
Connecting the dots for a Deep Learning App … Our day to day activities is filled with Emotions and Sentiments. Ever wondered how we can identify these sentiments through computers? Oops, computers who have no brains :)? Try this Deep Learning App yourself (refresh a couple of times initially if there’s Application Error):
Dot 0: Deep Learning in Sentiment Analysis
Sentiment analysis is a powerful application which extends its arms to the following fields in the modern day world.
- Movie Reviews — More than 60% of the people check online reviews of a movie and then decide to watch it.
- Restaurant Reviews — Have you ever visited a restaurant without reading a review?
- Product Reviews — Many B2B or B2C products are sold based on the reviews they generate.
- Feature Reviews — Any product’s success is directly proportional to its features’ reviews.
- Political Reviews — Political parties and candidates are chosen based on the fact of how they fare in their reviews.
- Customer Support Reviews — Impressive products fail due to bad support reviews. Alternately simple products take off with good reviews.
- Blog Reviews — Waiting for your comments and reviews on this blog to learn the sentiment!!!
- What is Sentiment Analysis?
According to Wikipedia: Sentiment analysis (sometimes known as opinion mining or emotion AI) refers to the use of natural language processing, text analysis, computational linguistics, and biometrics to systematically identify, extract, quantify, and study affective states and subjective information. On this note, let’s develop a Movie Review Sentiment Application using the methods of Deep Learning.
What is Deep Learning?
Deep learning is an advanced field of machine learning and a step towards the bigger subject of Artificial Intelligence. Currently, it’s creating waves in the field of Image processing, Natural Language Processing, Speech Processing, Video Processing etc. Here we will talk about how to connect the various dots to complete a Deep Learning App. Before we head out to connect the dots lets equip ourselves with few definitions and concepts which will be useful.The dataset which will be used for any prediction task should be first analyzed for the following key points before even diving into solving the same.
- How good are the labels?
- Can we do spot checking of few data points?
- How big is the dataset?
Once we pass this basic hurdle, the big process in any Data Scientist’s life comes into the picture.
Dot 1: Data Preparation
Preparing and cleaning data is currently the bulk of the Data Science work. Believe me, it is 100% true. Movie Review Sentiment App uses a customized data-set of numerous movie reviews from various different sources like IMDB, UCI, Cornell dataset etc The process of making a gold data-set(Prepared data-set for prediction) is a step by step process of Data Collection, Data Cleaning, Data Normalization after which the data can be termed as a gold data-set for the prediction process.

Dataset preparation process
Once we have the Gold Dataset which is nothing but prepared data set for prediction, we are ready for modeling.
Dot 2: Baseline Model
The first architecture in any Deep Learning Analysis is to start always with a single hidden layer architecture thanks to Prof. Jeremy Howard and Prof. Rachel Thomas who insists to start simple for training any Deep Models. This simple yet powerful architecture acts as our baseline !!! The following are the steps employed in training our Sentiment Analysis (Natural Language Processing) pipeline:
- Tokenizer: Each review is broken into a set of tokens called as words.This can be done using keras text tokenizer.
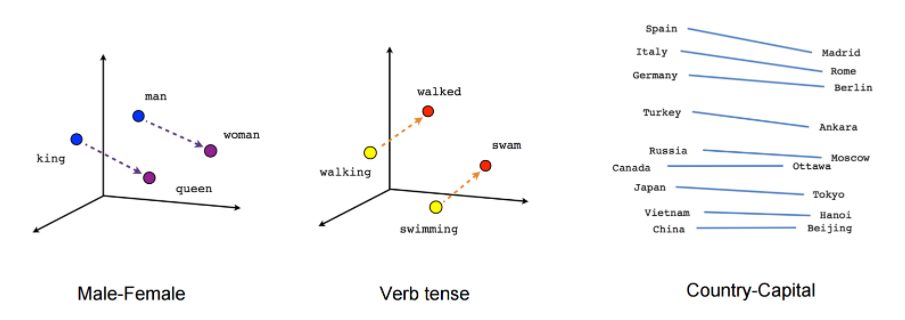
- Embeddings: There are various ways to encode these words into vectors (vectorization) and here, in this case, we will use default keras embeddings as the starting point. Although final model uses efficient pre-trained word2Vec embeddings which capture semantic information of the words and their relationship with other words.
 Courtesy: Tensorflow word2vec
Courtesy: Tensorflow word2vec- Review Encoding: These word embeddings capture the semantic relationship between words. We then need to come up with an encoding of whole movie review so that this can be passed as training data. The simplest ploy is to sum the individual word encodings to form review encoding.
- Predictions: These review encoding is then passed through a single hidden fully connected neural network layer of 300 neurons which looks like below:
- Single Hidden Layer with BatchNormalization
- Single Hidden Layer with BatchNormalization
 Courtesy: Tensorflow word2vec
Courtesy: Tensorflow word2vec Single Hidden Layer with BatchNormalization
Single Hidden Layer with BatchNormalizationDot 3: Experimentation of Different Model Architectures
Once we have the baseline we can start improving our model objective such as accuracy. There was a lot of experiments conducted in order to improve the accuracy of the Sentiment App: Below table provides the summary of models tried and tested.
