
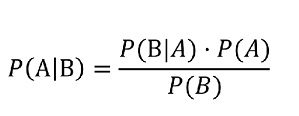
Data Scientists worldwide are forecasting about COVID
Mostly, they are doing excellent work.
But still, most forecasts vary widely
That’s not to say that they are inaccurate
There are a few inherent reasons for this
Firstly, the lack of domain knowledge in epidemiology and biostatistics. Most data scientists lack knowledge in epidemiology and biostatistics essential for COVID-19 forecast.
But assuming that you do acquire the knowledge, most models are only as good as the data – and there is very little data.
Hence, most models apply data from other contexts / geographies.
For example, UK models are based on data from Italy
There are four basic elements used to model most disease outbreaks:
- The number of people each infected individual will subsequently infect in the early stages of the outbreak, the R0,
- The duration of the outbreak
- The case fatality ratio, the probability that an infected person dies and
- The asymptomatic ratio
All of these rely on data which is not perfect and not necessarily applicable across geographies
Moreover, it depends on what features the model will emphasise
In the UK, the two best known models (Imperial college and Oxford) emphasise different elements and come to different conclusions as to the spread(but both agree on social distancing) ref Bloomberg – It helps to understand what goes into Imperial and Oxford’s predictive coronavirus models, and what they can and can’t do.
Hence, a model cannot really say where COVID-19 will explode next – even though it could tell us likely scenarios.
For the ‘where next’ element – we need contact tracing to capture the data
So, this all points to the need for data for models whichever way you look at it
With one exception
Would a Bayesian approach yield better results under the circumstances?
Isaac Faber – whose insights I recommend – says
Modelling for the pandemic has shown that this debate should still be front and center. The frequentists are mostly in the spotlight advising world leaders. If you listen close you will hear a common refrain ‘we just need more data.’ This is, of course, the age-old problem of statistical significance. However, today, we aren’t in a harmless lab study, these data are only realized through death. This, more than any other argument, shows how dangerous frequentist methods are in practice. The methods don’t give you enough confidence when you need it the most. You need to wait for a sufficient pile of bodies. This probably contributed to why many gov’ts were slow to act; their advisors didn’t have enough data to be confident. The Bayesian has no problem acting quickly with expert judgment (a prior belief) and small data. Want to join the Bayesians? Start here:
This sounds like taking the familiar frequentist vs Bayesian debate post COVID
I don’t know how accurate this line of thinking is .. but its certainly worth exploring
Its also an excellent way to illustrate these two approaches from a problem-solving / teaching perspective
{kind=link}