
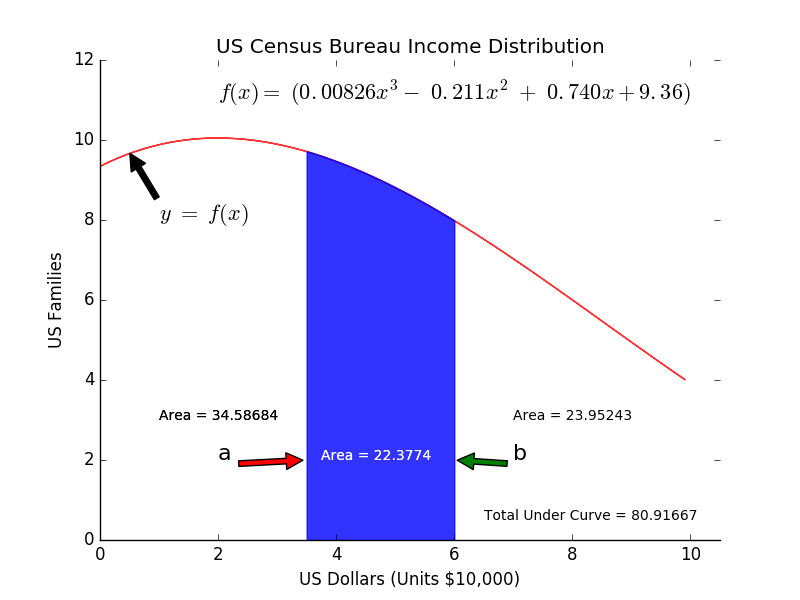
In short, an ontology is the specification of a conceptualization. What does that mean from the perspective of the information sciences? Wikipedia’s definition: “formal naming and definition of the types, properties, and interrelationships of the entities that really or fundamentally exist for a particular domain of discourse.” This basically means, like all models, that it is a representation of what actually exists in reality. A statistical or mathematical model attempts to represent some behavior in terms of a statistical or mathematical formula. The equation shown in the figure below is from the US Census Bureau and models the distribution of incomes in the United States for people making $100,000 per year or less:
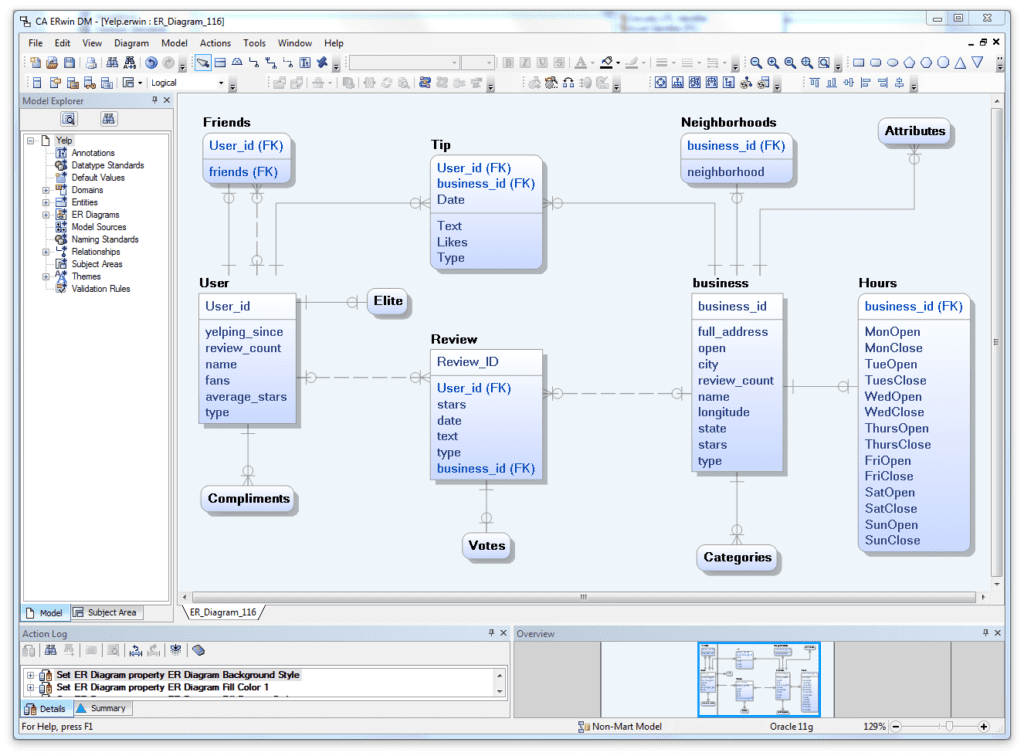
The Erwin Entity Relationship (ER) diagram below is a model that represents a JavaScript Object Notation (JSON) object showing the entities User, Friends, Business, Neighborhoods, along with their relationships with each other. This is more of a logical representation, but it depicts data that actually exists, materially or conceptually within this JSON object:

- JSON ER Logical Model
An Ontology model provides much the same information, except a data model is specifically related to data only. The data model provides entities that will become tables in a Relational Database Management System (RDBMS), and the attributes will become columns with specific data types and constraints, and the relationships will be identifying and nonidentifying foreign key constraints. What a data model does not provide is a machine-interpretable definition of the vocabulary in a specific domain. Data Models will not contain vocabulary that defines the entire domain, but rather the data dictionary will contain information on the entities and attributes associated with a specific data element. This is where ontologies come in.
