
 Several years ago, the typical company website fit into a predefined template – a home or landing page (usually talking about how innovative the company was), a products page, a business client testimonials page, a blog, and an “about us” page. However, as the number of products or services have multiplied, and as the demands for supporting those services have followed suit, your readers had to spend more time and energy finding appropriate content – and web managers had to focus more on keeping things organized than they likely wanted to do.
Several years ago, the typical company website fit into a predefined template – a home or landing page (usually talking about how innovative the company was), a products page, a business client testimonials page, a blog, and an “about us” page. However, as the number of products or services have multiplied, and as the demands for supporting those services have followed suit, your readers had to spend more time and energy finding appropriate content – and web managers had to focus more on keeping things organized than they likely wanted to do.
There are typically two different, though complementary, approaches to follow in locating resources on sites – search and semantics. Search usually involves indexing keywords, either directly, or through some third-party search engine. Search can be useful if you know the right terms, but once you get beyond a few dozen pages/articles/blog posts, search can also narrow down content too much, or fail to provide links to related content if that content doesn’t in fact have that exact search term.
Semantics, on the other hand, can be roughly thought of as a classification scheme, usually employing some kind of organizational taxonomy. The very simplest taxonomy is just a list of concepts, which usually works well for very basic sites. These usually have a fairly clear association with a single high-level menu. For instance, the example given above can be thought of as a simple (zeroeth-level) taxonomy, consisting of the following:
RootHomeBooksBlogsAbout Us
The Root node can be thought of as an invisible parent that holds each of the child terms. Each of these could in fact point to page URLs (which is how many menus are implemented), but those pages in turn may in fact be generated. The Home page generally is some kind of (semi-static) page. It has a URL that probably looks something like this:
https://mysite.com/homeFor brevity’s sake, we can remove the domain name and treat the URL as starting with the first slash after that:
/homeYour CMS also likely has a specialized redirect function that will assign this particular URL to the root. That is to say:
Notice as well the fact that “home” here is lower case. In most CMS systems, the menu item/concept is represented by what’s called a slug that can be thought of as a URL friendly ID. The slugs are typically rendered as a combination of a domain or categorical name (i.e.,mybooks) and a local name (home), separated by a “safe” delimiter such as a dash, an underscore or a colon (for instance, mybooks_). Thus, there’s a data record that looks something like:
MenuItem:
label: Home
id: mybooks_home description: This is the home or landing page for the site. parent: mybooks_
This becomes especially important when you have spaces in a label, such as “About Us”, which would be converted to something like mybooks_about-us as its identifier. The combination of the prefix and the local-name together is called a qualified name and is a way of differentiating when you have overlapping terms from two different domains (among other things) which local-name term is in focus.
When you get into products, you again may have a single page that describes all of your products, but maintaining such product pages by hand can be a lot of work with comparatively little gain, and also has the very real possibility in this world of collaboration that you and another colleague may end up updating that page at the same time and end up overwriting one another.
One way around this is through the use of categories or tags. This is where your taxonomy begins to pay dividends, and it comes about through the process of tagging. Think of each product that you have to offer as an individual post or entry. As an example, let’s say that your company sells books. Your content author can create a specific entry for a book (“My Book of Big Ideas!”) that contains important information such as title, author(s), a summary, price and other things, and it’s likely that the book will end up with a URL something like
/article/my-book-of-big-ideas
You could, of course, create a page with links to each of these books . . . or you could add a category tag called Book to the book entry. The details for doing so change from CMS to CMS, but in WordPress, you’d likely use the built-in Category widget. Once assigned, you can specify a URL that will give you a listing (usually based on temporal ordering from the most recent back), with the URL looking something like:
/category/books
This breaks one large page into a bunch of smaller ones tied together by the Product category in the taxonomy. Once you move beyond a certain number of products, though, it may at that point make sense to further break the taxonomy down. For instance, let’s say that your company produces books in a specific genre, such as Contemporary Paranormal, Historical Paranormal, Fantasy, and Steampunk. You can extend the taxonomy to cover these.
RootHomeBooksContemporary ParanormalHistorical ParanormalSword and SorcerySteampunk
BlogsAbout Us
This multilayer structure tends to be typical of first-level drop-down menus. Again, keep in mind that what is being identified here is not books so much as book categorizations. This kind of structure can even be taken down one more level (all of the above could be identified as being in the Fantasy genre), but you have to be careful about going much deeper than that with menus.
