
Of course, OpenAI, Mistral, Claude and the likes may adapt. But will they manage to stay competitive in this evolving market? Last week Databricks launched DBRX. It clearly shows the new trend: specialization, lightweight, combining multiple LLMs, enterprise-oriented, and better results at a fraction of the cost. Monolithic solutions where you pay by the token encourage the proliferation of models with billions or trillions of tokens, weights and parameters. They are embraced by companies such as Nvidia, because they use a lot of GPU and make chip producers wealthy. One of the drawbacks is the cost incurred by the customer, with no guarantee of positive ROI. The quality may also suffer (hallucinations).
In this article, I discuss the new type of architecture under development. Hallucination-free, they achieve better results at a fraction of the cost and run much faster. Sometimes without GPU, sometimes without training. Targeting professional users rather than the layman, they rely on self-tuning and customization. Indeed, there is no universal evaluation metric: laymen and experts have very different ratings and expectations when using these tools.
Much of this discussion is based on the technology that I develop for a fortune 100 company. I show the benefits, but also potential issues. Many of my competitors are moving in the same direction.
Questioning the GenAI Startup Funding Model
Before diving into the architecture of new LLMs, let’s first discuss the current funding model. Many startups get funding from large companies such as Microsoft, Nvidia or Amazon. It means that they have to use their cloud solutions, services and products. The result is high costs for the customer. Startups that rely on vendor-neutral VC funding face a similar challenge: you cannot raise VC money by saying that you could do better and charge 1000x less. VC firms expect to make billions of dollars, not mere millions. To maintain this ecosystem, players spend a lot of money on advertising and hype. In the end, if early investors can quickly make big money through acquisitions, it is a win. What happens when clients realize ROI is negative, is unimportant. As long as it does not happen too soon! But can investors even achieve this short-term goal?
The problem is compounded by the fact that researchers believe deep neural networks (DNN) are the panacea, with issues simply fixed by using bigger data, multiple transforms to make DNN work, or front-end patches such as prompt engineering, to address foundational back-end problems. Sadly, no one works on ground-breaking innovations outside DNNs. I am an exception.
In the end, very few self-funded entrepreneurs can compete, offering a far less expensive alternative with no plan on becoming a billionaire. I may be the only one able to survive and strive, long-term. My intellectual property is open-source, patent-free, and comes with extensive documentation, source code, and comparisons. It appeals to large, traditional corporations. The word is out; it is no longer a secret. In turn, it puts pressure on big players to offer better LLMs. They can see how I do it and implement the same algorithms on their end. Or come up with their own solutions independently. Either way, the new type of architecture is pretty much the same in all cases, not much different from mine. The new Databricks LLM (DBRX) epitomizes this trend. Mine is called XLLM.
Surprisingly, none of the startups working on new LLMs consider monetizing their products via advertising: blending organic output with sponsored results relevant to the user prompt. I am contemplating doing it, with a large client interested in signing-up when the option is available.
The New Breed of LLMs in One Picture
As concisely stated by one of my clients, the main issues to address are:
- Latency
- Accuracy and relevance
- Cost
- Liability (avoid data leakage, costly hallucinations)
In addition to blending specialized LLMs (one per top category with its own set of embeddings and other summary tables) a new trend is emerging. It consists of blending multiple LLMs focusing on the same topic, each one with its own flavor: technical, general, or based on different parameters. Then, combining these models just like XGBoost combines multiple small decisions trees to get the best from all. In short, an ensemble method.
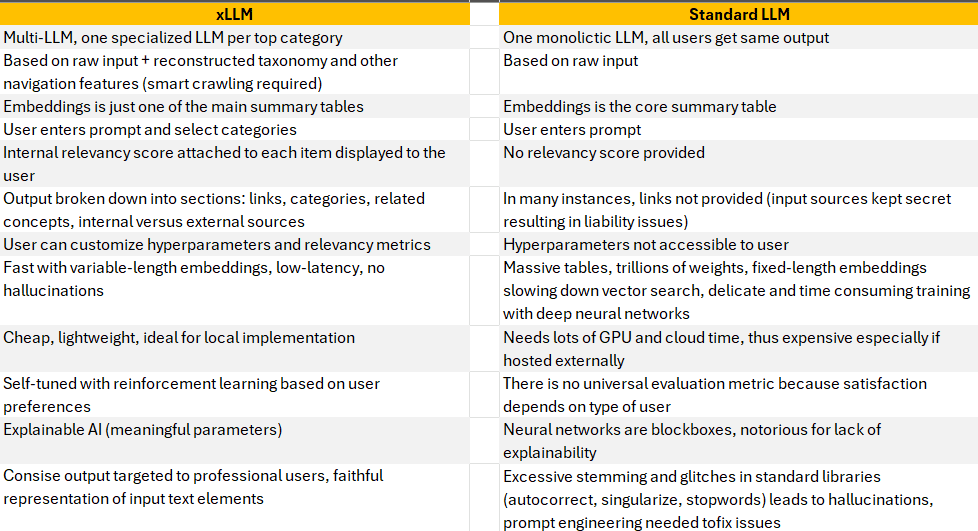
Note that speed and accuracy result from using many small, specialized tables (embeddings and so on) as opposed to a big table with long, fixed-size embedding vectors and expensive semantic / vector search. The user selects the categories that best match his prompt. In my case, there is no neural network involved, no GPU needed, yet no latency and no hallucinations. Liability is further reduced with a local implementation, and explainable AI.
