
There is a lot of data presented in a table format inside the web pages. However, it could be quite difficult when you try to store the data into local computers for later access. The problem would be that the data is embedded inside the HTML which is unavailable to download in a structured format like CSV. Web scraping is the easiest way to obtain the data into your local computer.
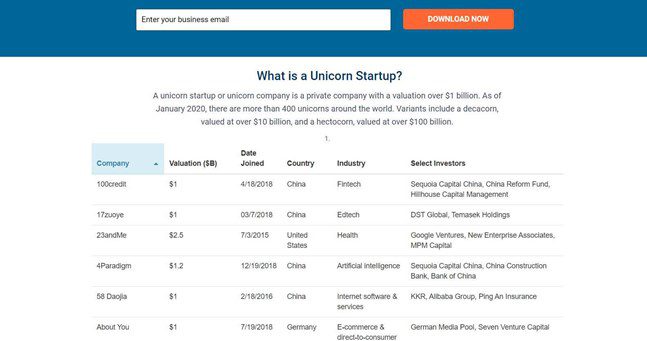
table data from Unicorn Startup
I would love to introduce 3 ways of scraping data from a table to those who barely know anything about coding:
- Google Sheets
- Octoparse (web scraping tool)
- R language (using rvest Package)
Google Sheets
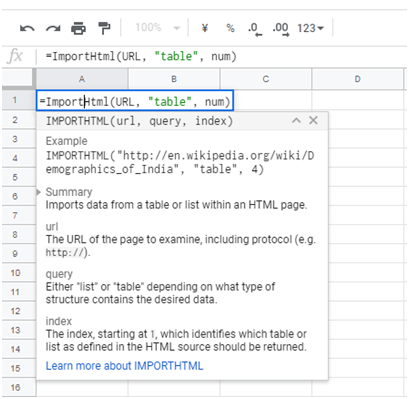
In Google sheets, there is a great function, called Import Html which is able to scrape data from a table within an HTML page using a fix expression, =ImportHtml (URL, “table”, num).
Step 1: Open a new Google Sheet, and enter the expression into a blank.
A brief introduction of the formula will show up.
Step 2: Enter the URL (example: https://en.wikipedia.org/wiki/Forbes%27_list_of_the_world%27s_high…) and adjust the index field as needed.
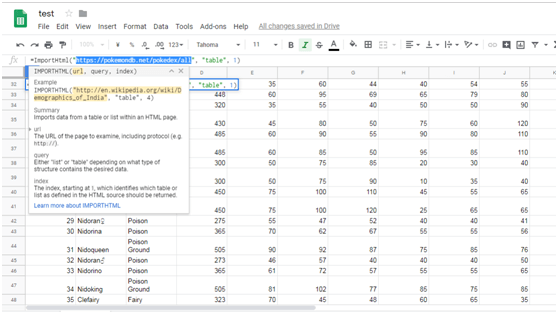
With the above 2 steps, we can have the table scraped to Google sheet within minutes. Apparently, Google Sheets is a great way to help us scrape table to Google sheets directly. However, there is an obvious limitation. That would be such mundane task if we plan scrape tables across multiple pages using Google Sheets. Consequently, you need a more efficient way to automate the process.
Scrape tables with a web scraping tool
To better illustrate my point, I will use this website to show you the scraping process, https://www.babynameguide.com/categoryafrican.asp?strCat=African
First of all, download Octoparse and launch it.
Step 1: Click Advanced Mode to start a new project.
Step 2: Enter the target URL into the box and click “Save URL” to open the website in Octoparse built-in browser.
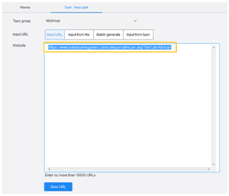
Step 3: Create a pagination with 3 clicks:
a) Click “B” in the browser
b) Click “Select all” in the “Action Tips” panel
c) Click “Loop click each URL” in the “Action Tips” panel
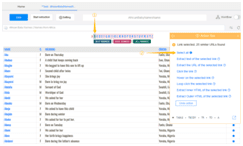
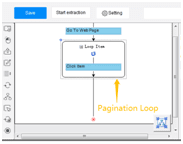
Now, we can see a pagination loop has been created in the workflow box.
