
Unlike traditional application programming, where API functions are changing every day, database programming basically remains the same. The first version of Microsoft Visual Studio .NET was released in February 2002, with a new version released about every two years, not including Service Pack releases. This rapid pace of change forces IT personnel to evaluate their corporation’s applications every couple years, leaving the functionality of their application intact but with a completely different source code in order to stay current with the latest techniques and technology.
The same cannot be said about your database source code. A standard query of SELECT/FROM/WHERE/GROUP BY, written back in the early days of SQL, still works today. Of course, this doesn’t mean there haven’t been any advancements in relational database programming; there were, and they’ve been more logical than technical.

Starting from the days when Bill Inmon and Ralph Kimball published their theories on data warehouse design, the advancements in database programming have been focused on preventing loss of valuable information and extracting all valuable information from the data. Once Inmon and Kimball introduced the database world to data warehousing, major changes were made to ETL (Extract/Transform/Load) tools that gave database developers easy access to metadata, and data from non-relational database sources, which was difficult to work with in the past. This increased the amount of data available from which to extract valuable information, and this increase in available data led to advancements in data processing through OLAP cubes and data mining algorithms.
Adding a data warehouse, OLAP cubes, and data mining algorithms to your database architecture can dramatically streamline business processes and illuminate patterns in your data that you otherwise would have never known existed. Automation can also have a profound impact on business intelligence capabilities.
However, before you start adding new tools and technologies, you should make sure that the transaction database is built properly.
Transaction Database
The transaction database is the foundation, and if your transaction database is not reliable and accurate, then adding anything on top is a recipe for disaster.
An important point to keep in mind when adding additional layers to your database is that all projects need to show a return on investment, which is why it’s best to get the most out of your current architecture before adding further layers. All these layers utilize data originating from a transaction database. In many situations you can get the same output by simply querying your transaction database. Of course, having all your reports reading from a data warehouse or OLAP cube is the ideal method, but when an organization is not ready for that level of complexity, it’s more important that its reporting needs are met first. Once basic reporting needs are met, it’s much easier to begin a discussion on how a proper data warehouse, and possibly an OLAP cube, can benefit its business.
Nearly every programmer knows the three rules of database normalization. The stored procedures reading from the transaction database are the path to optimization. The issues to look for are readability, multiple calls to the same database table, and unnecessary usage of variables.
All elite database programmers are picky about the readability of their stored procedures. There are a few commonalities in the way database professionals format their queries, which is different from an application developer. Typically, keywords and aggregate functions are in caps, while table and field names use either camelcase or underscores. Table aliases have some correlation to the actual table name. The alignment of the sections of the stored procedure have some type of block pattern.
Below is an example of a query that utilizes a readable format.
SELECT c.customer_id, c.name, SUM (po.purchase_amount) total_purchase_amount FROM customer c JOIN purchase_orders po ON c.customer_id = po.customer_id GROUP BY c.customer_id, c.name The next thing to look for is if a query hits a table more than once. In most queries a table only needs to be accessed once, excluding the rare times you need to aggregate another aggregate function. This is another mistake that some application programmers make, perhaps because an application programmer thinks in terms of object-oriented design.
Object-oriented design creates separate objects for each unique data element, but a database programmer needs to think in terms of set logic. Just because a query accesses a table more times than is needed doesn’t mean that the query is producing inaccurate data, however the performance of the query is effected.
Another concern is dropped, or duplicated, records every time you have a join, compromising the accuracy of your query. Unnecessary usage of variables is yet another sign that a query was developed by an application developer. Application developers use variables throughout their code while a query very rarely needs to use variables except when declared as a parameter to the stored procedure. Once again it is a sign that the developer was not thinking in the terms of set logic.
ETL (Extract Transform Load) And Reporting
Once a client’s transaction database has properly functioning queries, the next step is to streamline business processes.
The easiest way to identify a business’s need for ETL processes or automated reporting is to find out who is reading data from a transaction database and then manipulating the data using a spreadsheet. A spreadsheet is the same structure as a database table. Both contain rows and columns. If you have end-users manipulating data on their own, you should ask yourself, “Why can’t that process be automated?”
Automating business processes provides an immediate return on investment and should always be considered before moving on to more expensive projects, such as data warehousing. Identifying end-users manipulating data via a spreadsheet may sound simple but there is a caveat to this process.
