
Introduction
Building data pipelines is a core component of data science at a startup. In order to build data products, you need to be able to collect data points from millions of users and process the results in near real-time. Today, many organizations nowadays are struggling with the quality of their data. Data quality (DQ) problems can arise in various ways. Here are common causes of bad data quality:
- Multiple data sources: Multiple sources with the same data may produce duplicates; a problem of consistency.
- Limited computing resources: Lack of sufficient computing resources and/or digitalization may limit the accessibility of relevant data; a problem of accessibility.
- Changing data needs: Data requirements change on an ongoing basis due to new company strategies or the introduction of new technologies; a problem of relevance.
- Different processes using and updating the same data; a problem of consistency.
In this blog, we are going to look into the world of data lakes and their significance. Furthermore, we will peep into some of the inherent issues in data lakes like quality management. In the end, we will discuss some of the quality measures to control the quality of data in data lakes.
What is Data Lake?
A data lake is a centralized place, like a lake, that allows you to hold a lot of raw data in its native format, structured and unstructured, at any scale. Furthermore, you can store your data as- it is, without having to first structure the data or define it until its needed. Its purpose is for creating reporting dashboards and visualizations, real-time analytics, and machine learning. Also, this can guide better programmatic advertising decisions.
In its extreme form, a data lake ingests data in its raw, original state, straight from data sources. This happens without any cleansing, standardization, remodelling, or transformation. These and other sacrosanct data management disciplines are applicable on the fly. Moreover, it helps in enabling ad hoc queries, data exploration, and discovery-oriented analytics. The early ingestion of data means that operational data is present and made available to analytics as soon as possible. Additionally, the raw state of the data ensures that data analysts, data scientists, and similar users have ample raw material. They can repurpose into many diverse data sets, as needed by unanticipated analytics questions.
Components of Data Lake
A Data Lake is a platform combining a number of advanced, complex data storage and data analysis technologies.
To simplify, we might group the components of a Data Lake into four categories, representing the four stages of data management:
- Data Ingestion and Storage, that is the capability of acquiring data in real time or in batch, and also the capacity to store data and make it accessible.
- Data Processing, that is the ability to work with raw data so that they’re ready to be analysed through standard processes. It also includes the capability of engineering solutions that extract value from the data, leveraging automated, periodical processes resulting from the analysis operations.
- Data Analysis, that is the creation of modules that extract insights from data in a systematic manner; this can happen in real time or by means of processes that are running periodically.
- Data Integration, that is the ability to connect applications to the platform; in the first place, applications must allow querying the Data Lake to extract the data in the right format, based on the usage you want to make of it
Why use Data Lakes
1. Data Indexing
Data Lakes allow you to store relational data (a collection of data items organized as a set of formally-described tables from which data can be accessed or reassembled in many different ways without having to reorganize the database tables.) — operational databases (data collected in real-time), and data from line of business applications, and non-relational data like mobile apps, connected devices, and social media. They also give you the ability to understand what data is in the lake through crawling, cataloguing, and indexing of data.
2. Analytics
Data Lakes allow data scientists, data developers, and operations analysts to access data with their choice of analytic tools and frameworks. This also includes open source data frameworks such as Apache Hadoop, Presto, and Apache Spark, and commercial offerings from data warehouse and business intelligence vendors. Data Lakes allow you to run Analytics without the need to move your data from one system to another.
3. Machine Learning
Data Lakes will allow organizations to generate different types of marketing and operational insights. It includes reporting on historical data and doing machine learning where models produce forecasts and predictions.
4. Improved Customer Interaction
A Data Lake can combine customer data from a CRM platform with social media data analytics, as well as a marketing platform that includes buying history to empower the business to understand the most profitable audiences, the root of customer churn, and what promotions or rewards could increase loyalty.
The Challenge with Data Lakes
A challenge in data lakes is the inability for analysts to determine data quality because a thorough check-up has not taken place. Also, there is no way to use insights from others who have worked with the data, as there is no account of the lineage of findings by previous analysts. Finally, one of the biggest risks of data lakes is security and access control. Data can be placed into a lake without any oversight, and some of the data may contain privacy and regulatory requirements that other data doesn’t.
