
Announcements
- Businesses are under increasing pressure to move more quickly, and AIOps can help by harnessing the power of AI, machine learning, and big data analytics to monitor and manage the wide array of IT processes needed for success in the digital age. In the AIOps Aids Complex IT Environments webinar, learn about the options for implementing AIOps and how to best use it to simplify functions such as infrastructure optimization, alert correlation, root-cause analysis and issue resolution.
- Thanks to distributed computing models, 5G availability, and the growth of IoT, edge computing is poised to erupt. Bringing applications and data closer to the people and devices using them can reduce latency, improve security, reduce costs, and improve reliability, but requires significant investments in infrastructure and data management. Register for the Enabling Edge Computing summit to learn about the hardware, application architectures, network connectivity, monitoring tools, and security measures needed, as well as data analytics capabilities that enable automation at the edge.

Are Generative Adversarial Networks Really Useful?
Such a question may seem as coming from a dinosaur, adverse to change. Or from someone selling traditional methods and badmouthing anything that feels threatening to his business. This is not the case here: I always try to stay neutral, and usually – while typically not a first adopter – I tend to embrace novelty if it brings value.
The short answer is that GANs have been very successful in applications such as computer vision. Many computer-intensive AI platforms rely on them, partly because of their benefits and partly for marketing purposes as they tend to sell well.
There are many good things in GAN, but also many features that could improve. But what is GAN to begin with?
GAN is a technique mostly used to mimic real datasets, create new ones and blend them with real data to improve predictions, classification or any machine learning algorithm. Think about text generation in ChatGPT. It has two parts: data generation (the synthesizer) and checking how good the generated data is (the discriminator). In the process, it uses an iterative optimization algorithm to move from one set of synthetized data to the next one. This is hopefully a better one, using a gradient technique minimizing a cost function involving many parameters. The cost function tells you how good or bad you are at mimicking the real data.
The immediate drawbacks are the risk of over-fitting, the time it takes to train the algorithm, and the lack of explainability. There are solutions to the latter, based on feature importance. But if you work with traditional data (transactional, digital twins, tabular data), what are the benefits? Or more specifically, can you get most of the benefits without using an expensive, slow GAN implementation?
The answer is yes. Copulas can efficiently replicate the feature distribution and correlation structure present in your real data. Indeed, many GAN systems also use copulas. Parameter-free empirical quantiles used in copulas can get replaced by parametric probability distributions fit to your real data. If a feature is bimodal, try a mixture of Gaussian distributions: now you are playing with GMMs (Gaussian mixture models) sometimes incorporated in GAN.
But one of the big benefits of GAN is its ability to navigate through a high-dimensional parameter space to eventually get closer to a good representation of the original data, albeit very slowly due to the curse of dimensionality. Parameter-free, copula-based methods would require a tremendous number of simulations, each using a different seed from a random generator, to compete with GAN. What GAN could do in several hours, these simulations may require months of computing power to achieve similar results.
But there is a solution to this, outside of GAN. First, use a parametric technique with your copula method (or other method such as noise injection). If you have many features, you may end up with as many parameters as a large GAN system, so you are stuck again. One workaround is to compress the feature space: use selected features for selected groups in your data. Another way is to optimize 2-3 parameters at a time in a stepwise procedure. Start from various configurations, as in swarm optimization, and do it separately for data segments (groups) as in ensemble methods such as XGBoost. You may not reach a global optimum, but the difference with extensive neural network processing (GAN) may be very small. You also have a more interpretable technique that is faster and requires fewer resources than GAN, and is thus less expensive. And if it’s homemade, you have full control of the algorithm.
The picture below summarizes the different steps involved in data synthetization. Detailed explanations about the picture are in my article “Data Synthetization in One Picture.”
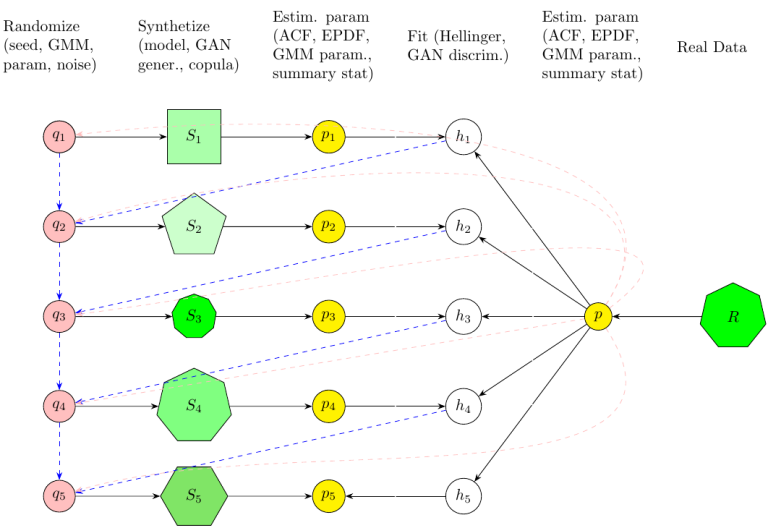
Vincent Granville
Contributor
Contact The DSC Team if you are interested in contributing.
DSC Featured Articles
- Copyright Protection and Generative Models – Part Two
February 28, 2023 at 1:40 pm
by ajitjaokar - Copyright Protection and Generative Models – Part One
February 28, 2023 at 1:25 pm
by ajitjaokar - Empowering Industry 5.0 with Advanced Manufacturing Execution systems
February 27, 2023 at 1:00 pm
by Nikita Godse - Role of Questions versus Decisions in Creating Value
February 26, 2023 at 2:24 pm
by Bill Schmarzo - Maximizing Business Success with UI/UX Design: The Top 5 Advantages
February 23, 2023 at 6:17 pm
by Evan Morris - Sorry, There Are No Shortcuts To Transformation
February 22, 2023 at 12:53 pm
by Bill Schmarzo - DSC Weekly 21 February 2023 – Data Passivity and the Current Obsession with Off-The-Shelf Chatbots
February 21, 2023 at 7:17 pm
by Scott Thompson
Picture of the Week
:%20Are%20They%20Really%20Useful?){kind=link}