

Even for many data scientists, Probabilistic Programming is a relatively unfamiliar territory. Yet, it is an area fast gaining in importance.
In this post, I explain briefly the exact problem being addressed by Probabilistic Programming
We can think of Probabilistic Programming as a tool for statistical modelling.
Probabilistic Programming has randomization at its core and the goal of Probabilistic Programming is to provide a statistical analysis that explains a phenomenon.
Probabilistic Programming is based on the idea of latent random variables which allow us to model uncertainty in a phenomenon. In turn, statistical inference in this case involves determining the values of these latent variables
A probabilistic programming language is based on a few primitives: we have a set of primitives for drawing random numbers, primitives for computing probabilities and expectations by conditioning and finally primitives for probabilistic inference
A PPL works a bit differently from traditional machine learning languages. The prior distributions are encoded as assumptions in the model. In the inference stage, the posterior distributions of the parameters of the model are computed based on observed data i.e., inference adjusts the prior probabilities based on observed data.
All this sounds a bit abstract. But how do you use it?
One way could be by Bayesian Probabilistic Graphical models implemented through packages like pymc3
Another way is to combine deep learning with PPLs by Deep PPLs implemented through packages like Tensorflow Probability
For more about Probabilistic deep learning, see
Probabilistic Deep Learning with Probabilistic Neural Networks and …
Finally, its important to emphasise that probabilistic programming takes a different approach to traditional model building
In traditional CS/ machine learning models, the model is defined by parameters which generate the output. In statistical/ Bayesian programming the parameters are not fixed / predetermined. Instead, we starat with a generative process and the parameters are determined as part of the inference based on the inputs
In subsequent posts, we will expand on these ideas in detail.
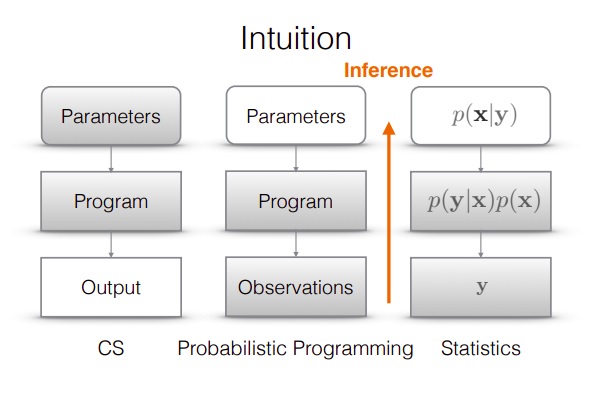
Image source: Tensorflow probability
References
https://www.cs.cornell.edu/courses/cs4110/2016fa/lectures/lecture33…
https://www.math.ucdavis.edu/~gravner/MAT135B/materials/ch11.pdf
https://medium.com/swlh/a-gentle-introduction-to-probabilistic-prog…
{kind=link}