

A few years ago, it was extremely uncommon to retrain a machine learning model with new observations systematically. This was mostly because the model retraining tasks were laborious and cumbersome, but machine learning has come a long way in a short time. Things have changed with the adoption of more sophisticated MLOps solutions.
Now, the common practice of retaining a machine learning model is somewhat reversed. Models are being trained more often and after very short intervals. MLOps solutions have brought about this change with easy access to automation around model retraining, and often the most straightforward approach to trigger retraining is schedule-based.
Should a machine learning model be retrained each time new observations are available (or otherwise very frequently)? Like almost everything else in machine learning, the answer is “it depends.”
There are two components to consider whether you should retrain a model: the use case and the costs. Let’s look at the use case first.
Why Are Models Retrained?
The most basic, fundamental reason for model retraining is that the outside world that is being predicted keeps changing, and consequently the underlying data changes, causing model drift. If comparing the training dataset and a similar set of new data shows a significant deviation, the existing model will no longer hold much value as it cannot make the same generalizations. In other words, the predictions the model makes are no longer as accurate as they were at the time of training.
How and why the underlying data changes, though, depends on the use case. In the scope of this article, we’ll look at three distinct reasons:
- Insignificant data
- Adversarial environments
- Dynamic environments
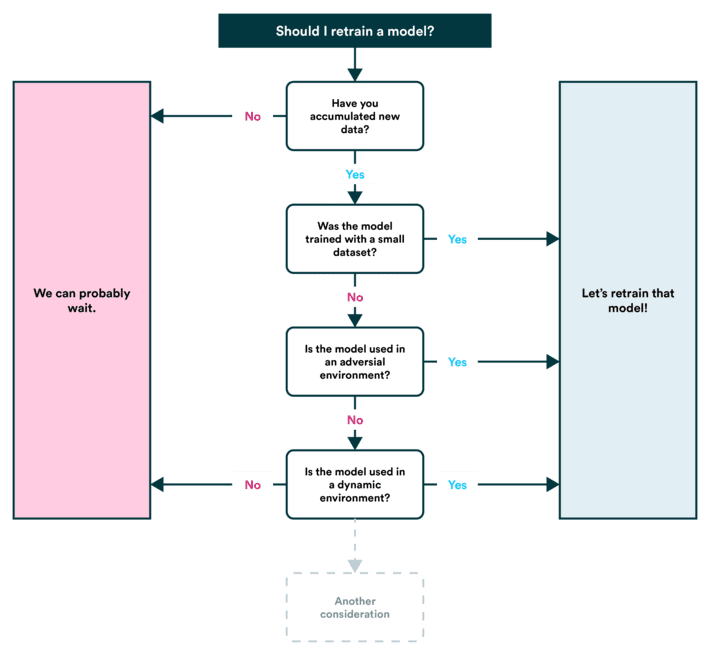
Multiple considerations go into whether retraining a model provides value. Mostly it comes down to whether an environment is dynamic and what the cost of model drift is.
Insignificant data
It may be that initially, the model wasn’t trained with a dataset large enough that it manages to represent real-world data properly. In these cases, the model accuracy may vary significantly between training and testing. By extension, the variance would also hold between training and real-world use. When there is high variance in the model performance, it makes sense to retrain a model with a training dataset that includes new observations and increases its size.
Adversarial environments
In environments where the relationship between the subject and the model is somehow adversarial, model retraining becomes much more critical. In hostile environments, the data scientist is in a constant rat race to catch unwanted behavior, and the cost of wrong predictions may be high. Examples of such domains could be fraud detection, comment moderation, and search engine ranking algorithms.
Dynamic environments
Dynamic environments is an overly broad term and even covers adversarial environments. The term merely describes that in that use case, the underlying data changes over time. It may help break the consideration further and consider the mechanism that changes the underlying data.
For example, if you train a model on user behavior data, the environment is very likely to be dynamic. On the other hand, a use case with sensor data might be seemingly static, but unexpected changes may still occur that change the data, for example, how the sensor is placed changes. Other factors that contribute to a dynamic environment could be:
- Ever-changing customer preference
- Rapidly moving competitive space
- Geographic shifts
- Economic factors
Why Not to Retrain a Model?
The second part of the retraining equation comes down to cost. There is a balance between cost and benefit. Even if there exists such a scenario where retraining with each new observation was necessary, the factors of the cost will put up a significant wall that will ultimately prevent retraining with each new observation. Costs in model retraining include:
- Computational Costs
- Labor Costs
- Implementation Costs
Retraining can be costly from a purely computational perspective, but it is more common to be expensive from a human labor perspective. However, this is where the shift we mentioned at the beginning of the article has occurred. With MLOps systems, such as Valohai, the cost of human labor can largely be eliminated.
An MLOps system will enable setting up a pipeline that retrains, evaluates, and deploys a model without human intervention, and it can be triggered automatically to do. The trigger will most often be schedule-based purely due to the low implementation cost, and when the computational costs are low, redundancy is not a big concern.
In more computationally heavy cases, like deep learning, the cost considerations will be more relevant. More sophisticated monitoring systems will allow teams to trigger retraining more deliberately, and for certain types of models, this will be a must to avoid unnecessary costs.
Key Takeaway

It can help to consider your use case in terms of costs and benefits before building an extensive infrastructure setup to retrain your model frequently. In demanding use cases, the benefits will outweigh the computational cost, and labor cost can easily be eliminated.
The takeaway is that considering the environment and use case is crucial to figuring out the value of retraining a model. Some use cases simply have a much higher requirement for how often a model needs to be retrained. The second part of the equation is the cost, which can be primarily reduced to computational costs – if an upfront investment is made to adopting MLOps infrastructure and building a training pipeline.
If you are interested in learning more about machine learning pipelines and MLOps, consider our other related content. Originally published at https://valohai.com.
{kind=link}