
By Rob Farber

Now is a great time to be procuring systems as vendors are finally addressing the memory bandwidth bottleneck. Succinctly, memory performance dominates the performance envelope of modern devices be they CPUs or GPUs. [i] It does not matter if the hardware is running HPC, AI, or High-Performance Data Analytic (HPC-AI-HPDA) applications, or if those applications are running locally or in the cloud. This just makes sense as multiple parallel threads of execution and wide vector units can only deliver high performance when not starved for data. [ii] Let’s look at the systems that are available now which can be benchmarked for current and near-term procurements.
Memory Bandwidth is defined by the number of memory channels
To start with, look at the number of memory channels per socket that a device supports. Succinctly, the more memory channels a device has, the more data it can process per unit time which, of course, is the very definition of performance.
So, look for the highest number of memory channels per socket.
Very simply, the greater the number of memory channels per socket, the more data the device can consume to keep its processing elements busy. Computational hardware starved for data cannot perform useful work. It does not matter how many cores, threads of execution, or number of vector units per core a device supports if the computational units cannot get data. Starved computational units must sit idle. Idle hardware is wasted hardware.
Vendors have recognized this and are now adding more memory channels to their processors. This trend can be seen in the eight memory channels provided per socket by the AMD Rome family of processors[iii] along with the ARM-based Marvel ThunderX2 processors that can contain up to eight memory channels per socket. [iv] One-upping the competition, Intel introduced the Intel Xeon Platinum 9200 Processor family in April 2019 which contains 12 memory channels per socket.
Benchmarks tell the story
Benchmarks tell the memory bandwidth story quite well. Intel recently published the following apples-to-apples comparison between a dual-socket Intel Xeon-AP system containing two Intel Xeon Platinum 9282 processors and a dual-socket AMD Rome 7742 system. As can be seen below, the Intel 12-memory channel per socket (24 in the 2S configuration) system outperformed the AMD eight-memory channel per socket (16 total with two sockets) system by a geomean of 31% on a broad range of real-world HPC workloads.
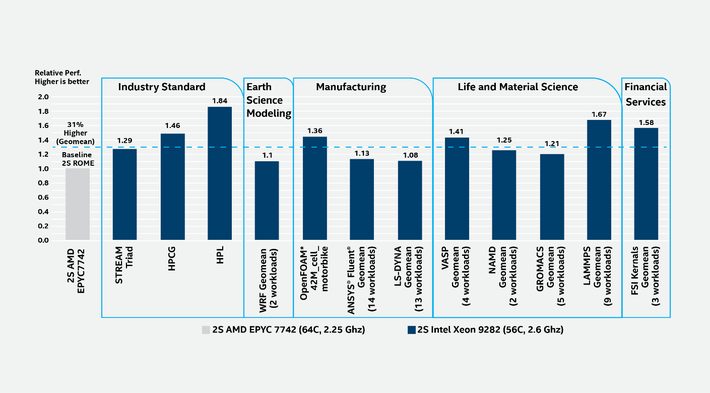
AMD vs. Intel HPC Performance Leadership Benchmarks updated with the most recent GROMACS 2019.4 version where Intel found no material difference to earlier data posted on 2019.3 version
(source Intel )[v]
These benchmarks illustrate one reason why Steve Collins (Intel Datacenter Performance Director) wrote in his blog—which he recently updated to address community feedback, “[T]he Intel Xeon Platinum 9200 processor family… has the highest two-socket Intel architecture FLOPS per rack along with highest DDR4 native bandwidth of any Intel Xeon platform. The Xeon Platinum 9282 offers industry-leading performance on real-world HPC workloads across a broad range of usages.” [vi] Not sold separately at this time, look to the Intel Server System S9200WK, HPE Apollo 20 systems or various partners [vii] to benchmark these CPUs.
“[T]he Intel Xeon Platinum 9200 processor family… has the highest two-socket Intel architecture FLOPS per rack along with highest DDR4 native bandwidth of any Intel Xeon platform. The Xeon Platinum 9282 offers industry-leading performance on real-world HPC workloads across a broad range of usages.”– Steve Collins, Intel Datacenter Performance Director
Extrapolating these results to your workloads
It is always dangerous to extrapolate from general benchmark results, but in the case of memory bandwidth and given the current memory bandwidth limited nature of HPC applications it is safe to say that a 12-channel per socket processor will be on-average 31% faster than an 8-channel processor. This can be a significant boost to productivity in the HPC center and profit in the enterprise data center. The expectation is that this 31% performance increase will hold true for most vector-parallel application workloads that have been compiled to run on x86 vector machines. No source code changes required.
Balancing cores to workload
Simple math indicates that a 12-channel per socket memory processor should outperform an 8-channel per socket processor by 1.5x. However, the preceding benchmarks show an average 31% performance increase.
