
Does Big Data mean Hadoop? Not really, however when one thinks of the term Big Data, the first thing that comes to mind is Hadoop along with heaps of unstructured data. An exceptional lure for data scientists having the opportunity to work with large amounts data to train their models and businesses getting knowledge previously never imagined. But has it lived up to the hype? In this article, we will look at a brief history of Hadoop and see how it stands today.
2015 Hype Cycle – Gartner
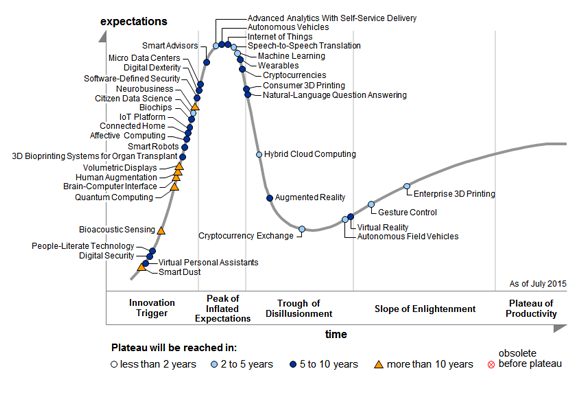
Some key takeaways from the Hype cycle of 2015:
- ‘Big Data’ was at the Trough of Disillusionment stage in 2014, but is not seen in the 2015 Hype cycle.
- Another interesting point is that ‘Internet of Things’ which suggests a network of interconnected devices around us, is at peak for 2 years consistently now.
Just to check on the relevance of the Hype Cycle sitting in India, I check the Google trend for the terms ‘Big Data’ and ‘Hadoop’, and here are the results:
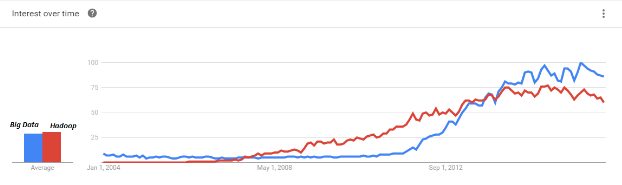
So there is definitely a fall after a point of inflection in 2014-2015.
Brief History of Hadoop
Here is an excerpt from a recently published article by Alexey Grishchenko earlier this year:
- Hadoop was born by Google’s ideas and Yahoo’s technologies to accommodate the needs for distributed compute and storage frameworks by biggest internet companies. 2003-2008 are the early ages of Hadoop when almost no one knows what it is, why it is and how to use it;
- In 2008, a group of enthusiasts formed a company called Cloudera, to occupy the market niche of “cloud” and “data” by building commercial product on top of open source Hadoop. Later they abandoned the “cloud” and focused solely on “data”. In March 2009 they have released their first Cloudera Hadoop Distribution. You can see this moment on the trends diagram immediately after 2009 mark, the raise of Hadoop trend. This was a huge marketing push related to the first commercial distribution;
- From 2009 to 2011, Cloudera was the one who tried to heat the “Hadoop” market, but it was still too small to create a notable buzz around the technology. But first adopters has proven the value of Hadoop platform, and additional players has joined the race: MapR and Hortonworks. Early adopters among startups and internet companies are starting to play with this technology at this time;
- 2012 – 2014 are the years “Big Data” has became a buzzword, a “must have” thing. This is caused by the massive marketing push by the companies noted above, plus the companies supporting this industry in general. In 2012 alone, major tech companies spent over $15b buying companies doing data processing and analytics. But the demand for “big data” solutions were growing, and the analyst publications were heating the market very hard. Early adopters among enterprises are starting to play with the promising new technology at this time;
- 2014 – 2015 are the years “Big Data” is approaching the hype peak. Intel has invested $760m in Cloudera giving its the valuation of $4.1b, Hortonworks went public with valuation of $1b. Major new data technologies has emerged like Apache Spark, Apache Flink, Apache Kafka and others. IBM invests $300m in Apache Spark technology. This is the peak of the hype. These years a massive adoption of “Big Data” in enterprises has started, architecture concepts of “Data Lake” / “Data Hub” / “Lambda Architecture” have emerged to simplify integration of modern solutions into conventional infrastructures of enterprises.
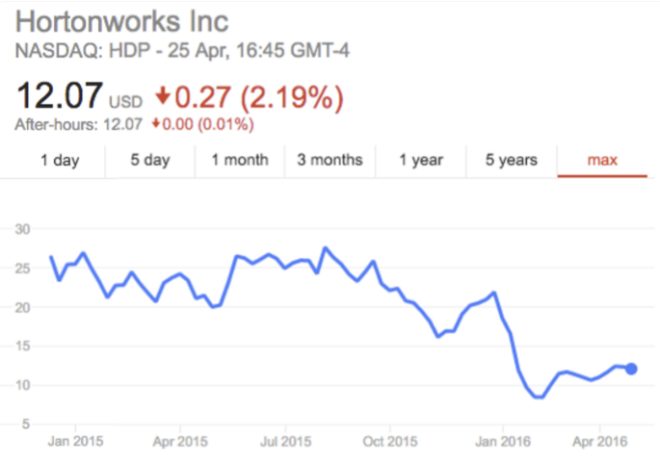
- 2016 and beyond – this is an interesting timing for “Big Data”. Cloudera’s valuation has dropped by 38%. Hortonwork’s valuation has dropped by almost 40%, forcing them to cut the professional services department. Pivotal has abandoned its Hadoop distribution, going to market jointly with Hortonworks. What happened and why? I think the main driver of this decline is enterprise customers that started adoption of technology in 2014-2015. After a couple of years playing around with “Big Data” they has finally understood that Hadoop is only an instrument for solving specific problems, it is not a turnkey solution to take over your competitors by leveraging the holy power of “Big Data”. Moreover, you don’t need Hadoop if you don’t really have a problem of huge data volumes in your enterprise, so hundreds of enterprises were hugely disappointed by their useless 2 to 10TB Hadoop clusters – Hadoop technology just doesn’t shine at this scale. All of this has caused a big wave of priorities re-evaluation by enterprises, shrinking their investments into “Big Data” and focusing on solving specific business problems.