Developers like to automate processes; it’s what they do. End-users don’t necessarily like automated processes, especially if they threaten their job. So, don’t be naive and think that end-users are going to run up to you and identify daily tasks that can be automated. You really need to take the lead in identifying streamlining opportunities.
A well-built ETL system should also provide the ability to backtrack all the data loaded in a transaction database back to the original source file. This is a critical piece of the database architecture. If you don’t know the exact date/time of when each record was added, along with the name of the source (username or filename) that added the records, then you are not prepared to handle bad data loaded into your transaction database. You should ask yourself, “What if somebody sends us a bad file?” How long would it take you to identify the records that came from it?
Data Warehouse
There are two theories to data warehouse design. The difference between the Inmon and Kimball theories can be summarized as follows:
The Inmon theory is to first develop a data warehouse and then build dimensional data marts for reporting from the data warehouse. The Kimball theory is to first develop dimensional data marts for reporting and then merge them together to create the data warehouse.
You always want to provide clients the fastest return on investment. Building data marts is a simple process. You start by taking the queries behind your reports and change them from returning result sets to storing the result sets in permanent tables. You simply add TRUNCATE TABLE tablename; INSERT INTO tablename before the original SELECT keyword. Once you have a few functional data mart tables, identifying opportunities to merge the data marts should fall into place; look for report queries that use the same list of tables and then merge the list of fields. This requires a more complicated query, especially when the list of tables increases. However, as long as you are thoroughly testing the query, each incremental change can be made without a disruption to normal business processes.
Each time you make an enhancement to a Kimball data warehouse design, you have an opportunity to show a ROI to the client. That is because the data warehouse is built first and the reporting data marts are built from a static data warehouse. Therefore, you incur the majority of your costs early in the data warehouse project.
OLAP Cube
An OLAP cube may benefit an organization by providing aggregate data with a quick response time, ad-hoc drill down capabilities for end-users, and data mining. When you have a proper OLAP cube, you can extract every bit of value out of your data. An OLAP cube is built on top of a data warehouse, but it uses a different language, MDX, than a standard database SQL. It also requires a more involved configuration effort than a database server. That complexity makes an OLAP project expensive, plus it is difficult to find experienced MDX developers.

Data architects sometimes see existing OLAP cubes with nothing more than a simple dashboard utilizing the cube, without a single process that could not be replaced by an SQL query, data warehouse, or canned report. An OLAP cube can provide a faster response time than a canned report but in most situations the difference is negligible. You can also benefit from the drill down capabilities, however, before providing end-users drill down capabilities, it’s a good idea to use canned reports that provide a similar ad hoc interface.
This allows you to record the ad hoc queries that end-users are running, then you can identify new canned reports that end-users didn’t realize could be created. Since both response time and drill down improvements are usually minimal when developing an OLAP cube, it’s not necessary to suggest it to a client until they need a database architecture that can handle involved data mining. This is when you can really impress clients and show them something about their business that they might never have known without a robust database architecture.
As previously mentioned, building an OLAP cube can be challenging. It’s good policy to consider a hybrid OLAP cube. Microsoft Excel’s PowerPivot provides easy-to-use data mining tools without the complexity of a full blown OLAP cube. The main disadvantage of a hybrid is that it does not have the same response time. However, a big advantage is that it’s easier to create data mining reports using Excel compared to using MDX. When data mining,there are three reports that are useful. We can look at some real world examples and how to interpret them.
All of these reports are from an automated day trading application constructed by the author.
Visual Reporting
Scatter Plot Report
A scatter plot report is a detail level report that compares two variables. Adding color and size to the actual dots helps visualize the actual outcomes in relation to those variables.
