

This article is part of a new series featuring problems with solution, to help you hone your machine learning and pattern recognition skills. Try to solve this problem by yourself first, before looking at the solution. Today’s problem also has an intriguing mathematical appeal and solution: this allows you to check if your solution found using machine learning techniques, is correct or not. The level is for beginners.
The problem is as follows. Let X1, X2, X3 and so on be a sequence recursively defined by Xn+1 = Stdev(X1, …, Xn). Here X1, the initial condition, is a positive real number or random variable. Thus,
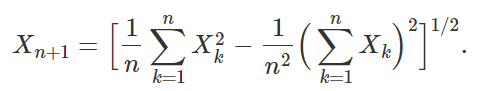
It is clear that Xn = An X1, where An is a number that does not depend on X1. So we can assume, without loss of generality, that X1 = 1. For instance, A1 = 1 and A2 = 0. The purpose here is to study the behavior of An (for large n) using simple model fitting techniques. I plotted the first few values of An, below. In the figure below, the X-axis represents n, and the Y-axis represents An. The question is: how to approximate An as a simple function of n? Of course, a linear regression won’t work. What about a polynomial regression?
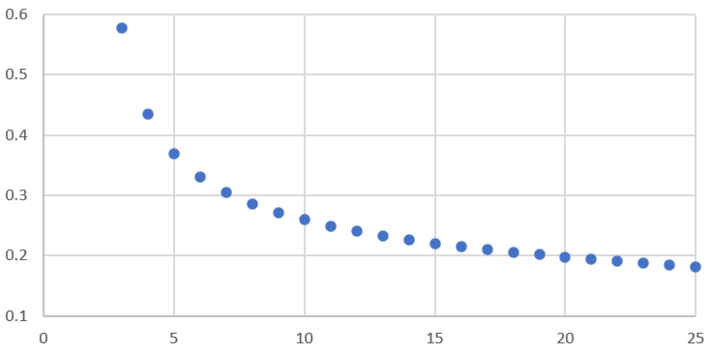
The first 600 values of An are available here, as a text file.
Solution
A tool as basic as Excel is good enough to find the solution. However, if you use Excel, the built-in function Stdev has a correcting factor that needs to be taken care of. But you can just use the values of An available in my text file mentioned above, to avoid this problem.
If you use Excel, you can try various types of trend lines to approximate the blue curve, and even compute the regression coefficients and the R-squared for each tested model. You will find very quickly that the power trend line is the best model by far, that is, An is very well approximated (for large values of n) by An = b n^c. Here n^c stands for n at power c; also, b and c are the regression coefficients. In other words, log An = log b + c log n (approximately).
What is very interesting, is that using some mathematics, you can actually compute the exact value of c. Indeed, c is solution of the equation c^2 = (2c + 1) (c + 1)^2, see here. This is a polynomial equation of degree 3, so the exact value of c can be computed. The approximation is c = -0.3522011. It is however very hard to get the exact value of b.
It would interesting to plot the residual error for each estimated value of An, and see if it shows some pattern. This could lead to a better approximation: An = b n^c (1 + d / n), with three parameters: b, c (unchanged) and d.
To receive a weekly digest of our new articles, subscribe to our newsletter, here.
About the author: Vincent Granville is a data science pioneer, mathematician, book author (Wiley), patent owner, former post-doc at Cambridge University, former VC-funded executive, with 20+ years of corporate experience including CNET, NBC, Visa, Wells Fargo, Microsoft, eBay. Vincent is also self-publisher at DataShaping.com, and founded and co-founded a few start-ups, including one with a successful exit (Data Science Central acquired by Tech Target). He recently opened Paris Restaurant, in Anacortes. You can access Vincent’s articles and books, here.
{kind=link}
Which formula did you use to get the data
1, 0, 0.577350269, 0.434736433, 0.368856205, 0.330594847,0.304894582, 0.285977839, 0.271195323, 0.259158608, … ?
With the formula in the text I get
1, 0, 0.5, 0.408248, 0.355779, 0.321895, 0.297871, 0.279681, 0.265251, 0.253405, 0.243428, 0.234856, 0.227372, 0.220754, 0.214839, …
I tried to get your data
1, 0, 0.577350269, 0.434736433, 0.368856205, 0.330594847, 0.304894582, 0.285977839, 0.271195323, 0.259158608, …
with the formula you gave