
Please join me in Las Vegas at Hitachi Vantara’s NEXT 2019 in October where I’ll be talking about data lake “second surgeries” – viva, baby.
Data science has been around long enough that we are seeing a substantial number of data science failures. Gartner has predicted that through 2020, 80% of AI projects will remain “alchemy, run by wizards whose talents will not scale in the organization.” VentureBeat, too, has stated that 87% of data science projects will never make it into production. Ouch!
These failures are creating “second surgery” opportunities, which is a situation where the organization tried an initial foray into a specific technology space (ERP, data warehousing, business intelligence, expert systems), but the results did not meet the expectations of business leadership and were considered a “failure.”
Data Science Failures
These “second surgery” situations, however, are part of the industry learning process which we can leverage to create viable “second surgery” strategies by understanding the typical six root causes for its failure:
- Relevance Failure. Failure to deliver the analytics that the stakeholders need to do their jobs; that is, a failure to deliver the specific analytics (predictions and recommendations) that the stakeholders need to address their specific business or operational problem.
- Adoption Failure. Failure to gain early (Day 0) stakeholder buy-in and active participation throughout the development of the analytics to ensure that the end results are actually used by the stakeholders.
- Actionability Failure. Failure to deliver analytics in a form or format in which the users can act on them. Forcing stakeholders to interpret a complex chart and search for the right action is a guaranteed way to ensure data science failure. Understandable analytics are necessary in order for the users to trust and then act on the analytic results.
- Impediments Failure. Failure to thoroughly explore and vet the potential impediments to success including data availability and quality, data engineering and data science competencies, a trained business stakeholder community and management fortitude to address passive aggressive behaviors and knock down the silos that impede data science success.
- Data Failure. Getting halfway into the project before you realize that the data that you need is not available at the right levels of granularity, latency, completeness and/or accuracy or the metadata is either poorly constructed or missing all together.
- Technology Failure. You simply cannot make the technology stack work together effectively, which is likely comprised of multiple vendor and open source tools.
What is an organization to do once they inherit one of these second surgery data science engagements? How does the organization re-establish credibility with business leadership that value can still be delivered? Welcome to the MVE methodology!
Minimum Viable Effort (MVE) Methodology
Everyone in the technology industry has heard of Minimum Viable Product (MVP). A Minimum Viable Product (MVP) is a concept from the book “Lean Startup” by Eric Ries that highlights the power of rapid learning by creating a minimalist but useful product which 1) facilitates customer and market validation, and product requirements prioritization with 2) the least amount of development effort.
MVP works great when dealing with a clean slate, but how does the concept work in a second surgery situation where something has already been tried and failed, and the confidence of your stakeholders is already stressed?
No customer wants to hear that one is putting minimal effort into building a solution for them; however, that is exactly what is needed in these second surgery situations. Organizations need to embrace a “rapid, low-load yet effective” data science methodology which 1) facilitates customer requirements, validation, and prioritization with 2) minimal but well-orchestrated collaboration with key stakeholders via 3) a laser-focused analytic model development effort.
Note: If the “Minimum Viable Effort” term really bothers you, maybe think of it as the “Minimum Viable Effort for Customer Success”, though MVEFCS is a little long…
Given the likely investments in time and money that the business stakeholders have already invested in this failed effort, MVE is about laser focusing the data science development effort so that there are no or little wasted development work on requirements that are not central to the stakeholder’s business or operational success. The data science team has to be uber-efficient and highly focused on understanding the fundamental level of data engineering and data science effort required to deliver business relevance and success to the business stakeholders.
There is no time for green bananas.
The Role of the Hypothesis Development Canvas
The Hypothesis Development Canvas is a tool that our data science team uses before we ever “put science to the data”. The Hypothesis Development Canvas ensures that the data science team thoroughly understands the use case they are addressing, the metrics and Key Performance Indicators (KPI’s) against which progress and success will be measured, the sources of business, customer and operational “value”, the prioritized decisions and supporting predictive and prescriptive actions, and potential impediments and risks associated with the use case (see Figure 1).

