
WhiteNoise is the newly available Differential Privacy System by OpenDP. The intent of Differential Privacy is to preserve the security of personally identifiable information & prevent against database reconstruction attacks. The methods provided by the WhiteNoise system are part of a toolkit that enable researchers to readily enhance their existing processes with differential privacy techniques.
The Differential Privacy System
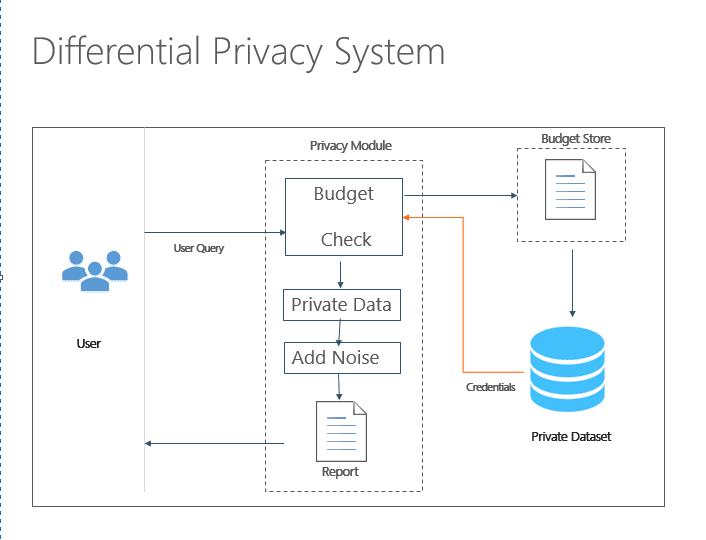
The Differential Privacy system provides the checks, balances and controls to enable researchers and analysts to balance model accuracy with data privacy constraints within a machine learning model. The system allows users to:
- Control Data – Throttle the completeness of data access requests via user budget
- Add Noise – Inject noise into the data set (epsilon/noise-level is inverse to accuracy)
- Report – Provide privatized data and transparency into results
Who is OpenDP?
OpenDP is an open source collaboration to build a system of tools for enabling privacy-protective analysis of sensitive personal data. Originating as a joint endeavor between Harvard’s Privacy Tools Project and Microsoft, today the project includes contributions from industry, academia & government.
Read more about Differential Privacy and OpenDP in the OpenDP White Paper
White Noise Library
The OpenDP White Noise library is available on GitHub as an open source library of algorithms for generating differentially private algorithms for statistical analysis and machine learning on sensitive data. Current capabilities assume the researcher is trusted by the data owner and enables creation of differentially private results over tabular data stores using SQL, implementing a shared privacy budget within a service to compose queries and differential privacy analysis for black-box stochastic testing.
The WhiteNoise methods are written in Rust and can be leveraged in Python via Protocol Buffers (protobuf). Additional work is being done to make capabilities also available in R.
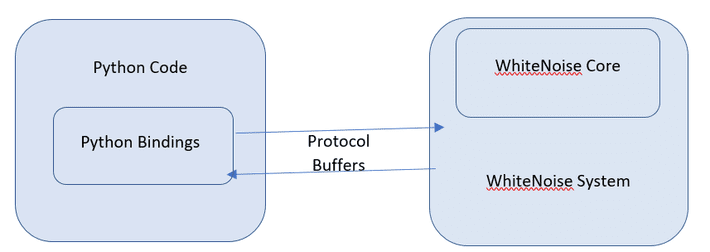
WhiteNoise Core Components comprise the libraries necessary for performing the statistical evaluations and analysis for differential privacy.
- Analysis – graphical representation of computations
- Validator – rust library for validating differentially private
- Runtime – Rust reference runtime
- Bindings – python language bindings
WhiteNoise System Components comprise the mechanisms to interact with the Core components.
- Data Access –Python library to intercept and process SQL queries
Supports: PostgreSQL, SQL Server, Spark, Presto, Pandas
- Service – REST endpoint to serve requests or queries against shared data sources
- Evaluator – enables support of Privacy, Accuracy, Utility & Bias Tests
System :: Data Access
Within an AI driven organization, how do we make data more readily available for analysis and insights across the organization, while also protecting the private data of our customers and clients? The WhiteNoise SQL DataReader is a wrapper available in Python that triggers the addition of white noise to a data set when calling the PrivateReader method. Details below:
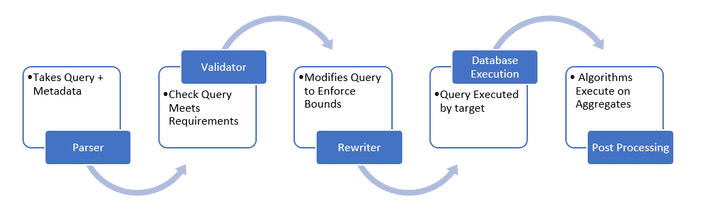
- Parser – Takes query + metadata
- Validator – The validator checks that query meets requirements for differential privacy
- Rewriter – Modifies the query to enforce bounds
- Database Execution – Query is executed by target database engine
- Postprocessing – Aggregates are submitted to the differential privacy algorithms to create differentially private results
Let’s see what we can do with the WhiteNoise library and the Titanic train data set from Kaggle.com. The code snippet below is an example of how easy it is to invoke the SQL Data Reader. The researcher needs to import the WhiteNoise module which exposes the opendp.whitenoise.metadata and opendp.whitenoise.sql libraries. The reader libraries wrap around the PandasReader module from the Pandas library.
