
Summary: Not everyone wants to invest the time and money to become a data scientist, and if you’re mid-career the barriers are even higher. If you still want to be deeply involved in the new data-driven economy and well paid, the growth rate and opportunities as a data engineer or business analyst need to be on your radar screen.

OK, given that Data Scientist is still the sexiest job in America, what happens if you can’t or don’t want to invest your time and money to achieve that credential?
Seldom a week goes by without someone posing a question about how to switch from their existing career into data science. While I personally believe that you can’t have more fun anywhere else, there are many legitimate barriers facing those wanting to switch. Especially if you are more than 5 or 10 years out of school.
We wrote at length about this in “Some Thoughts on Mid-Career Switching Into Data Science”. It’s one of our most widely read articles so apparently there are a lot of folks trying to figure this out. Basically we said there are no shortcuts. While it will be intellectually and eventually financially rewarding, it’s hard if your career is already underway.
Even if you are mid-education, the full blown data science credential isn’t right for everyone. And with the new corporate orientation toward democratizing data (code word for self-service), anyone who wants to get down into the data will have plenty of opportunity to do so.
The good news in an increasingly data-driven world is that there is a pyramid of supporting roles growing even faster than the data scientist role. They’re in demand. They pay well, and you may indeed find it easier to leverage your current skills into one of these roles, perhaps with the aid of a MOOC, a boot camp, or even OJT.
We’re talking about two roles that have existed for some time, Data Engineer and Business Analyst.
Data Engineers
For the better part of the last decade and certainly in the last five years, data scientists have put an inordinate new load on traditional IT organizations. Traditional IT has also had a real change of mission.
Historically, IT was about servicing its internal customers at least cost within acceptable SLAs. Keeping costs down is still important, but as data and data science became drivers of revenue, profit, and strategic differentiation, IT found itself with a more urgent support mission.
The separate skills associated with Big Data, particularly Hadoop/Hive, Spark, streaming data, IoT, data lakes, cloud platforms, and the ETL and blending of structured and unstructured data have been separated out into a career path variously called either Data Engineer or Big Data Developer.
As data scientists have become more specialized, they don’t have these hands on skills nor is it something that’s efficient for them to do. Companies are increasingly establishing analytic teams in which Data Engineers may be part of this new group, or continue to report in through IT, but distinct from the traditional IT organization.
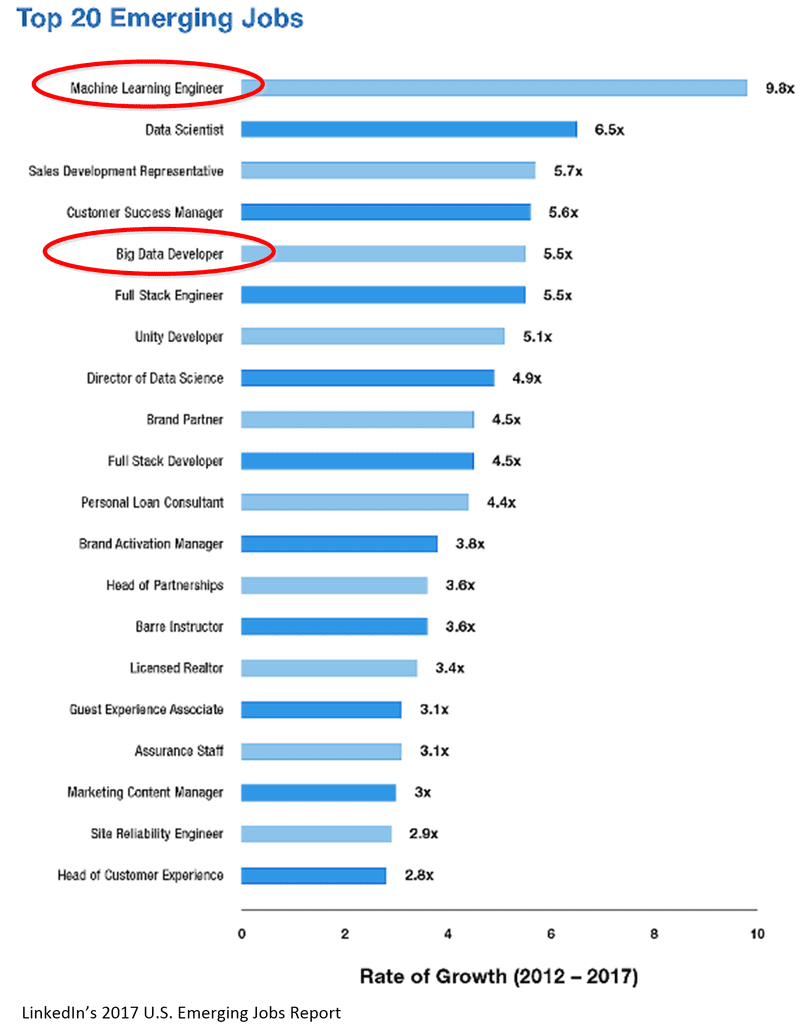
As it turns out, the Data Engineer path, by its many names has been growing faster than the Data Scientist role. Machine Learning Engineer (aka Data Engineer) opportunities for example are growing 50% faster than Data Scientist opportunities.
