
In the intricate landscape of Conversational AI, Retrieval-Augmented Generation (RAG) emerges as a technical marvel, seamlessly merging the strengths of generative and retrieval models. At its core, RAG tackles the challenge of precision in responses by introducing a dynamic knowledge retrieval component.
In this technical exploration, we delve into the underpinnings of RAG. Imagine a model that not only generates text but also possesses the ability to fetch information from a designated knowledge source. The fusion of these capabilities elevates the conversational experience to new heights, addressing limitations inherent in standalone generative or retrieval approaches.
Through this blog, we are going to unravel RAG techniques, unveiling their potential to redefine benchmarks in Generative AI. Join us as we navigate the technical intricacies of RAG.
Let’s dive deeper into RAG techniques, which would give an understanding of how they help in retrieving documents.

RAG 01 – Using RetrievalQA:
RetrievalQA is a simple retrieval QA chain built over load_qa_chain, which retrieves only relevant documents from the vector database using various options:
- Embeddings: We can utilize various embeddings from HuggingFaceEmbeddings, HuggingFaceBgeEmbeddings, InstructEmbeddings, etc., based on the use case.
- Text Splitters: Various text splitters are available for different text formats, such as HTML, JSON, and recursive splitting by character. These text splitters are used for chunking the data without losing any contextual meaning. To ensure the context is preserved, overlapping is employed while chunking so that no context is lost. We recommend you go through the doc from LangChain.
- Chain_type: There are four options: map-reduce, map_rerank, refine, and stuff. The ‘stuff’ option is generally used for large documents, such as those exceeding 1000 tokens.
- Vectorstores: Various vector stores are available in the market, including FAISS, Chroma, Pinecone (requires subscription), etc. FAISS and Chroma are open-source and can be maintained locally.
- Retrievers: The retrievers are created using any vector store instantiation. They are used to retrieve similar documents using various search options: ‘similarity’ or ‘mmr’. ‘Similarity’ retrieves documents from text chunk vectors that are most similar, while ‘mmr’ (maximum marginal relevance) search optimizes for similarity to the query and diversity among the selected documents.
RAG 02 – MuliqueryRetriever:
In general, we see that distance-based retrieval represents queries in a high-dimensional space but may produce results that are not highly relatable to the question asked. This happens because of semantic irrelevance.
Prompt engineering could help in addressing the irrelevance of results, but it does not always solve such issues. The MultiQueryRetriever is one concept that helps in creating similar queries for the question asked in the prompt. It generates multiple queries with different perspectives using LLM (Large Language Models).
For example:
What does the course say about regression?
Similar Questions:
- What is the course’s perspective on regression?
- Can you provide information on regression as discussed in the course?
- How does the course cover the topic of regression?
- What are the course’s teachings on regression?
- In relation to the course, what is mentioned about regression?
By using the above questions, LLM will have more context to search through for precise results.
RAG-03 – Vector store-backed retriever:
Vector stores operate on the concept of vectorization, representing data points as vectors or embeddings in a multidimensional space. The information retrieved from the vector store is utilized to properly respond to the user. This is where RAG models/pipelines come into play, defining various patterns on how efficiently information can be retrieved from the vector database.
A vector store-backed retriever is a retriever backed by the vector store. It uses similarity search and MMR to retrieve the documents.
Similar to retrievalQA, we have options to choose the type of search. For example, ‘similarity_score_threshold’, where this parameter is a variable that accepts a score threshold in search_kwargs.
Syntax:
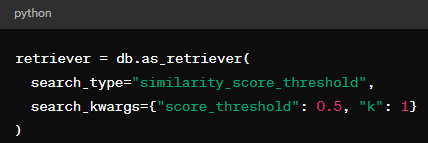
We can also include the option of top k retrievals, for example, setting k = 1 in search_kwargs.
RAG-04 – Hybrid Search using BM25Retriever:
Hybrid search utilizes both Keyword-style and Vector-style search, leveraging keyword and semantic lookup capabilities.
This approach makes use of an algorithm called BM25, which has been around since the 1970s and 1980s. It incorporates the IDF (Inverse Document Frequency) concept and a ranking function that ranks documents based on the words occurring in the query.
Below is the mathematical formula for the BM25 algorithm:
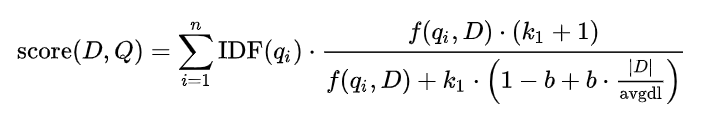
Langchain provides us with a package that implements the BM25 algorithm under the retrievers section, called BM25Retriever.
As mentioned, we can include any other retriever in combination with BM25Retriever, which produces sparse vectors. Ensembling BM25Retriever with any vector store retriever that produces dense vectors offers embedding lookup.
EnsembleRetriever is used to combine multiple retrievers, which significantly improves vector search and obtains the best-ranked results.
RAG-05 – Contextual Compression
The challenge lies in retrieving the required information buried within documents containing a lot of irrelevant text. These lengthy documents not only lead to expensive LLM calls but also result in weak responses.
Contextual compression offers a solution to this challenge. The technique involves compressing the documents without returning them as they are. Instead, the idea is to compress the documents using the context from the query, ensuring that only relevant information is returned.
To implement contextual compression, we’ll need several components: a base retriever, a vector store retriever, and a document compressor, such as an LLM extractor or LLM chain filter, which takes input from LLM.
The Contextual Compression retriever supplies queries to the base retriever, retrieves the initial documents, and then passes them through the document compressor. The Document Compressor, in turn, takes a list of documents and shortens the content to include only relevant information. If the documents are completely irrelevant to the context, they are dropped altogether.
For example, below is an excerpt of a document retrieved using the vector store retriever:
Query: What is the full form of LIPA?
Answer:
Long Island Power Authority (LIPA) has implemented a new e-Procurement platform called Bonfire. Hard copy proposals will not be accepted. All proposals and accompanying documentation will become the property of LIPA and may not be returned. LIPA expressly reserves the right to utilize any and all ideas submitted in the proposals received unless covered by legal patent or proprietary rights which must be clearly noted in the proposal submitted in response to the RFP. Late proposals will not be accepted, nor will additional time be granted to any individual Contractor. For a quick tutorial on how to upload a submittal, visit: Vendor Registration and Submission
Addenda: If, at any time, LIPA changes, revises, deletes, clarifies, increases, or otherwise modifies
This answer presents a challenge for LLM processing due to its length, incurring additional costs. After applying compression techniques, below is the resulting answer:
Compressed Document:
Long Island Power Authority (LIPA) has implemented a new e-Procurement platform called Bonfire. All proposals and accompanying documentation will become the property of LIPA and may not be returned. LIPA expressly reserves the right to utilize any and all ideas submitted in the proposals received unless covered by legal patent or proprietary rights which must be clearly noted in the proposal submitted in response to the RFP.
We observe a significant improvement in content reduction, retaining only the important information. The remaining content, which does not match the context of the query, is eliminated.
In summary, retrieval-augmented generation synergizes the strengths of retrieval-based and generative models to elevate the precision and relevance of the generated text. By harnessing the accuracy of retrieval-based models for information retrieval and the creative capabilities of generative models, this approach fosters more resilient and contextually grounded language generation systems.
{kind=link}