
Image source https://blog.google/technology/ai/google-gemini-next-generation-model-february-2024/
Current LLM applications are mostly based on LangChain or LlamaIndex. LangChain and LlamaIndex are frameworks designed for LLM development. They each cater to different use cases with unique features.
LangChain is a framework ideal for creating data-aware and agent-based applications. It offers high-level APIs for easy integration with various large language model (LLM) providers, supporting a broad range of capabilities and tool integration.
LlamaIndex focuses on indexing and retrieval of data, making it highly suitable for applications that require smart search and deep exploration of data. It features a lightweight interface for data loading and transfer and offers a list index feature for composing an index from other indexes. This functionality is useful for searching and summarizing data from heterogeneous sources, making LlamaIndex as a good choice for projects centered around data retrieval and search capabilities.
The choice between LangChain and LlamaIndex depends on the specific needs of your project. If you require a broader, more versatile framework for developing complex language model applications with multiple tool integrations, LangChain might be the right choice. Conversely, if your application’s core functionality revolves around efficient data search and retrieval, LlamaIndex could offer more targeted benefits.
A typical use case for LangChain involves building intelligent agents capable of integrating with various language models and external data sources. For example, creating an application that uses natural language to interact with databases, such as a chatbot that can query a SQL database in plain English and provide users with answers based on the database’s data.
A typical use case for LlamaIndex might be a custom knowledge management system where private or domain-specific documents are ingested and indexed, allowing users to perform natural language searches to find precise information within those documents. LlamaIndex, with its focus on efficient indexing and retrieval, is ideal for applications that need smart search capabilities across large volumes of data.
Now, the question is: How does this LLM application development status quo (ex RAG) change with the Gemini 1.5 pro-LLM with a 1M token context window?
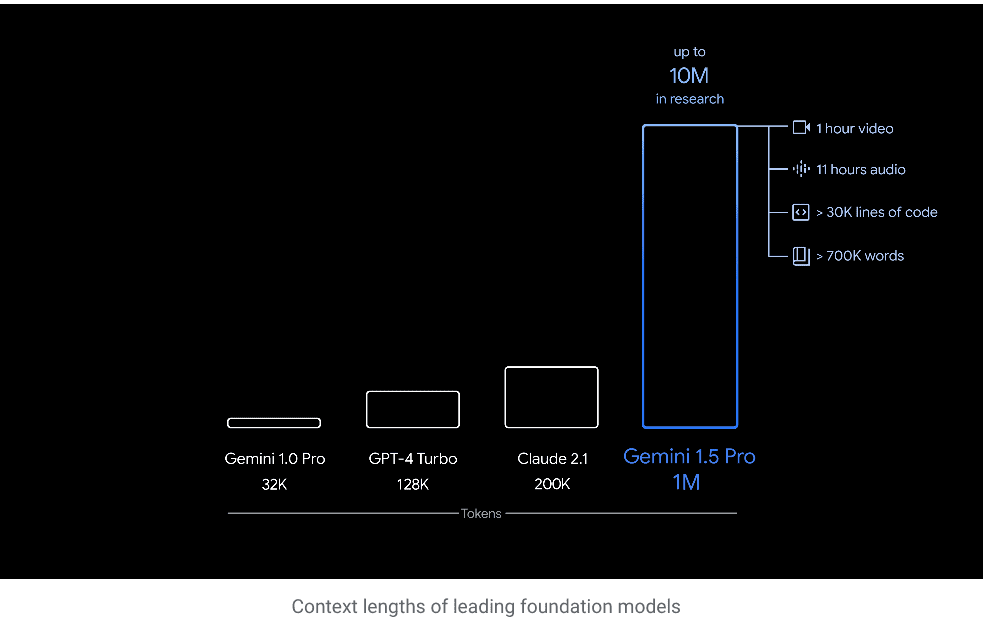
Google recently released Gemini 1.5 Pro with a 1M context window, The ability to process 1 million tokens in one go implies the capability to process vast amounts of information—including 1 hour of video, 11 hours of audio, codebases with over 30,000 lines of code or over 700,000 words.
It also means the LLM can reason over such vast amounts of information. For example, when given the 402-page transcripts from Apollo 11’s mission to the moon, it can reason about conversations, events, and details found across the document.
Also, 1.5 Pro can perform highly sophisticated understanding and reasoning tasks for different modalities, including video. The same abilities can also extend to problem-solving with longer blocks of code. In this scenario what happens to RAG?
LlamaIndex creator Jerry Liu proposes his vision having worked with Gemeni 1.5 Pro. He believes that as tokens get cheaper, we will see a new wave of large context LLMs in the future. While long-context LLMs will simplify certain parts of the RAG pipeline (e.g. chunking), new RAG architectures will need to be evolved to cater for the new use cases arising from long context LLMs. These could include QA over semi-structured data, over complex documents, and agentic reasoning in a multi-doc setting.
References:
https://www.llamaindex.ai/blog/towards-long-context-rag
https://blog.google/technology/ai/google-gemini-next-generation-model-february-2024/
{kind=link}