

Photo by Markus Winkler on Unsplash
Before worrying about where user data will be stored and handled, you should probably worry about how you will handle your static data. Static data refers to data that doesn’t change frequently. This is often the data that defines the configuration and structure of the system. It might not seem that important, and you probably think that this is just overhead. However, if you don’t set up an automatic and efficient way to handle this data, you will have a difficult time when the system starts getting bigger, and you need to migrate to another system.
An example of static data is country names. Your application might need to reference these country names in several different places, but it will never need to alter them (thus, the term static data). A common technique to grab this kind of data in a quick fashion is to store it in a dictionary-style data structure. For example, you can have a table called countries and assign an ID to each country and reference the ID each time you need this country, and store this table in a search index. There are many other examples of static data, but essentially your database will always have some sort of static data. Usually, most of the attention is paid to the dynamic data, which results in poor static data management.
Ensuring access to this static data is quite important, simply because it’s usually referenced over the application multiple times. For instance, you might have an application that involves calculating VAT or Tax before checkout. This operation will involve looking up the tax bracket the user belongs to, which is static data. Also, if you want to display the prices of products before and after tax, you will need to check the tax code for each product to do the calculation. If you have a lot of products, you will need to repeat the process multiple times.
There is also a lot of static data involved in database setup and configuration. Database definition is one example. A good practice that software developers typically don’t follow is extracting configurations into written scripts/code (such as YAML) and adding them to their source code version control. This way, it’s not just sitting somewhere where nobody ever looks, and you can see all of the changes happening to the file. Of course, the more recent systems do this, but some of them still don’t.
Object Storage and Static Data
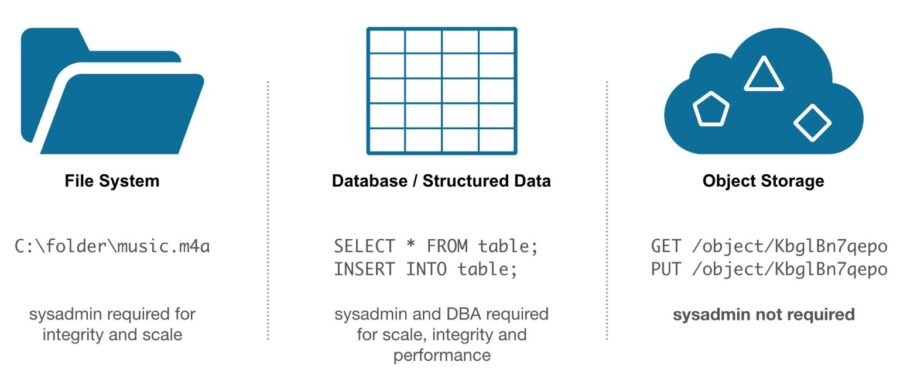
Source: IBM Cloud
Object storage is a storage system that works differently than classic files or block storage. Every stored object exists on the same level instead of having a hierarchy or a tree structure, making object storage ideal for static data management.
To evaluate object storage properly as a static data management solution, we have to look at 3 things:
- Efficiency: Object storage uses the concept of metadata, which introduces tons of customizability and the ability to analyze data and investigate trends. This metadata also allows for faster data retrieval if set up properly.
- Scalability: Most popular object storage providers like AWS give you “infinite” storage access. This means that once your initial storage gets filled, you immediately get more storage access so you can go on upscaling up to petabytes of data, if not more.
- Reliability: Object storage systems are typically distributed over multiple nodes. This means different nodes have the same copies of the data and are in sync. So even if one of them fails, you will immediately be able to access this data from another node.
In terms of accessing the data in object storage, this is done using a RESTful API: you will have to send HTTP requests to either get the data or update it. This is very common in web-based systems, and virtually every system can handle HTTP requests.
Typical object storage providers like AWS, Azure, and IBM have been stepping up their game in terms of the features and services they provide. You can typically expect to see these services:
- Identity & Access Management Policies (IAM): “IAM enables organizations with multiple employees to create and manage multiple users under a single account. With IAM policies, companies can grant IAM users control to their Object Storage buckets.” IBM Cloud
- Access Controls Lists: These allow different users to do different operations. For instance, you might not want all employees on the list to be able to alter the data but rather just view it.
- Encryption: Data is encrypted with Advanced Encryption Standard (AES) and is always sent only over secure sockets (Transport Layer Security)
Conclusion
In conclusion, efficient static data management can give your system a significant boost. One of the ways to do this is through object storage. Implementing object storage shouldn’t be too difficult, especially with the availability of resources and support from big tech providers.
{kind=link}