What other evidence do we have that this is true? Qubole whose business is to very rapidly setup and manage cloud data platforms as a service has just released its 2018 Big Data Activation Report. This is a statistical look at over 200 of its customers ranging from large to small and how they are dealing with Big Data. As customers of Qubole, we know they are fairly advanced in their data lifecycle and look for both flexibility and economy.
Here’s the first interesting fact from their report. 76% of these companies actively use at least three Big Data open source engines for prep, machine learning, and reporting and analysis workloads (Apache Hadoop/Hive, Apache Spark, or Presto). These are squarely in the wheelhouse of the data engineer.
Secondly, the role of the data engineer in supporting self-service access to data is growing rapidly. The Qubole report shows year-over-year growth in users of 255% for Presto, 171% for Spark, and 136% for Hadoop/Hive.
While in data science we think of Spark as having completely replaced Hadoop, in fact Hadoop had 5 to 8 years of dominance in which to become the legacy Big Data platform of choice before Spark emerged. As a result, the data engineer is just as likely to be working in Hadoop/Hive as in Spark. There are clearly still roles for both.
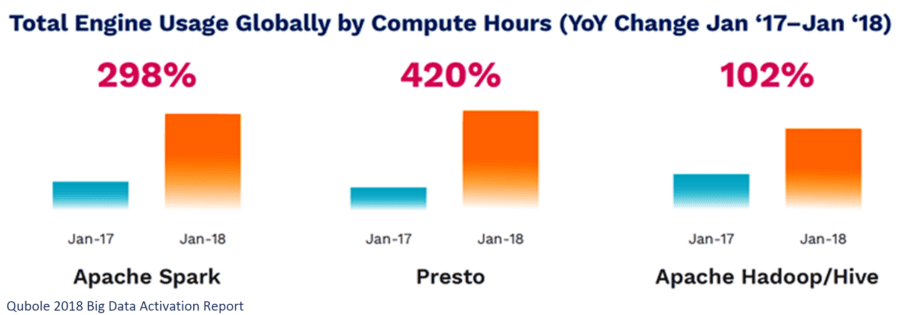
And while the number of users for all three systems has grown dramatically, the year-over-year growth in the number of actual compute hours tells a slightly different story with Spark growing almost three times as fast as Hadoop/Hive (298% versus 102%). Note that Hadoop/Hive still had the bulk of the hours (as the established legacy system) but that growth clearly favors Spark.
Data Analysts
Data Analysts are the new Citizen Data Scientists. This doesn’t mean they are expected to do everything a data scientist can do. It does mean they are increasingly expected to embrace new self-service tools in analytics and data viz, and to much more actively engage with all types of data than in the past.
As data science came into vogue and captured the imagination of business leaders, traditional BI receded from view but obviously never disappeared. BI is still at the heart of most operational reporting though analytics and reporting increasingly demands accessing data well beyond traditional RDBMS.
When Hadoop/Hive became open source in 2007 under the more generic name of NoSQL there was a period of perhaps five years in which the analyst’s classical strength in SQL couldn’t be applied to this new technology. That passed rapidly.
The new providers of Big Data DBs rapidly discovered that SQL was so dominant in the user community that growth without SQL was a non-starter. Rapidly NoSQL became NotOnlySQL and the number of SQL-like tools expanded rapidly.
Today, the lead open source SQL engine for Big Data platforms is Presto, and the number of implementations and growth in users and compute hours far outstrips either Hadoop/Hive or Spark (see above). This tells the story of just how rapidly self-service analytics and the blending of structured and unstructured data have become.
Data Analysts today have tools undreamed of by their earlier selves, ranging from full on blending and analytic platforms like Alteryx to remarkable data viz platforms like Tableau and Qlik. Or for the open source user, Presto allows all the capabilities of the SQL you have become expert with to be applied to the full range of unstructured and semi-structured data.
New Career Paths
Both Data Engineer and Business Analyst are career paths into data science. Both leverage existing skills in data science and SQL-based analytics without the requirement to meet the rigorous requirements needed by the full-fledged data scientist.
Both of these new opportunities are based on much more easily acquired skills, either through formal education, or through various types of self-study and OJT. If you’re looking at data science, don’t overlook these much more plentiful and easier to achieve satisfying careers.
Some other Data Science Career articles you may find valuable:
Some Thoughts on Mid-Career Switching Into Data Science (2017)
The New Rules for Becoming a Data Scientist (2016)
Data Scientist –Still the Best Job in America – Again (2016)
So You Want to be a Data Scientist (2015)
Getting a Data Science Education (2015)
How to Become a Data Scientist (2014)
Other articles by Bill Vorhies
About the author: Bill Vorhies is Editorial Director for Data Science Central and has practiced as a data scientist since 2001. He can be reached at:
{kind=link}