. Both are very powerful libraries, but both can be difficult to use directly for creating deep learning models. Hence Keras Python library, which provides a clean and convenient way to create a range of deep learning models on top of Theano or TensorFlow. Keras is a minimalist Python library for deep learning that can run on top of Theano or TensorFlow. It was developed to make implementing deep learning models as fast and easy as possible for research and development. It runs on Python 2.7 or 3.5.
Week 4
Week 4 is more about learning visualizations in python and summarising all the previous learning in the form of a project.
-
Matplotlib in python
Matplotlib is a Python 2D plotting library which produces publication quality figures in a variety of hardcopy formats and interactive environments across platforms. Additionally, It can be used in Python scripts, the Python and IPython shells, the Jupyter notebook, web application servers, and four graphical user interface toolkits. Also, it tries to make easy things easy and hard things possible. Furthermore, you can generate plots, histograms, power spectra, bar charts, error charts, scatterplots, etc., with just a few lines of code. For examples, see the sample plots and thumbnail gallery.
-
Project
After learning most of the things about python for data science, it is time to wrap up all your learnings together in the form of a project. A project will help you to actually implement all your learnings together and visualize a complete picture of the data science pipeline.
A sample project to finish with
You are free to pick up any project you like. In case you are confused and do not know what to take up as a project, you can start with the Titanic problem on the Kaggle. You can find the problem statement here. I will not tell you how to solve it but can give you a few pointers in kickstarting your project
- Do not go for the score on Kaggle. The aim is to complete the project and not to go for an extensive model fitting
- Do more of EDA and data processing rather than model building
- Focus on data processing using libraries you learned (pandas, numpy)
Conclusion
Python is an amazingly versatile programming language. Apart from data science, you can use it to build websites, machine learning algorithms, and even autonomous drones. A huge percentage of programmers in the world use Python, and for good reason. Hence, it is worthwhile to invest in your time in learning python if you are moving into data science. With a plethora of libraries available, python will always have an edge over other languages. Python is a really fun and rewarding language to learn. Also, I think that anyone can get to a high level of proficiency in it if they find the right motivation. Happy Learning!
{kind=link}