Carefully selecting input sources (in many cases, corporate repositories augmented with external data) and smart crawling to reconstruct the hidden structure (underlying taxonomy, breadcrumbs, navigation links, headings, and so on), are critical components of this architecture.
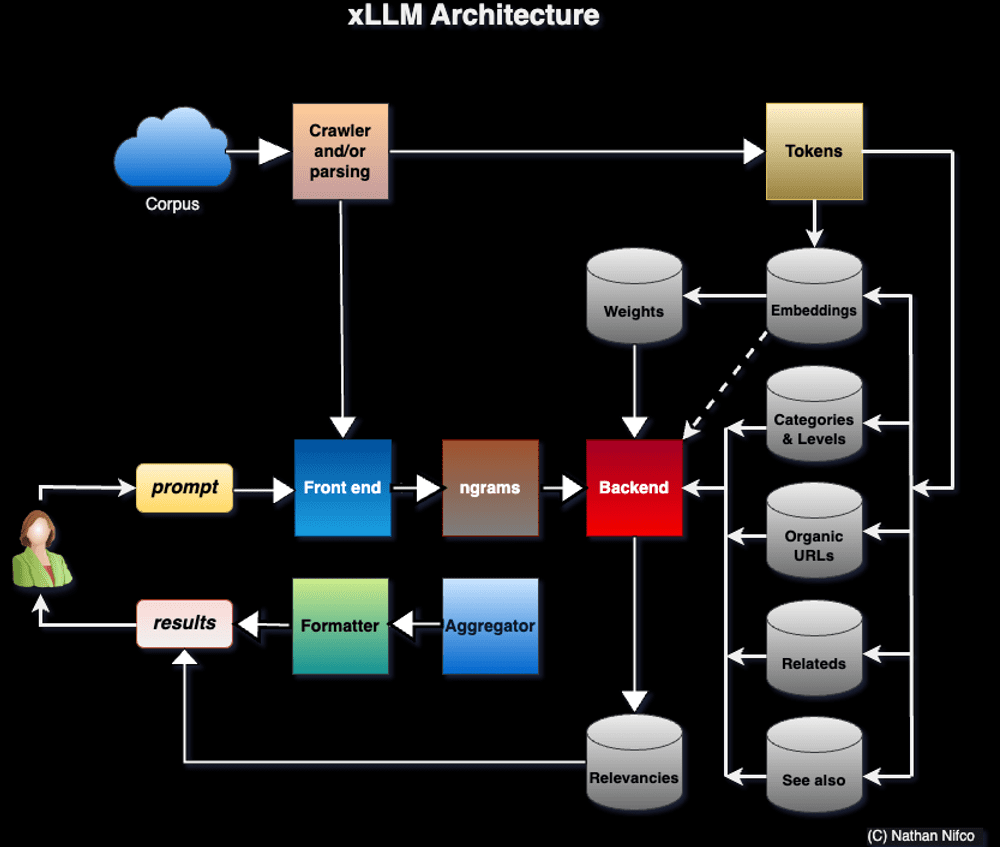
For details about xLLM (technical implementation, comparing output with OpenAI and the likes on the same prompts, Python code, input sources, and documentation), see here. I also offer a free course on the topic, here.
Author

Vincent Granville is a pioneering GenAI scientist and machine learning expert, co-founder of Data Science Central (acquired by a publicly traded company in 2020), Chief AI Scientist at MLTechniques.com and GenAItechLab.com, former VC-funded executive, author (Elsevier) and patent owner — one related to LLM. Vincent’s past corporate experience includes Visa, Wells Fargo, eBay, NBC, Microsoft, and CNET. Follow Vincent on LinkedIn.
{kind=link}