Prospect Dampeners
Gartner conducted this survey with 284 companies, with only 125 stating that they had already invested in Hadoop, or were looking to invest within the next 2 years. The release can be found here:http://www.gartner.com/newsroom/id/3051717.
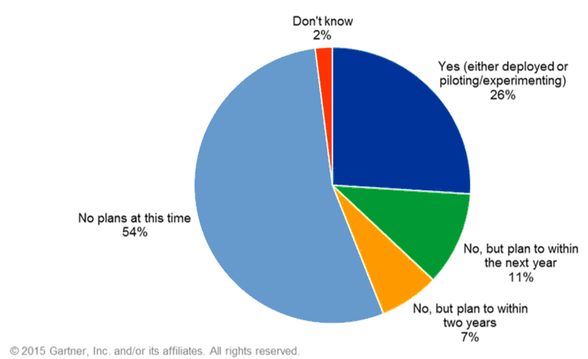
- 54% respondents have no plans to invest at this time.
- 26% only are deploying or piloting with Hadoop
- 11% plan to invest within 12 months
- 7% plan to invest within 24 months
Possible Factors
Skills Gap
57% respondents in the survey cited Skills Gap as the major reason for not adopting, and 49% were still trying to figure out the value deriving process. While Gartner estimates that it would take 2 years for finding the right number of people with the needed skills, Hadoop distribution providers are working on creating more user friendly and integrated modules and interfaces. However, these still do not seem to be friendly enough for the average user.
RoI / Priority
As organizations will have to get busy figuring out ways to incorporating new processes, hiring skilled individuals, Hadoop or Big Data deployment is taking a backseat. Traditional database providers have evolved their products be it in-memory or Massive Parallel Processing systems, which stay good enough to get the job done for most times, or even better than Hadoop for some applications. For instance, this experiment was conducted at Airbnb comparing a Amazon Redshift 16 node cluster with a 44 node Hive/Hadoop EMR cluster, and the SQL based Redshift outperformed the EMR cluster. The study was done in 2013, and Hadoop has evolved from then with Hive on Yarn, Apache Impala and so on, however this does not change the fact that Hadoop wasn’t built as a database for performance optimized structured data querying, unless the data is in Petabytes of course.
When the need arises to create something sort of a data mart, the lure towards ‘complicating’ things with Hadoop is something to be debated. Keep in mind, most enterprises have teams who take ownership of social media and other such unstructured information on the digital medium. And there are numerous awesome solutions to do digital data tracking and brand monitoring and what not in real time. Point is Hadoop would be low priority in all such scenarios.
Integration
Another important question which would need a large qualitative analysis – Can Hadoop coexist peacefully with an existing data warehouse? If so, how? Offloading processes (even for parts) would have million dollar price tags for the enterprise.
After that bit, the dilemma exists of hosting a cluster but not building any legacy systems versus going cloud. Majority of Cloudera’s customers host their own clusters with a minority being on the cloud. The major options here are a. hosting on premise / leasing data center b. IaaS (Infrastructure as a Service) such as Amazon Web Service, Google Cloud Platform etc , and c. Now emerging Hadoop as a Service.
Expensive to host on premise, cloud based providers such as Amazon EMR require skills of not only Hadoop but also understanding the Amazon version of the ecosystem. Hard to find. Hadoop as a Service providers are still fine tuning their products and will take some time maturing for the enterprise.
Emergence of the Cloud
In the points list above, Skills Gap and RoI/Priority are something which will evolve over time. They are related to each other, and as organizations see value, they will either hire or train people for these skills which are very much attainable. But what will be interesting to see in the next few years is the emergence of cloud based solutions for Hadoop to fine tune integration for the enterprise.
SAP is acquiring Altiscale as reported on SAP reportedly buying Altiscale to power big data services. Altiscale being one the early providers of Hadoop on the Cloud.
Another interesting recent development is Cloudera asked Intel for $1 billion to build a cloud service. The Hadoop distribution market leader – Cloudera is pushing towards going cloud and gain some market share of the Big Data workloads from current leaders in the Hadoop on the Cloud space – Amazon AWS, IBM BigInsights, Google Cloud Platform, and Microsoft Azure HDInsight.
In summary, as organizations realize the value of Big Data, factors such as skills shortage and integration lead to the slow adoption rates. Moreover, traditional database providers have evolved their services with Massive Parallel Processing systems, In-memory and columnar database solutions which has delayed the realization of the value related to Hadoop. The emergence of cloud based Hadoop service providers provides an alternative way for organizations to incorporate Hadoop clusters for Big Data workloads in the future.
Originally posted here.
{kind=link}