The following figure shows the Friends of a Friend (FOAF) ontology loaded into the Protégé application (open source ontology editor and a knowledge management system from Stanford University) :
- FOAF Ontology loaded into Protege
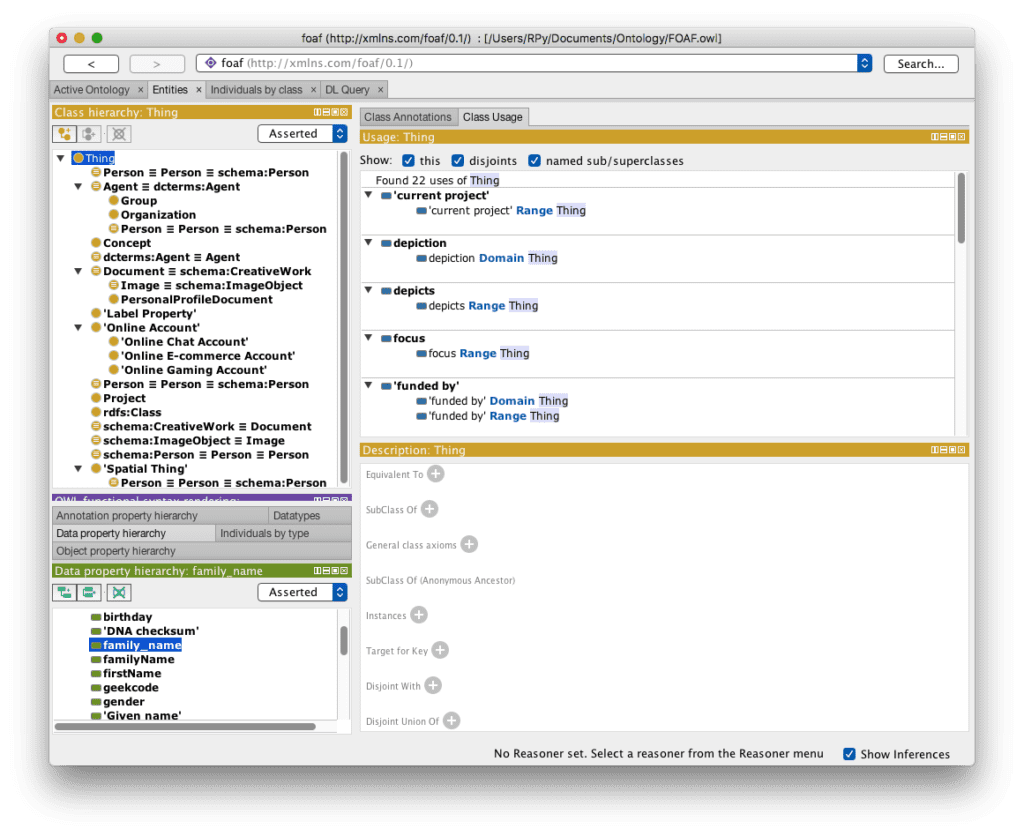
The FOAF ontology is an open source ontology used to exchange information about persons, their activities, and relationships to other people and objects. An ontology consists of classes hierarchically arranged in a taxonomy of subclass-superclass, slots with descriptions defining value constraints, and values for these slots. A knowledge base is defined when the ontology is complete, and when individual instances of these elements (classes and slots) are defined and any restrictions added or refined.
For example, the class person includes all people, and a specific person is an instance of this Class. Most ontologies are focused on Classes of things, and these Classes can be broken up into Subclasses of things. For example, Person can be subclassed into Gender, Ethnicity, Race, or Country of Citizenship. Defining domains in terms of machine-readable ontologies will allow the free exchange information and knowledge.
So why do we need ontologies, and what is their significance?
Ontologies enable the sharing of information between disparate systems within the same domain. There are numerous freely available ontologies from various industries. Ontologies are a way of standardizing the vocabulary across a domain. For example, the word “practitioner” will have the same meaning in one healthcare system as it has in another. Likewise, a practitioner “specialty” will be the same attribute and have the same meaning on both sites. This standardization allows for more flexibility, and will enable more rapid development of applications, and sharing of information.