Similar structures can also be set up as outlines (especially when the taxonomy in question is likely to be extensive) that make it possible to show or hide unused portions of that taxonomy. This can work reasonably well up to around fifty or sixty entries, but at some point beyond that it can be difficult to find given terms and the amount of searching becomes onerous (making the user more hesitant in wanting to navigate in this manner).
There are things that you can do to keep such taxonomies useful without letting them become unwieldy. First, make a distinction between categories (or classes) and objects (or instances). Any given leaf node should, when selected, display a list of things. For instance, selecting Contemporary Paranormal should cause the primary display (or feed, as it’s usually known) to display a list of books in that particular genre. Going up to the Books category would then display all books in the catalog but in general only 20-25 per page.
It should be possible, furthermore, to change the ordering on how that page of books (or contemporary paranormal romance books if you’re in a subgenre) gets displayed – whether by relevance, by most recent content or alphabetically (among other sorting methods).
Additionally, there is nothing that says that a given book need be in only one category. In this case, the taxonomy does not necessarily have to be hierarchical in nature, but instead gives classes with possible states:
FictitiousnessFictionHistorical FictionNon-Fiction
MediumHard CoverPaperbackElectronic BookAudio Book
GenreBiographyAnalysisFantasyHorrorHistoricalMysteryParanormalRomanceSpace OperaScience Fiction
This approach actually works very well when you give a particular resource three or four different kinds of terms that can be used for classification. This way, for instance, I can talk about wanting Fiction-based electronic books that involve both paranormal elements, romance, and mystery. Moreover, you can always combine faceted search and textual search together, using the first to reduce the overall query return set, and the second to then retrieve from that set those things that also have some kind of textual relationship. This approach generally works best when you have several thousand items (instances) and perhaps a few dozen to a few hundred classes in your classification system. This is a process called faceting.
Faceting in effect decomposes the number of classes that you need to maintain in the taxonomy. You can also create clustering by trying to find the minimal set of attributes that make up a given class through constraints. For instance, the list of potential genres could be huge, but you could break these down into composites — does the character employ magic or not, does the story feature fantastic or mythical beings, is the setting in the past, present, or future, does the storyline involve the solving of a crime, and so forth. Each of these defines an attribute. The presence of a specific combination of attributes can then be seen as defining a particular class.
Faceting in this manner pushes the boundary between taxonomies and formal semantics, in that you are moving from curated systems to heuristic systems where classification is made by the satisfaction of a known set of rules. This approach lays at the heart of machine-based classification systems. Using formal semantics and knowledge graphs, as data comes in records (representing objects) can be tested against facets. If an object satisfies a given test, then it is classified to the concept that the test represents.
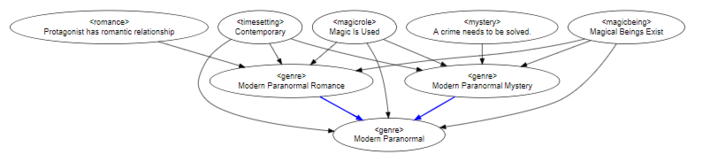
In this particular case, there are four sets of attributes. Three of them are the same for paranormal mystery vs. paranormal romance, while the fourth (whether a criminal mystery or a romance dominates the story) differentiates the two. The Modern Paranormal story, on the other hand, has just the three primary attributes without the mystery/romance attribute, and as such it is a super-class of the other two paranormal types, which is true in general: if two classes share specific attributes, there is a super-class that both classes are descended from.
Interestingly enough, there’s another corollary to this: in an attribute modeling approach, it is possible for three classes to share different sets of attributes, meaning that while any two of those classes may share a common ancestor, the other two classes may have a different common ancestor that doesn’t overlap the inheritance path.
At the upper end of such taxonomy systems are auto-classification systems that work by attempting to identify common features in a given corpus through machine learning then using input provided by the user (a history of the books that they’ve read, for instance) to make recommendations. This approach may actually still depend upon taxonomists to determine the features that go into making up the taxonomy (or, more formally, ontology), though a class of machine learning algorithms (primarily unsupervised learning) can work reasonably well if explainability is not a major criterion.
{kind=link}