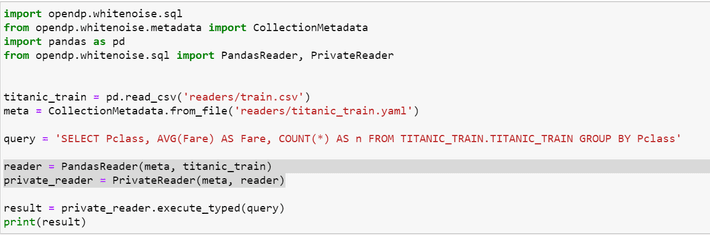
Highlighted above are steps to call the reader. You must first instantiate the PandasReader object against the data source, then instantiate the WhiteNoise PrivateReader against the PandasReader object. The query can then be passed through to the WhiteNoise PrivateReader object. As demonstrated, the WhiteNoise wrapper is easily implemented and is extensible across PostgreSQL, SQL Server, Spark, Presto and Pandas.
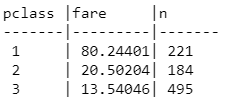
When viewing results from the PrivateReader, it should be noted that subsequent calls to the PrivateReader will result in slightly different results. Results should fall in a uniform distribution as random noise is injected into the data set.
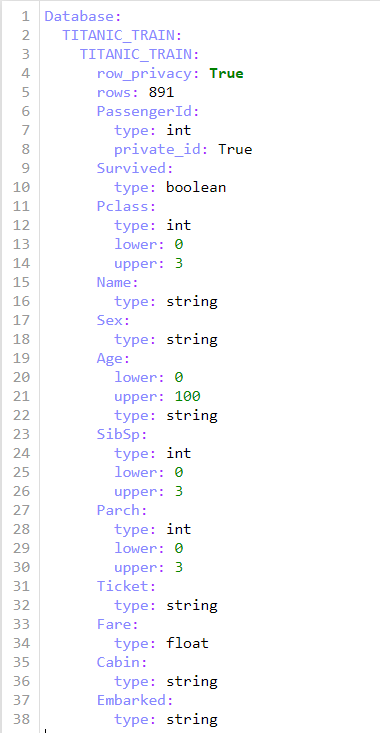
What’s in a YAML file?
Both the PandasReader object and the WhiteNoise PrivateReader object take the CollectionMetadata object and read in metadata about datasets.
Income, Age, Sex & medical characteristics are all attributes that may be considered personally identifiable and private.
When performing analysis on personally identifiable data sets, which fields are private? Which fields are necessary for the experiment being performed by the researcher? Who should have access to these fields?
Organizations can leverage metadata files to define which fields require a budget and set upper and lower bounds for variables.
Metadata can be constructed in YAML or directly in code
To the right is an example YAML file for the Titanic training set.
System :: Service
The WhiteNoise libraries include methods for auto generating the REST client and models for APIs via swagger definition. The APIs provide access to the core modules: Dataset, Linear Regression, Logistic Regression, SQL & Synthetic Data.
Core :: Analysis & Validator + System :: Evaluator
Within the Core libraries are statistical methods to impose differential privacy within commonly utilized statistical calculations for the aggregates: mean, variance, moment & covariance. Data is privatized by returning data sets that have been perturbed by Gaussian, Geometric or Laprace noise. Mechanisms for each are available, as well as methods enabling digitizing, filtering & transforming data sets.
In experiments, the size of a data set can also be considered private or the researcher may work with datasets of unknown size. Core libraries provide methods for clamping, resizing, calculating n and nullity checks. Clamping is a method to define upper and lower bounds for variables, resizing add records to a dataset to mask population size, n is the estimate sample data size and nullity is the ability to determine whether the validator can guarantee results.
The example below adds Gaussian noise to the ‘Age’ values within our data set. The privacy usage can be adjusted by the epsilon value passed. A larger epsilon means less privacy. While a smaller epsilon means more privacy.

Post-analysis, the evaluator allows us to analyze and evaluate whether our analysis satisfies Differential Privacy standards:
- Privacy Test – Does the report meet differential privacy conditions?
- Accuracy Test – Does the reliability of the report fall within the upper and lower bounds?
- Utility Test – Are the confidence bounds close enough to the data? Are we maximizing privacy?
- Bias Test – Is the distribution of repeated queries balanced?
We’ve seen how the WhiteNoise Package enables a system for protecting personally identifiable information. Want to learn more about Responsible ML and WhiteNoise? OpenDP’s GitHub repository includes Python notebooks to get you started with the WhiteNoise libraries. Last week, Microsoft Build 2020 announced new Responsible ML and WhiteNoise capabilities. You can watch Salil Vadhan, Leader of Harvard’s Privacy Tools Project on the Channel 9 AI-Show with Seth Juarez, and hear about the Science Behind WhiteNoise. You can also view a post on Responsible ML and the Importance of Building AI Systems That We Can Trust, posted by Eric Boyd Corporate VP, Azure AI.
Additionally, Global AI Community was given a preview of Responsible ML tools. Eva Pardi provides an overview of Interpret-Text, an open source package that enables developers to understand their models behavior and the reasons behind individual predictions. Willem Meints discusses FairLearn, A python package that enables developers to assess and address fairness and observed unfairness within their models. Finally, Sammy Deprez will take you into the magical world of ConfidentialML, with Microsoft Seal and OpenEnclave.
About the Author:
Alicia is a Microsoft AI MVP, she authors the blog HybridDataLakes.com, a blog focused on cloud data learning resources. She is also an organizer for Global AI Bootcamp – Houston Edition, a Microsoft AI sponsored event. Alicia is active in the PASS User Group community, and enjoys speaking on #AI and #SQLServer topics.
Alicia has been in the Database/BI services industry for 10+ years. Alicia has earned Microsoft Certified: Azure Solutions Architect Expert & MCSE: Data Management & Analytics. She also holds certifications in both Azure and AWS Big Data.
{kind=link}