Figure 1: Hypothesis Development Canvas version 2.0
We have successfully used this canvas on several engagements and have received constructive feedback that we have worked into version 2.0. Heck, Jason Arnold even sent me a spreadsheet version that he created which can be found and download from my DeanofBigData.com website. Thanks Jason!
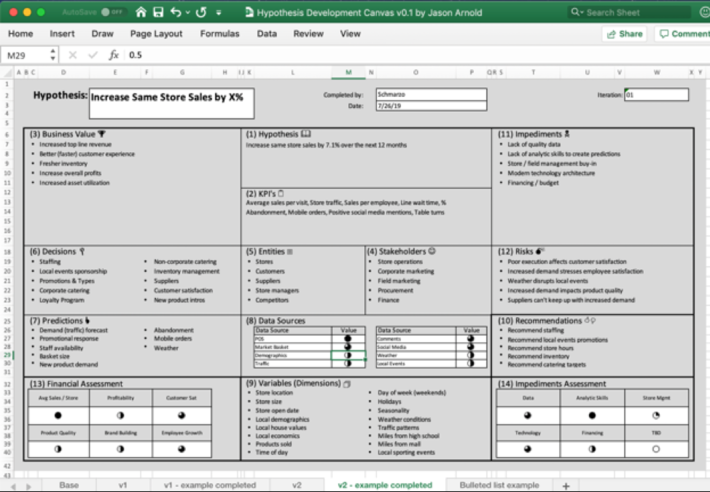
Figure 2: Spreadsheet Version of Hypothesis Development Canvas
Now, let’s see how the Hypothesis Development Canvas can provide the framework to support our MVE approach to salvaging data science second surgery opportunities.
#1: Relevance Failure? Quantifying Sources of Use Case “Value”
Many data science projects get off on the wrong foot by not clearing understanding and quantifying the value of the use case in which they are trying to solve. That is, is the use case the data science team is trying to solve of business relevance or importance to the organization?
While engaging with the business stakeholders to ask these basic value questions may not be appetizing in a second surgery situation, below are kinds of value that needs to be considered:
- Financial Value including Return on Investment (ROI), Internal Rate of Return (IRR), and Net Present Value (NPV).
- Customer Value including Net Promoter Score (NPS), Customer Satisfaction Score, Likelihood to Recommend, and Advocacy Score).
- Operational Value including improving safety, improving availability and operational uptime, reducing maintenance and inventory costs, increasing energy efficiency, reducing waste and re-work, and optimizing yield.
- Environment Value including reducing carbon emissions, reducing operational waste, and reducing one’s carbon footprint.
- Society Value including improving quality of life, improving safety, reducing traffic delays, and improve service reliability and predictability.
Tying the sources of value – and the metrics and KPI’s against which progress and success will be measured – back to the specific use case is critical for establishing relevance to the key stakeholders (see Failure #1 image).
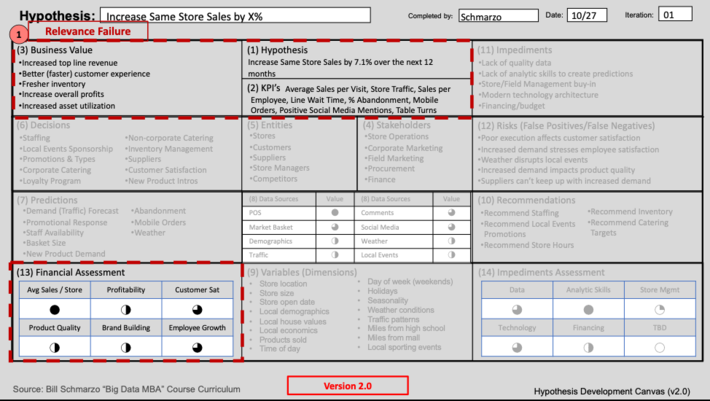
Failure #1: Relevance Failure
#2: Adoption Failure? Building Stakeholder Support
Adoption Failure occurs when key stakeholders don’t actually use the resulting analytics. Many times, adoption failure occurs at the very beginning of the project due to lack of early stakeholder involvement and buy-in. Also, the data science project requires active stakeholder participation throughout the life of the data science project to ensure that the end results are useful and actionable by the stakeholders. Be sure that you confirm with the stakeholders the metrics and KPI’s against which they – the key stakeholders – will be measured. No stakeholder buy-in; no data science success (see Failure #2 image).
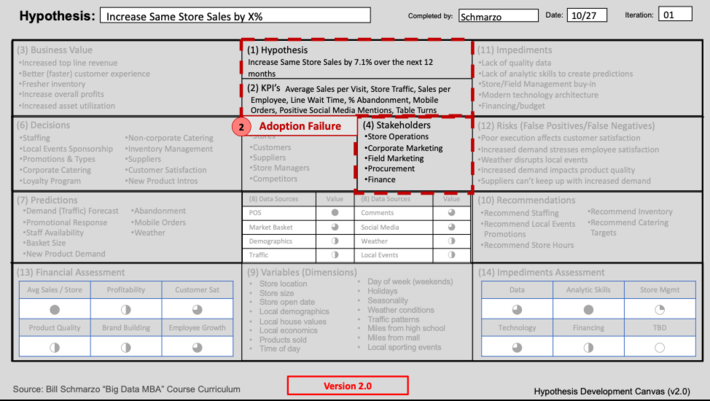
Failure #2: Adoption Failure
#3: Actionability Failure? Creating Actionable Insights
Actionability Failure occurs when the data science project fails to deliver analytics in a form or format in which the users can easily and seamlessly act on them. Forcing stakeholders to interpret a complex chart and search for the right action is a guaranteed path to data science failure. Understandable analytics are necessary in order for the users to trust and then act on the analytic results (see Failure #3 image).