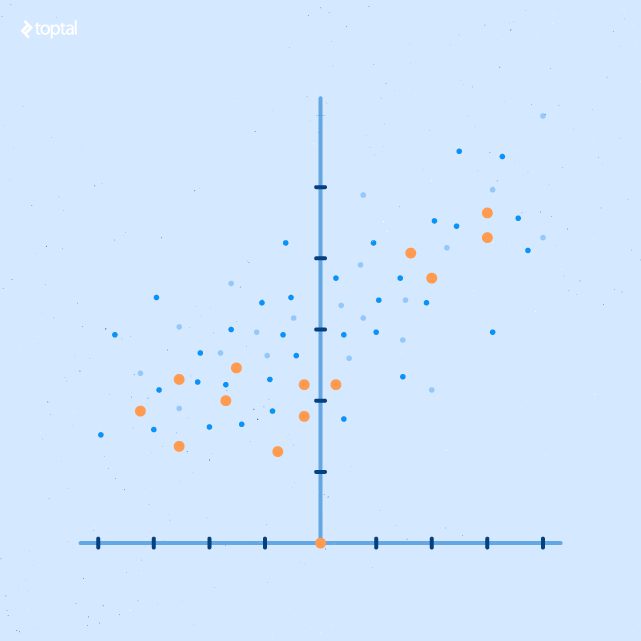
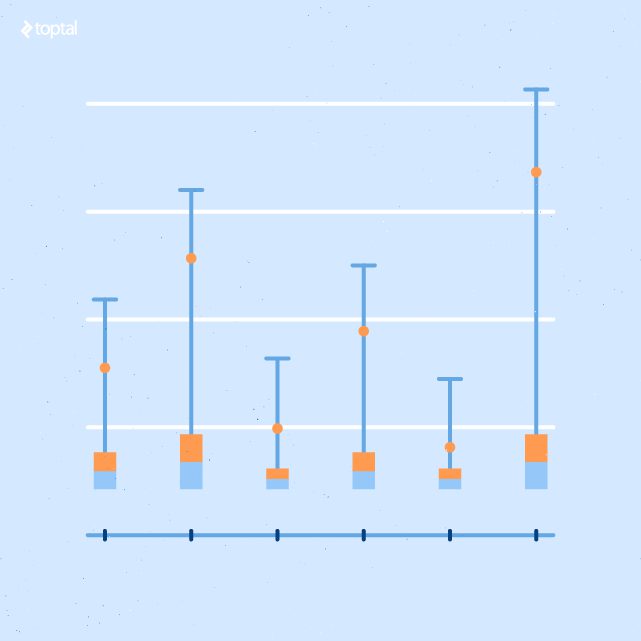
Box and Whiskers Report
This report summarizes the x and y values from the scatter plot report. The x axis values are discretized into a set of buckets.
The ends of each whisker (line) represents the outliers. The yellow and light blue bars represent the upper and lower one standard deviation ranges.
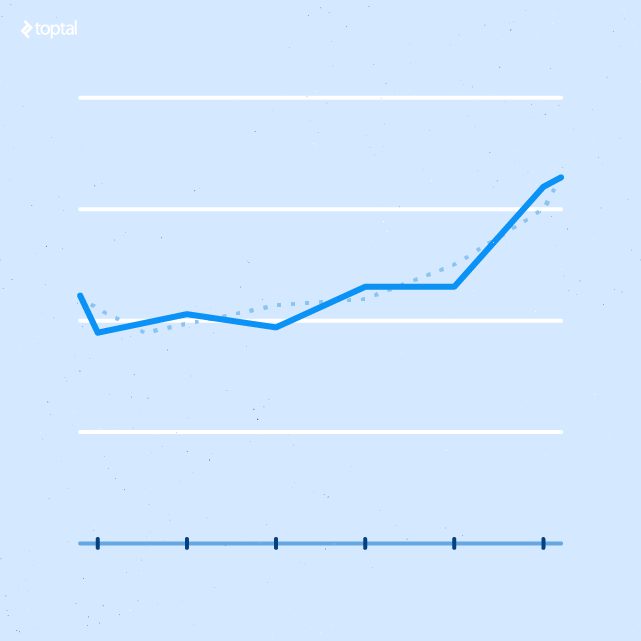
Linear Regression Model
This report shows the correlation between the x and y axis values, along with a smoothing of the line, which can be represented by a mathematical formula. The R squared value is included to show how reliable the correlation is.
Conclusion
As your company grows, typically your database will grow too.
Most organizations do not initially need a database professional. Instead, they have their IT staff handle multiple responsibilities or, as the saying goes, “wear many hats”. This works to a certain point , but eventually, you need to bring in specialists.
The items listed in this document are a quick and easy way to identify database issues you may not have been aware of. Hopefully, it also covered how you can build top notch data mining tools without spending a lot on expensive software licenses. This way you will get a better idea of how much your organization could benefit by adding a database professional to your IT staff.
Originally appeared in Toptal Engineering blog: https://www.toptal.com/database/data-mining-guide
{kind=link}