

In this blog I will be covering the basic understanding of a data science problem. To begin with I think before starting with any data science problem you should know about 2 key things:
- What dataset are you going to use?
- What are the key broad level type of machine learning algorithms?
Let’s look at the each of the question.
1. What dataset are you going to use?
The dataset is the backbone of the problem at hand. Choosing the right kind of dataset with right amount of data is very crucial in solving any data science problem. Some of the basic requirements that the dataset should satisfy are:
a. Relevant Data:
Remember you cannot use any dataset to solve a particular problem. So what does a ‘relevant’ dataset looks like?
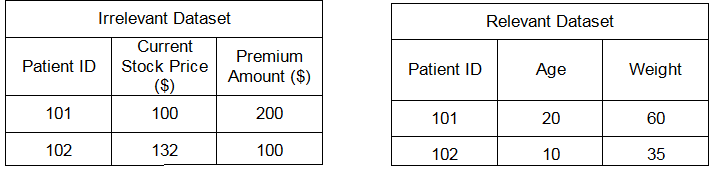
In the examples above, in the left table the dataset columns are totally not related to each other. The patient identifier has nothing to do with the current stock price and the premium amount of different insurance plans.
Whereas, in the table on right each row can be associated with a particular patient. The different columns are actually qualifying the patient and are termed as ‘Features’ of the dataset.
b. Size of data:
Estimating the amount of data needed is also crucial while solving a data science problem. The rule of thumb is that if you have say 20 categorical variables with 15 levels each and 18 continuous variables (for continuous variables assume 10 classes) then the minimum number of rows needed is:
(20 * 15 + 18 * 10) = 480 rows.
2. What are the key broad level types of machine learning algorithms?
So once you have the right structure and the amount of data, let’s look at the different types of machine learning algorithms available to solve problems.
First understand why do you even need an algorithm. Algorithms will spin out an answer to the question asked given an appropriate dataset. For simplicity I am denoting each of the algorithm type with a question that the algorithm helps us answer. I believe that any machine learning algorithm will help us answer the following 5 questions:
a. How much / how many?
b. Which category?
c. Which group?
d. Is the behavior not normal?
e. What action?
Let’s deep dive into each one of them and explore what’s in them.
a. How much / how many?
Linear Regression, Polynomial Regression etc. are the algorithms that essentially help us answer some of the questions like:
– What will be sales of the sales representatives in the next 12 months?
– What will be sales of the newly launched drug?
– What will be insurance premium amount of each account holder?
b. Which category?
Classification algorithms enable us to answer questions in which we have to predict a category. Classification algorithms are those which throw a category when you know that you have to bucket each entity under a fixed number of classes or categories. These are also called as ‘Supervised Classifiers’.
– Identify the category of each physician whether he is an Early Adopter / Mid Adopter / Late Adopter? (Multi-Class Classifier)
– In the multi-indication market, map each patient to a particular indication.
– Is the patient suffering from cancer? – Yes / No (Binary Classifier)
c. Which group?
So what if you don’t know the number of categories that the data needs to be divided into. Don’t worry; there are algorithms to serve you for this purpose as well. Such algorithms are called ‘Unsupervised Algorithms’: Clustering, Recommendation Engine.
– Identify the cluster of physicians having a similar prescribing pattern.
– Which online shoppers have a similar kind of purchasing pattern?
– Which movies should be recommended for each user on BookMyShow?
d. Is the behavior not normal?
 This kind of a question might seem vague in the beginning but it has a lot of practical examples. They are referred to as ‘Anomaly Detection’.
This kind of a question might seem vague in the beginning but it has a lot of practical examples. They are referred to as ‘Anomaly Detection’.
– Fraud detection depending on length of time spent on-line / location of login / spending pattern and frequency.
– In a cluster of computers, identify parameters to determine if a computer is going to fail or not.
e. What action?
Now in the last category, there are some systems in which the decisions need to be made in real time and there is no pile of data to work on but there is a flow of data to work with. Moreover, change in the environment changes the whole set of rules that were applied in the earlier scenario. Learning agent learns by interacting with its environment and observing the results of these interactions. This mimics the fundamental way in which humans (and animals alike) learn.
One of such algorithm is called Reinforcement Learning. The idea is commonly called ‘Cause’ and ‘Effect’.
– Game playing: To determine the best move to make in a game.
– Control problems: In a self-driving car, the system has to continuously monitor the real time environment and make decisions for e.g. to brake or accelerate.
All the 5 broad categories of machine learning algorithms almost cover the entire machine learning space and have been discussed in a very brief and layman language (impossible to cover the detailed explanation in a single blog). I will cover the details in the coming up blogs.
I will conclude with a quote:
“Machine learning isn’t actually complicated, but it is a foreign language!”
Please comment below if you have any questions or suggestions.
(This blog is inspired from a webinar which I attended and from my personal experience.)
{kind=link}