Failure #3: Actionability Failure
This is also an area where Design Thinking techniques (personas, storyboards, journey maps, mockups, etc.) can be invaluable in ensuring that the analytics are delivered in a form and format that is useable by the key stakeholders. However, be warned that you have already stressed the stakeholder relationship, so taking them through a full-blown design thinking exercise is a good way to guarantee that you’ll soon be seeking a new job. Remember, minimum viable effort… See “Interweaving Design Thinking and Data Science to Unleash Economic V…” for more details on the role of Design Thinking.
#4: Impediments Failure? Preparing for Inevitable Impediments
Impediments Failure typically occurs when the data science team has not thoroughly documented and vetted the potential impediments to success. These impediments to data science success can include data availability and quality, data engineering and data science competencies, a “think like a data scientist” trained business stakeholder community, and lack of management fortitude to address passive aggressive behaviors and knock down the organizational silos (see Failure #4 image).
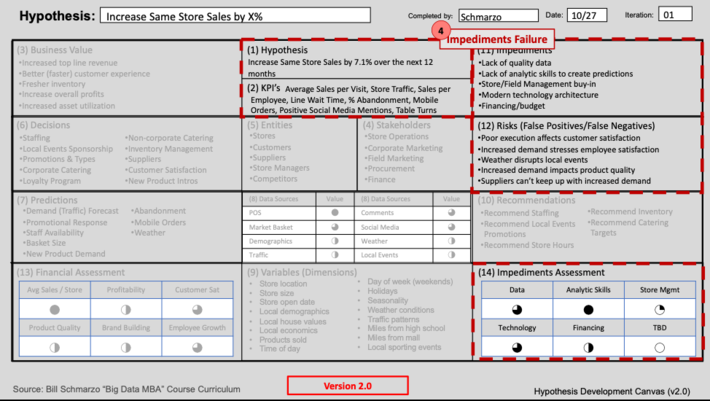
Failure #4: Impediments Failure
Note: all projects struggle at some point because of unknown unknowns. That’s a face, Jack. So, set stakeholders’ expectations for these inevitable project stumbles at the beginning of the project. If the use case is valuable enough to their business, then they will likely work with you during these tough times. However, if the use case is not relevant to them, well, see Failure #1.
#5: Data Failure? Understand What Data You Do and Do Not Need
Data failures typically occur when the data science project is already underway before the data science team realizes that the data that they need is not available at the right levels of granularity, latency, completeness and/or accuracy (see Failure #5 image).

Failure #5: Data Failure
We use the “Implementation Feasibility Mapping” (Figure 3) when we work with the key stakeholders to identify and score the potential implementation impediments before we ever put science to the data.

Figure 3: Implementation Feasibility Mapping
#6: Technology Failure? Embrace a Disposable Technology Mentality
The Hypothesis Development Canvas won’t directly help with technology failures other than identifying what data engineering and data science capabilities are needed. However, organizations need to be careful not buy technologies that lock you into proprietary architectures and platforms. Architectural agility is everything in the fast-moving world of data science (see Figure 4).

Figure 4: Disposable Technology: A Concept Whose Time Has Come
What lessons can we learn from how digital companies like Google, Apple, Facebook and Amazon approach technology?
- Lesson #1:Focus on aligning the organization on identifying, capturing and operationalizing new sources of customer, product and operational value buried in the company’s data.
- Lesson #2:Don’t implement a rigid technology architecture that interferes with Lesson #1.
See the blog “Disposable Technology: A Concept Whose Time Has Come” for more details on not turning technology into a liability.
Second Surgeries and Minimum Viable Effort (MVE) Summary
Many of these Data Science failures can be avoided or mitigated with a thorough understanding of the business, analytic, data and organizational requirements for success. The Hypothesis Development Canvas is an important part of defining data science success. It is so important to data science success, that I dedicate an entire chapter to understanding and mastering it in my new workbook – “The Art of Thinking Like a Data Scientist.“
I hope your organization can avoid data science second surgery situations, but the odds say that you won’t. So be prepared to leverage the MVE methodology to resurrect failed data science projects and address the 6 data science failures.
Blog key points:
- Data Science “second surgery” opportunities are materializing due to the high rate of data science project “failures”. These “failures” typically fall into six categories.
- The Data Science “second surgery” challenge: How to best re-start your data science initiatives after you’ve worn out your credibility and the patience of your stakeholders.
- Introducing the Minimum Viable Effort (MVE) data science methodology as a means of resurrecting data science “second surgery” situations.
- The Hypothesis Development Canvas was originally developed to ensure that you understand the business or operational requirements for a successful data science initiative.
- The MVE methodology leverages the Hypothesis Development Canvas to 1) identify the requirements gaps to data science success and 2) minimize stakeholder load while 3) delivering a set of stakeholder relevant and actionable analytic results.
- There is much value engineering work that needs to be done in understanding the use case before one ever puts science to the data.
- There is no time for green bananas.
{kind=link}