
Guest blog post by Robert J. Abate.
In the past, I have published on the value of information, big data, advanced analytics and the Abate Information Triangle and have recently been asked to give my humble opinion on the future of Big Data.
I have been fortunate to have been on three panels recently at industry conferences which discussed this very question with such industry thought leaders as: Bill Franks (CTO, Teradata), Louis DiModugno (CDAO, AXA US), Zhongcai Zhang, (CAO, NY Community Bank), Dewey Murdick, (CAO, Department Of Homeland Security), Dr. Pamela Bonifay Peele (CAO, UPMC Insurance Services), Dr. Len Usvyat (VP Integrated Care Analytics, FMCNA), Jeffrey Bohn (Chief Science Officer, State Street), Kenneth Viciana (Business Analytics Leader, Equifax) and others.
Each brought their unique perspective to the challenges of Big Data and their insights into their “premonitions” as to the future of the field. I would like to surmise their thoughts adding in color to the discussion.

Recent Article By Bernard Marr
If you haven’t had the opportunity, I believe that a recent article published by Bernard Marr entitled: 17 Predictions About Big Data was a great start (original version posted here). Many of the industry thought leaders that I mentioned above had hit on these points.
What Was Missing…
I agree with all of Bernard’s listing but I believe that he missed some predictions that the industry has called out. I would like to add the following:
18. Data Governance and Stewardship around Master Data and Reference Data is rapidly becoming the key area where focus is required as data volumes and in turn insights grow.
19. Data Visualization is the key to understanding the overwhelming V’s of Big Data (IBM data scientists break big data into four dimensions: volume, variety, velocity and veracity) and in turn the advanced analytics and is an area where much progress is being made with new toolsets.
20. Data Fabrics will become the key delivery mechanism to the enterprise by providing a “single source of the truth” with regard to the right data source. Today the enterprise is full of “spreadmarts” where people get their “trusted information” and this will have to change.
21. More than one human sensory input source (multiple screens, 3D, sound, etc.) is required to truly capture the information that is being conveyed by big data today. The human mind has so many ways to compare information sources that it requires more feeds today in order to find correlations and find clusters of knowledge.
22. Empowerment of business partners is the key to getting information into the hands of decision makers and self-service cleansed and governed data sources and visualization toolsets (such as provided by Tableau, ClickView, etc.) will become the norm of delivery. We have to provide a “single source of the truth” and eliminate the pervasive sharing of information from untrusted sources.
23. Considering Moore’s Law (our computing power is increasing rapidly) and the technologies to look thought vast quantities of data is improving with each passing year, our analytical capabilities and in turn insights are starting to grow exponentially andwill soon change organizations to become more data driven and less “business instinct” driven.
24. Data is going to become the next global currency (late addition) and is already being globally monetized by corporations.
25. Data toolsets will become more widely used by corporations to both discover, profile and govern data assets within the confines of a data fabric or marketplace. Toolsets will include the management of metadata and automatic classification of assets and liabilities (i.e.: Global IDs, etc.).
The Four V’s Of Big Data
IBM uses a slide that discussed the myriad of challenges when facing Big Data – it is mostly self explanatory and hits many of the points that were mentioned in Bernard’s article. The Four V’s Of Big Data.
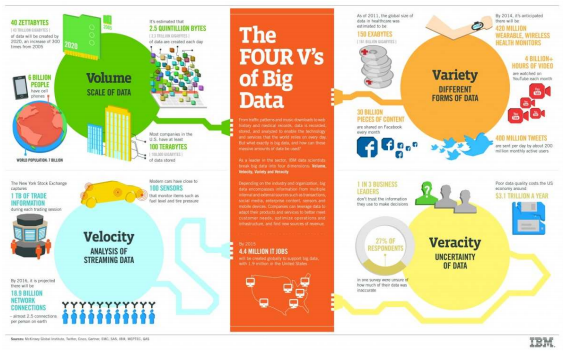
What this infographic exemplifies is that there is a barrage of data coming at businesses today and this has changed the information landscape for good. No longer are enterprises (or even small businesses for that matter) living with mostly internal data, the shift has happened where data is now primarily coming from external sources and at a pace that would make any organizations head spin.
Today’s Best Practice “Data Insights Process”
Today, external data sources (SFDC, POS, Market-share, Consumer demographics, psychographics, Census data, CDC, Bureau of labor, etc.) provide much more than half of the information into the enterprise with the norm to create value in weeks. How is this done you may ask? Let’s call this the Data Insights process. The best practice today has turned upside down the development of business intelligence solutions, this process is:
- Identify a number of disparate data sources of interest to start the investigation
- Connect them together (data integration using common keys)
- Cleanse the data (as Data Governance has not been applied) creating your own master and reference data
- Learn about what the data is saying and visualize it (what insight or trend has been uncovered
- Create a model that gives you answers
- Formalize data source (cleanse and publish) to the myriad of enterprise data consumers with governance (if applicable)
- Use the answers to change your business
- Repeat (adding new sources, creating new models, etc.)
This process utilizes data experts to find data sources of value (1 to 2 weeks), Quickly connect together and scan to determine suitability and eliminating information which is incomplete or lacking value/connection to other sources (integrating and cleansing takes about 2 weeks), Visualize what value these sources provide using data visualization toolsets – find interesting value statements or features of the data to pursue {like store clustering and customer segmentation} (1 to 2 weeks), Develop a model or advanced analytic to see what your value statement found using a Data Scientist (2 weeks), and Then present to business to determine next steps. This whole process happens in about 6-8 weeks and usually creates the “interest” in the business to invest in developing into a data warehouse or BI solutions.