Ontologies are used in many disciplines, but are most commonly associated with Artificial Intelligence (AI), and possibly Natural Language Processing (NLP) applications. However, a less likely application of ontologies, and an area of interest for me is with Data Integration and Knowledge Management systems.
So why haven’t ontologies been the big buzz word like Hadoop, Spark, and Big Data? Technologies expand in the areas that it can and where there’s a market, not necessarily in the areas most needed. Ontologies won’t lend themselves to enterprise level applications, and developing multiple ontologies is just not that exciting. For one thing, it requires cooperation between groups within a domain to standardize on a common ontology for communication. The financial industry has made an attempt at this with the development of the Financial Industry Business Ontology (FIBO), but its adoption has been slow. One reason for this is that the power of ontologies is not well understood.
To take the next leap in technology advancement will require mature software, capable of rapidly ingesting, understanding, analyzing, and presenting interpretable results; this is where ontologies come in. In my opinion, ontologies will be the enabler of the next generation of disruptive technologies.
Artificial Intelligence and Natural Language Processing Applications:
Voice recognition systems like Amazon’s Echo, Apple’s Siri, and Google Home are very sophisticated, but at the same time, immature technologies. It is not for the lack of hardware processing speeds that we have laughed, or been frustrated when asking one of these devices a simple question, only to receive some nonsensical response. We are capable of writing the code to answer questions correctly, if we have the information needed to properly interpret the question.
Computers are good at computing, but not so good at cognitive processing. Computers struggle with the inherent difficulty of performing human-like tasks that we take for granted. These human-like tasks appear very simple, but are actually quite difficult to emulate on a computer. IBM’s Watson is probably the most advanced in these areas, but there is still a long way to go.
When a human sees a picture of a cat, we immediately identify the figure as being a cat. When asked “What can I do for my cold?”, we immediately understand that the word “cold” in this context is referring to a common viral illness. Ask Siri this same question, and it pulls up a Wikipedia page explaining “cold” in the sense of temperature. However, if you type in a Google search for the same question, you get what would be expected (more on Google search below).
Examining the word “cold” as an adjective in Wordnet, you will see that it has thirteen different senses as an adjective, but only three as a noun; everything from “a cold climate” (cold vs hot), to “cold in his grave” (lacking the warmth of life), to “will they never find a cure for the common cold?” (a mild viral infection involving the nose and respiratory passages, but not the lungs). In linguistics, this is the polysemy count, or the coexistence of possible meanings for a word or phrase. So, for Artificial Intelligence (AI) and Natural Language Processing (NLP) applications, ontologies are a critical component.
Data Integration and Knowledge Management Applications:
However, there are other ontology applications that I find just as interesting, and these are in the area of Data Integration and Knowledge Management. The video below explains Google’s Knowledge Graph better than I ever could, so please, check it out.
One critical component of AI, NLP, Data Integration, Knowledge Management, and other applications is the development of ontologies. Hopefully, from the discussion above, and with some help from Google, you understand better my interest in this area. Ontologies are domain specific, they define that domain with words that define entities, relationships between those entities, and the attributes and properties associated with that entity, and present this material in a machine readable format.
As for data integration and ontologies, there are several articles I could direct you to for a more in depth discussion of the topic. One in particular, “Really, Really Big Data: NASA at the Forefront of Analytics” by Seth Earley details how NASA used ontologies to define the data sets in terms that could be interpreted and enable integration with external data sets.
As a career data architect, I have worked in the military, financial, insurance, manufacturing, and healthcare industries. In each of these, the same problem exists, silos of isolated data. Data is not easily shareable across these silos — horizontal integration of data is difficult if not impossible. Data in banking is isolated from insurance, health records are isolated from billing and claims, logistics is isolated from operations, and on and on it goes. This is not an uncommon problem, and there is a cure, and, again, in my opinion, ontologies will provide the solution.
We have Big Data platforms running Hadoop, and we have numerous components like MapReduce, Spark, Mahout, H2O Sparkling Water, and Kafka that enable us to access and analyze this data, but the fact still remains that you must know the data before you can analyze it. Ontologies provide a mechanism for quickly ingesting data from a Data Lake, and making sense of it.
So, like hardware advancing faster than software can exploit the power, the capability to manage Big Data and provide Analytical solutions has come before our ability to rapidly understand and ingest data. Whether schema-on-read, or write, you must know your data. Understanding data is a complicated, and time consuming task. Developing ontologies will help us more quickly understand a domain and accelerate the evolutionary process.
{kind=link}