
Pooled, also referred to as “converged”, clusters in a unified data environment support disparate workload better than separate, siloed clusters. Vendors now provide direct support for converged clusters to run key HPC-AI-HPDA (AI, HPC, and High Performance Data Analytic) workloads.
The success of workload optimized compute servers has created the need for converged clusters as organizations have generally added workload optimized clusters piecemeal to support their disparate AI, HPC, and HPDA needs.
Unfortunately, many disparate clusters operate in isolation, dedicating their resources for specific workloads and managed by humans, essentially placing them in a silo that prevents their benefitting the entire organization. This makes little sense from an operating efficiency perspective as it wastes both operation time plus OpEx (operating expense) and CapEx (capital expense) monies.[i]
Most organizations, for example, don’t run their infrastructure for deep learning networks on a 24×7 basis. The part-time nature of these workloads means that this special-purpose infrastructure often stands idle and may require rarefied skills to support, both of which can be costly to the business.
This leads to the following observation about the benefits of a converged infrastructure.
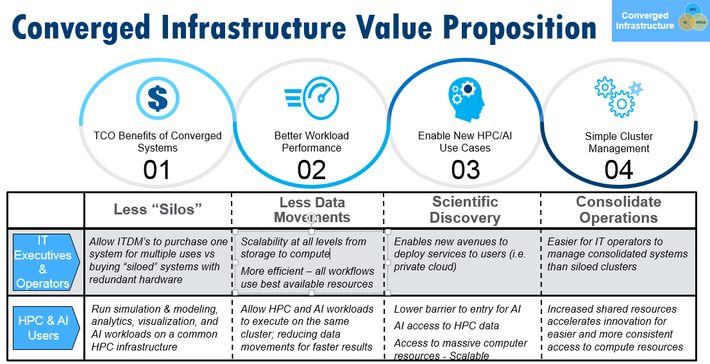
Figure 1: Benefits of converged clusters
Maximizing the benefit of high-performance servers – a wonderful challenge to address
It’s wonderful to have a problem where the performance of individual optimized workstations and servers have scaled-up the performance of targeted workloads to meet or exceed the teraflop/s performance of TOP500 compute clusters from even a few years ago. Now the hero runs of yesteryear are a nominal run today on scaled-out clusters containing numbers of these workload optimized servers.
Meanwhile, cloud computing has moved out of the experimental phase for HPC to support greater than million core runs on AI and other workloads,[ii] which has brought leadership class HPC, AI, and HPDA to the masses. The cloud has driven the rapid maturation of new tools and software ecosystems which, in turn, have increased the power and performance of workload-optimized systems. Thus, the cloud is a factor, and must play a role, in the convergence of HPC-AI-HPDA in today’s HPC and enterprise datacenters.
Following are some high visibility example HPC systems that run HPC-AI-HPDA workloads.

Figure 2: Example systems running AI and HPC workloads
The challenges of convergence
The main problem with running all three workloads (e.g. HPC-AI-HPDA) on the same cluster is that it is difficult to load the custom software stacks on the cluster at the right time. Even with containers, most organizations deploy on silos because then the cluster has the right software at the right time.
HPC-AI-HPDA workloads stress the storage and network subsystems differently both at the hardware and systems software level. Thus, having the right software does not mean just having the right libraries and optimized tools installed as the right systems software must also be installed to utilized workload specific hardware capabilities. [iii] [iv]
Storage is different
AI and HPDA workloads tend to read far more frequently from storage than write, plus data access tends to be streaming (e.g. bandwidth limited) or heavily random access (iop/s limited) – especially when working with databases and unstructured data. HPC workloads, in contrast, tend to write far more frequently. Checkpoint operations in particular have caused the development of write-optimized burst buffers in HPC systems. These performance extremes tend to drive differing hardware designs.
Different HPC Schedule Requirements
AI and HPDA runs tend to queue up jobs rather than scheduling a block of time as with an HPC run. A common HPDA run occurs when a research scientist wants to perform an exploratory analysis on simulation data in interactive mode. Typically, Spark is a very good choice of tool for that. The ideal way to do that in an HPC environment is to spin off a Spark cluster using an interactive sbatch command. However, interactive runs are discouraged in HPC centers because they tie up resources when there are many people waiting in the queue.
To support data-oriented workflows on HPC systems, LLNL developed Magpie. Magpie is an open-source project for running big data frameworks on HPC systems. It supports popular big data frameworks such as Hadoop, Spark, HBase, Storm, Zeppelin, Kafka, Pig, and Zookeeper on HPC systems using Slurm, Moab, Torque, and LSF job schedulers.
Magpie can be submitted via sbatch. As shown below, it sets up a Spark cluster on all the nodes and checks the environment variable setup and input parameters. The rank zero MPI node becomes the Spark master, starts the daemons and performs other setup so the research scientist can connect to the spark master and use a Jupyter notebook or other interactive tool to get the work done.