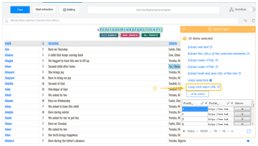
Step 4: Scrape a table with the below clicks.
a) Click on the first cell in the first row of table
b) Click on the expansion icon from “Action Tips” panel until the whole row is highlighted in green color (usually the tag should be TR)
c) Click on “Select all sub-elements” in the “Action Tips” panel, then “Extract data” and “Extract data in the loop”
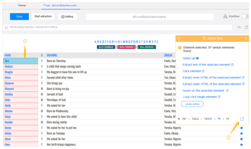
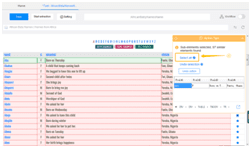
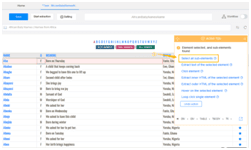
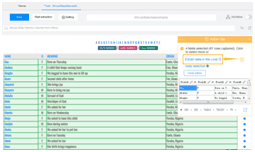
The loop for scraping the table is built in the workflow.
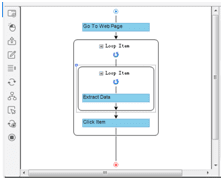
Step 5: Extract data
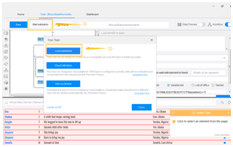
With the above 5 steps, we’re able to get the following result.
As the pagination function is added, the whole scraping process becomes more complicated. Yet, we have to admit that Octoparse is better at dealing with scraping data in bulk.
And the most amazing part is, we don’t need to know anything about coding. That said, whether we are programmers or not, we can create our “crawler” to get the needed data all by ourselves. To obtain further knowledge of scrape data from a table or a form, please refer to Can I extract a table/form?
However, if you happen to know some knowledge about coding and want to write a script on your own, then using the rvest package of R language is the simplest way to help you scrape a table.
R language (using rvest Package)
In this case, I also use this website, https://www.babynameguide.com/categoryafrican.asp?strCat=African as an example to present how to scrape tables with rvest.
Before starting writing the codes, we need to know some basic grammars about rvest package.
html_nodes() : Select a particular part in a certain document. We can choose to use CSS selectors, like html_nodes(doc, “table td”), or xpath selectors, html_nodes(doc, xpath = “//table//td”)
html_tag() : Extract the tag name. Some similar ones are html_text (), html_attr() and html_attrs()
html_table() : Parsing HTML tables and extracting them to R Framework.
Apart from the above, there are still some functions for simulating human’s browsing behaviors. For example, html_session(), jump_to(), follow_link(), back(), forward(), submit_form() and so on.
In this case, we need to use html_table() to achieve our goal, scraping data from a table.
Download R(https://cran.r-project.org/) first.
Step 1: Install rvest.

Step 2: Start writing codes as the below picture shows.
Library(rvest) : Import the rvest package
Library(magrittr) : Import the Magritte package
URL: The target URL
Read HTML : Access the information from the target URL
List: Read the data from the table
Step 3: After having all the code written in the R penal, click “Enter” to run the script. Now we can have the table information right away.

It seems that it doesn’t take less effort in using a web scraping tool than in writing a few lines of codes to extract table data. In fact, programming does have a steep learning curve which raises the threshold for people, in general, getting into the real power of web scraping. This situation makes people who don’t work in the tech industry harder to gain a competitive edge to leverage web data.
I hope the above tutorial will help you have a general idea of how a web scraping tool can help you achieve the same result as a programmer does with ease.
{kind=link}