
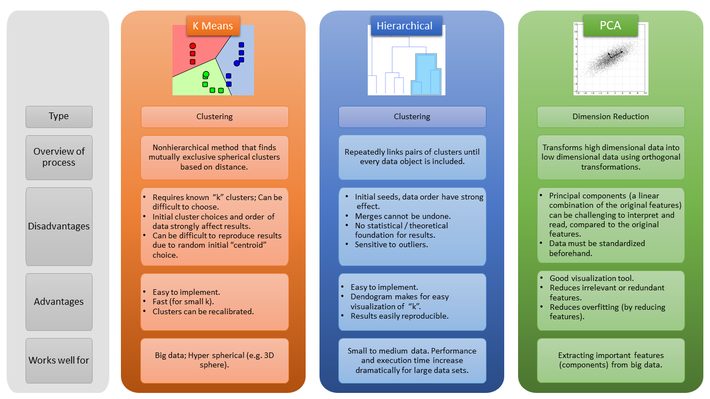
Unsupervised learning algorithms are “unsupervised” because you let them run without direct supervision. You feed the data into the algorithm, and the algorithm figures out the patterns. The following picture shows the differences between three of the most popular unsupervised learning algorithms: Principal Component Analysis, k-Means clustering and Hierarchical clustering. The three are closely related, because data clustering is a type of data reduction; PCA can be viewed as a continuous counterpart of K-Means (see Ding & He, 2004).
References
K-means Clustering via Principal Component Analysis
An Introduction to Clustering and different methods of clustering
Difference Between K Means Clustering And Hierarchical Clustering
Comparison Between K-Mean and Hierarchical Algorithm Using Query Re…
K-means and Hierarchical Clustering
Advantages & Disadvantages of k-Means and Hierarchical clusteri…
Gaussian Scatter Image: Nicoguaro [CC BY 4.0 (https://creativecommons.org/licenses/by/4.0)]
Hierarchical Clustering Image: Blaž Zupan (Orange Data Mining) [CC BY-SA 4.0 (https://creativecommons.org/licenses/by-sa/4.0)]
K Means image: I, Weston.pace [CC BY-SA 3.0 (http://creativecommons.org/licenses/by-sa/3.0/)]
{kind=link}