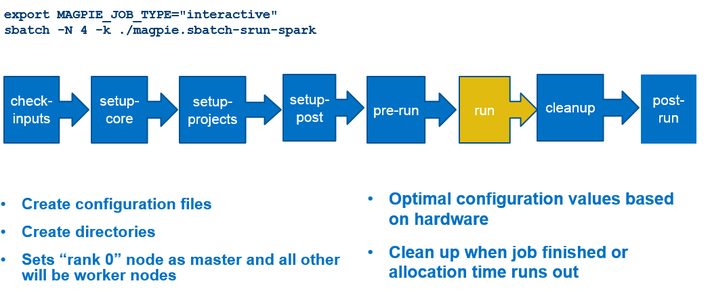
Figure 3: Configure a Magpie data analytics run using SLURM
Vendors also support other approaches such as the Univa Grid as discussed in the technical report Supporting Simulation and Modeling, AI, and Analytics on a Common P….
Other hardware challenges
Other challenge discussed in these technical reports include addressing the lack of optimization in cloud and AI frameworks for high-end HPC communications fabrics. Other reports in the literature include challenges with memory capacity challenges on HPC systems as stochastic training methods like SGD (Stochastic Gradient Descent) can cause large memory usage on some nodes. [v]
The three pillars of converged workloads: Data, Software, and Platform
The need for a converged architecture can be summarized in three pillars shown below. The first two were discussed previously (e.g. optimized servers and HPC scheduler support). Succinctly, they provide the ability to efficiently run all the converged workloads 24/7 on the clusters. The third pillar will be discussed next, to tie all the converged clusters together inside a unified data abstraction.
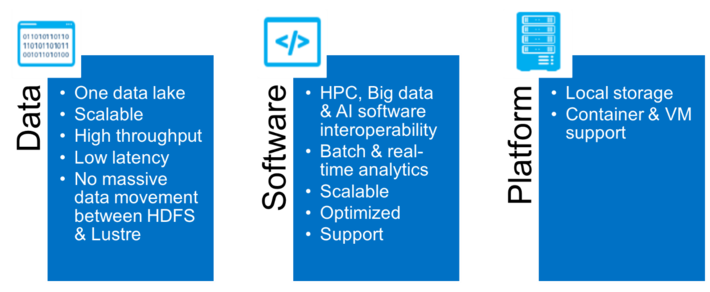 Figure 4: The three pillars of converged systems
Figure 4: The three pillars of converged systems
Reducing brittleness and data movement requires a unifying storage abstraction
It is essential that the converged system present a unified view to the data. Otherwise the system becomes brittle due to human error (such as incorrect path names in the scripts that access data) or spends inordinate amounts of time moving data between clusters. One solution many vendors recommend to provide a unified storage abstraction is the open-source Alluxio storage abstraction software.
Alluxio is an open-source project that was started as a sub-project of Spark. As seen below, it acts as a data layer between a variety of popular compute and storage implementations. It was designed to provide a distributed cache service that abstracts the storage layer so users can work with cloud, object, or block storage.
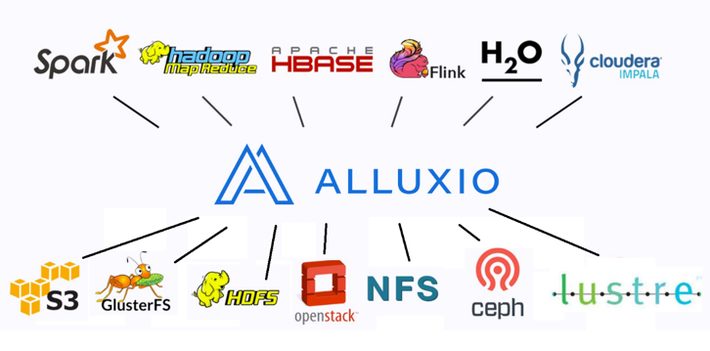
Figure 5: Alluxio provides a unified data abstraction
Summary
Succinctly, running AI and HPDA on HPC systems has clear advantages, which means both data science and HPC organizations must now support HPC-AI-HPDA workloads. Vendors now support the vision to pool multiple HPC-AI-HPDA clusters together inside a unified data environment to save money and user pain.
Rob Farber is a global technology consultant and author with an extensive background in HPC and in developing machine learning technology that he applies at national labs and commercial organizations. Rob can be reached at [email protected].
[i] The Case for Running AI and Analytics on HPC Clusters
[ii] https://aws.amazon.com/blogs/aws/natural-language-processing-at-cle…
[iii] Supporting Simulation and Modeling, AI, and Analytics on a Common P…
[iv] The Case for Running AI and Analytics on HPC Clusters
[v] https://www.hpcwire.com/2018/05/09/data-management-nersc-era-petasc…
{kind=link}