Yes, the new process is completely reusable – as what is learned can be turned into a data source (governed data store or warehouse which is part of a data fabric) for future usage in BI and in turn for self-service; but what is important is that we now go from data to insights in weeks rather than months, and it forms the foundation for our business requirements – yes, I said that.
The long term investment of a BI solution (often six months or more) is proven rapidly and then the formal process of capturing the business requirements and rules (transformations in ETL language can be taken from rapid prototyping tools like Alteryx) has a head start and typically has the added advantage of cutting down the BI process into 3-4 months.
Recent Advances In Data Engineering
We can thank recent technological advancements for the changes in delivery of information with the advent of a number of toolsets providing self-service to tech-savvy business partners.

The recent tech and analytics advances in the past decade include but are not limited to:
- Massively parallel processing data platforms
- Advanced in-database analytical functions
- Analytics on un-structured data sources (Hadoop, MapReduce)
- Data visualizations across multiple mediums and devices
- Linking structured and unstructured data using semantics and linking
- Self-service BI toolsets and models of delivery
- Data discovery, profiling, matching and ELT and data enrichment capabilties
- Self-provisioning of analytics sandboxes enabling collaboration
But there is still a need for managing the information and this process is not going away. I will elaborate further in the paragraph below.
The Need For Enterprise Information Management
The myriad of data sources is changing the way we as business intelligence and analytics experts behave and likewise it has created a demand for data management and governance (with Master data and in turn Reference data) – so this element was added to the predictions. It’s a very important piece of the puzzle and should not be overlooked or downplayed. It was even added to my latest information triangle (see my Linked-In page).
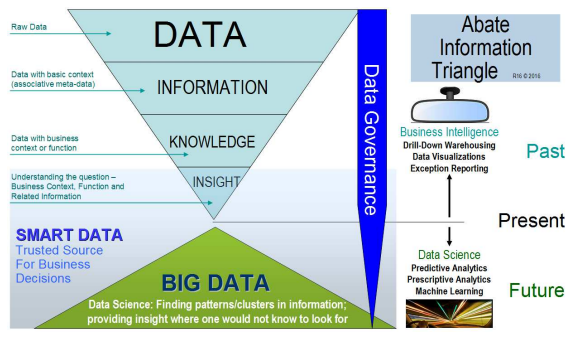
The role of enterprise data management in IT has been evolving from “A Single Source of Truth” into becoming “The Information Assurance Flexible Delivery Mechanism”. Back in March of 2008 I published at the DAMA International Symposium the needs for a flexible information delivery environment including:
- Metadata management for compliance enforcement, audit support, analysis, and reporting
- Master data integration and control
- Near-real time business information
- Source data management for controlling data quality at the transaction level
- Effective governance for a successful managed data environment
- Integration of analytics, reporting, and transaction control
- Control of business processes and information usage
A flexible structure is just as important today as business needs are changing at an accelerating pace and it allows IT to be responsive in meeting new business requirements, hence the need for an information architecture for ingestion, storage, and consumption of data sources.
The Need For Knowing Where Your Data Is Coming From (And Going To)
One of the challenges facing enterprises today is that they have an ERP (like SAP, Oracle, etc.), internal data sources, external data sources and what ends up happening is that “spread-marts” (commonly referred to as Excel Spreadsheets) start proliferating data. Different resources download data from differing (and sometimes the same) sources creating dissimilar answers to the same question. This proliferation of data within the enterprise utilizes precious storage that is already overflowing – causing duplication and wasted resources without standardized or common business rules.
Not to mention that these end up being passed around as inputs to other’s work – without knowledge of the data lineage. This is where many organizations are today – many disparate data sets with little to no knowledge of if this is a “trusted” data source.
Enterprise Data Fabric (or Data Marketplace)
An enterprise data fabric or marketplace (I’ve used both terms) is one location that everyone in the enterprise can go to get their data – providing quality, semantic consistency and security. This can be accomplishing with data lakes, data virtualization or a number of integration technologies (like API’s, services, etc.). The point is to give a common point of access to the enterprise for data that has been cleansed and is ready for use with master data. Here are a couple of reasons why you should consider this approach:
- Business mandate to obtain more value out of the data (get answers)
- Need to adapt and become agile to information and industry-wide changes
- Variety of sources, amount and granularity of data that customers want to integrate is growing exponentially
- Need to shrink the latency between the business event and the data availability for analysis and decision-making
Summation – Data Is The New Global Currency
In summation, consider that increasingly information is produced outside the enterprise, combined with information across a set of partners, and consumed by ever more participants so data is the new global currency of the information age and we all pass around currency – so let’s get cracking at delivering this to our enterprise (or it will go elsewhere to find it).
To the point, Big Data is an old acronym and the new one is “Smart Data” if you ask me.
I would welcome any comments or input into the above and have posted this including pictures on my linked in page – let’s start a dialog around best-practices in today’s information age…
Robert J. Abate, CBIP, CDMP
About the Author
Credited as one of the first to publish on Services Oriented Architecture and the Abate Information Triangle, Robert is a respected IT thought leader. He is the author of the Big Data & Analytics Chapter for DAMA’s DMBoK Publication and on the technology advisory board for Nielson. He was on the governing body for ‘15 CDO Forums and an expert panelist at 2016 CAO Forum / Big Data Innovation Summit.
{kind=link}