The reason for this discrepancy is that while memory bandwidth is a key bottleneck for most applications, it is not the only bottleneck, which explains why it is so important to choose the number of cores to meet the needs of your data center workloads. In short, pick more cores for compute bound workloads and fewer cores when memory bandwidth is more important to overall data center performance. Most data centers will shoot for the middle ground to best accommodate data and compute bound workloads. Happily, this can translate into the procurement of more compute nodes as higher core count processors tend to be more expensive, sometimes wildly so for high core count devices.
All this discussion and more is encapsulated in the memory bandwidth vs floating-point performance balance ratio (memory bandwidth)/(number of flop/s) [viii] [ix] discussed in the NSF Atkins Report. [x] Succinctly, more cores (or more vector units per core) translates to a higher theoretical flop/s rate. Dividing the memory bandwidth by the theoretical flop rate takes into account the impact of the memory subsystem (in our case the number of memory channels) and the ability or the memory subsystem to serve or starve the processor cores in a CPU. It is up the procurement team to determine when this balance ratio becomes too small, signaling when additional cores will be wasted for the target workloads. A good approximation of the balance ratio value can be determined by looking at the balance ratio for existing applications running in the data center. Basically follow a common-sense approach and keep those that work and improve those that don’t. More technical readers may wish to look to Little’s Law defining concurrency as it relates to HPC to phrase this common sense approach in more mathematical terms. [xi]
Cooling is important
The power and thermal requirements of both parallel and vector operations can also have a serious impact on performance. This means the procurement committee must consider the benefits of liquid vs air cooling.
Many HPC applications have been designed to run in parallel and vectorize well. Such applications run extremely well on many-core processors that contain multiple vector units per core so long as the sustained flop/s rate does not exceed the thermal limits of the chip.
Thus look to liquid cooling when running highly parallel vector codes. Liquid cooling is the best way to keep all parts of the chip within thermal limits to achieve full performance even under sustained high flop/s workloads. Otherwise, the processor may have to downclock to stay within its thermal envelope, thus decreasing performance.
It is likely that thermal limitations are responsible for some of the HPC Performance Leadership benchmarks running at less than 1.5x faster in the 12-channel processors. Of course, these caveats simply highlight the need to run your own benchmarks on the hardware. Hence the focus in this article on currently available hardware so you can benchmark existing systems rather than “marketware”.
Advanced instructions for AI
Processor vendors also provide reduced-precision hardware computational units to support AI inference workloads. AI is fast becoming a ubiquitous workload in both HPC and enterprise data centers. Reduced-precision arithmetic is simply a way to make each data transaction with memory more efficient. For example, bfloat16 numbers effectively double the memory bandwidth of each 32-bit memory transaction. Similarly, Int8 arithmetic effectively quadruples the bandwidth of each 32-bit memory transaction. [xii] With appropriate internal arithmetic support, use of these reduced-precision datatypes can deliver up to a 2x and 4x performance boost, but don’t forget to take into account the performance overhead of converting between data types!
Summary
Many-core parallelism is now the norm. It’s no surprise that the demands on the memory system increases as the number of cores increase. Similarly, adding more vector units per core also increases demand on the memory subsystem as each vector unit data to operate.
Note to the reader
The AMD and Marvel Processors are available for purchase. The Intel Xeon Platinum 9200 processors can be purchased as part of an integrated system from Intel ecosystem partners including Atos, HPE/Cray, Lenovo, Inspur, Sugon, H3C and Penguin Computing.
[i] http://exanode.eu/wp-content/uploads/2017/04/D2.5.pdf
[ii] Long recognized, the 2003 NSF report Revolutionizing Science and Engineering through Cyberinfrastructure defines a number of balance ratios including flop/s vs Memory Bandwidth.
[iii] https://www.dell.com/support/article/us/en/04/sln319015/amd-rome-is…
[iv] https://www.marvell.com/documents/i8n9uq8n5zz0nwg7s8zz/marvell-thun…
[v] These are the latest results using the latest version of GROMACS 2019.4 which automates the AMD build options for their newest core, including autodetecting 256b AVX2 support.
[vi] https://medium.com/performance-at-intel/hpc-leadership-where-it-mat…
[vii] https://www.intel.com/content/www/us/en/products/servers/server-cha…
[viii] http://exanode.eu/wp-content/uploads/2017/04/D2.5.pdf
[ix] https://sites.utexas.edu/jdm4372/2016/11/22/sc16-invited-talk-memor…
[x] https://www.nsf.gov/cise/sci/reports/atkins.pdf
[xi] https://www.davidhbailey.com/dhbpapers/little.pdf
[xii] https://www.intel.ai/intel-deep-learning-boost/#gs.duamo1
{kind=link}