Ways to Improve Quality in Data Lakes
1. Use of Machine Learning and NLP
Machine learning can be a game changer because it can capture tacit knowledge from the people that know the data best, then turn this knowledge into algorithms, which can be used to automate data processing at scale. This is exactly how Talend is leveraging Spark machine learning to learn from data stewards during data matching and deduplication of data samples, and then apply it at big data scale for billions of records.
2. Setting the standards for agile data quality
for companies to get the most out of their digital transformation projects and build an agile data lake, they need to design data quality processes from the start. Organisations should focus on standardising the following for maintaining the quality of big data
- Roles — Identify roles including data stewards and users of data
- Discovery — Understand where data is coming from, where it is going and what shape it is in. Focus on cleaning your most valuable and most used data first
- Standardization — Validate, cleanse, and transform data. Add metadata early so data can be found by humans and machines. Identify and protect personal and private organizational data with data masking.
- Reconciliation — Verify that data was migrated correctly
- Self-service — Make data quality agile, by letting people who know the data best, clean their data
- Automate — Identify where machine learning in the data quality process can help, such as data deduplication
- Monitor and Manage — Get continuous feedback from users, come up with data quality measurement metrics to improve
3. Employing data quality management frameworks
Another category of frameworks focuses on the maturity of data quality management processes. They aim at assessing the maturity level of DQ management to understand best practices in mature organizations and identify areas for improvement. Popular examples of such frameworks include Total Data Quality Management (TDQM), Capability Maturity Model Integration (CMMI), Control Objectives for Information and Related Technology (CobiT), Information Technology Infrastructure Library (ITIL), and Six Sigma.
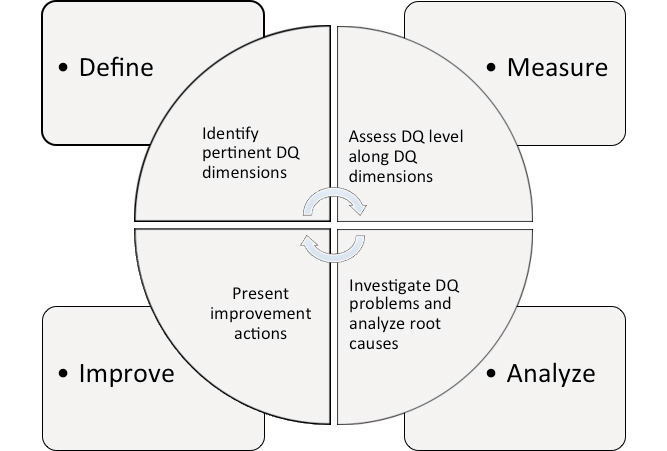
As an example, we can take the TDQM framework. A TDQM cycle consists of four steps, Define, Measure, Analyze, and Improve. The define step identifies the pertinent data quality dimensions. One can quantify them using metrics in the Measure step. Some example metrics are the percentage of customer records with the incorrect address (accuracy), the percentage of customer records with missing birth date (completeness), or an indicator specifying the last update of the customer. The Analyze step tries to identify the root cause of data quality problems. We remedy the previous issues in the improve step. Example actions could be automatic and periodic verification of customer addresses, the addition of a constraint that makes the birth date a mandatory data field, and the generation of alerts when there is no update to customer data in 6 months.
Summary
More and more companies are experimenting with data lakes, hoping to capture inherent advantages in information streams that are readily accessible regardless of platform and business case and that cost less to store than do data in traditional warehouses. As with any deployment of new technology, however, companies will need to reimagine systems, processes, and governance models. Furthermore, if actual data quality improvement is not an option in the short term for reasons of technical constraints or strategic priorities, it is sometimes a partial solution to annotate the data with explicit information about its quality. Such data quality metadata can be stored in the catalogue, possibly with other metadata.
Follow this link, if you are looking to learn more about data science online. Furthermore, if you want to read more about data science, you can read our blogs here
{kind=link}