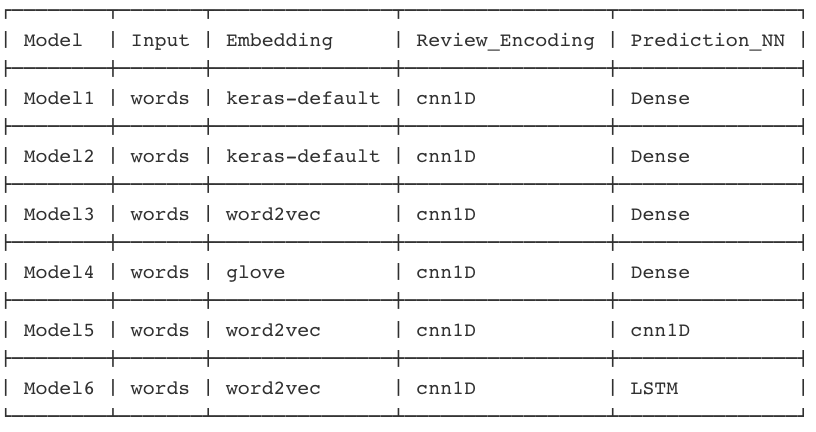
Different Model Architectures experimentation
Dot 4: CNN-GRU Architecture
Many of you might be wondering, Convolution Neural Networks(CNN’s) works great with images but how does it fare with text. In fact, CNN’s have a lot of advantages in training NLP models due to their faster training time and when accurately tuned, they become a deadly tool to train text data as well. Here we have used CNN’s to capture the local and deep relationship between the words for our review encoding, where the idea is taken from “Convolutional Neural Networks for Sentence Classification”(Kim, 2014). Since movie reviews can be few long sentences, long term dependencies need to be captured effectively. In this regard, two options come to mind namely LSTM(Long Short Term Memory Neural Networks) and GRU(Gated Recurrent Neural Networks). Good way to understand both these networks is to head to http://colah.github.io/ In our experiments, GRU performed better than LSTM in terms of training speed and also accuracy. Final Model which gave best accuracy and performance over this gold dataset:
Dot 5: App
Once the best model is built then the remaining and the last dot is how this can be used as an app for inference/prediction. Inference uses CPU since the each request is processed asynchronously. Training was done on both CPU and GPU. Training per epoch on CPU took 140s on an average whereas on Nvidia 1080 GPU it took ~3x faster time. Simplest bet is to have something lightweight and when we talk about lightweight the first thing which comes to mind is Flask. We decided to go with jQuery UI Bootstrap since we wanted to develop the first iteration of the UI using existing UI components and secondly because it supports the mobile views accurately. Thanks to Arjun Upadhyaya for coming up with this UI approach and implementation. The idea was to present the user with the option to enter the text input and display the results as a progress graph. In this way, the results can be perceived very quickly by the end user. Finally, we brainstormed and added the pick-list of 5 sample movie review inputs to allow the user to test the model without having to input the text manually.
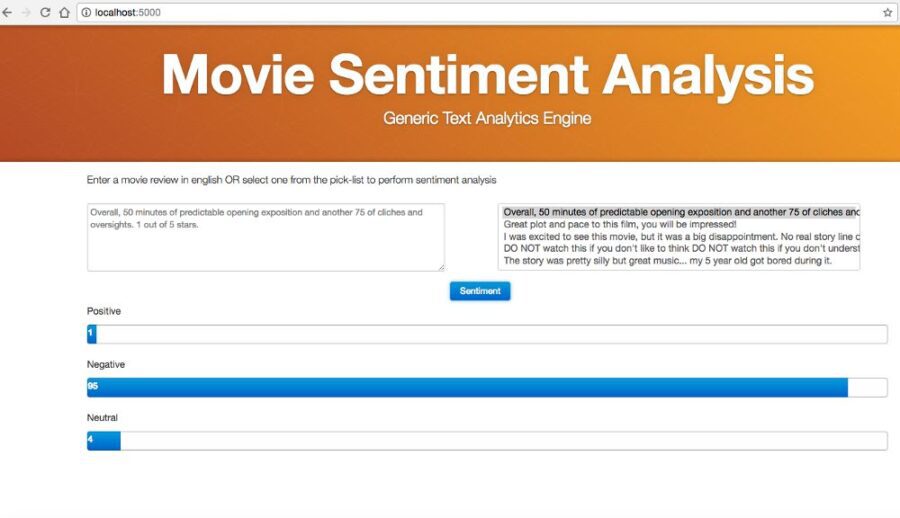
For original blog, click here
{kind=link}