

Used in unsupervised machine learning tasks, Topic Modeling is treated as a form of tagging and primarily used for information retrieval wherein it helps in query expansion. It is vastly used in mapping user preference in topics across search engineers. The main applications of Topic Modeling are classification, categorization, summarization of documents. AI methodologies associated with genetics, social media, and computer vision tasks are associated with Topic Modeling. It also powers analysis on social networks pertaining to the sentiments of users.
Topic Modeling Difference and Related Algorithms
Topic Modeling is performed on unsupervised information and has a clear distinction from text classification and clustering tasks. Unlike text classification or clustering, which aims to make information retrieval easy, and make clusters of documents, Topic Modeling is not aiming to find similarities in documents. In Topic Modeling, usually, there is a plurality of topics, and text is distributed.
Topic Modeling makes clusters of three types of words – co-occurring words; distribution of words, and histogram of words topic-wise. There are several Topic Modeling models such as bag-of-words, unigram model, generative model.
Algorithms and Techniques used in Improving Topic Modeling
Some algorithms used for Topic Modeling tasks are Latent Dirichlet Allocation, Latent Semantic Analysis, Correlated Topic Modeling, and Probabilistic Latent Semantic Analysis.
Here are some specifications on the algorithms.
- Latent Dirichlet Allocation: Based on the Bayesian approach of describing all forms of statistical uncertainties in probabilities, LDA or Latent Dirichlet Allocation depicts an infinite mixture of topics probabilities that are represented in a document.
- Latent Semantic Analysis: Using Singular Value Decomposition as a technique, this algorithm helps in keeping documents and words in a semantic space for classification.
- Probabilistic Latent Semantic Analysis: Can be trained with an expectation-maximization algorithm, PLSA or Probabilistic Latent Semantic Analysis makes use of probability of a word in topic and topic in a document. This methodology is based on the multinomial distribution of words.
The best and frequently used algorithm to define and work out with Topic Modeling is LDA or Latent Dirichlet Allocation that digs out topic probabilities from statistical data available. While using the Topic Modeling methodology, there are some challenges. One of the first challenges faced is that Topic Modeling doesnt provide a fixed number of topics, hence, approaches such as the LDA or LSA require conditioning to handle issues like overfitting, non-linearity, and discovery of too many generic words which are not useful.
To fix these sorts of issues in topic modeling, below mentioned techniques are applied.
1. Text pre-processing, removing lemmatization, stop words, and punctuations.
2. Removing contextually less relevant words.
3. Perform batch-wise LDA which will provide topics in batches.
4. Improving LDA by joining the terms using syntax and applying CTM or Correlated Topic Modeling for correlating the topics.
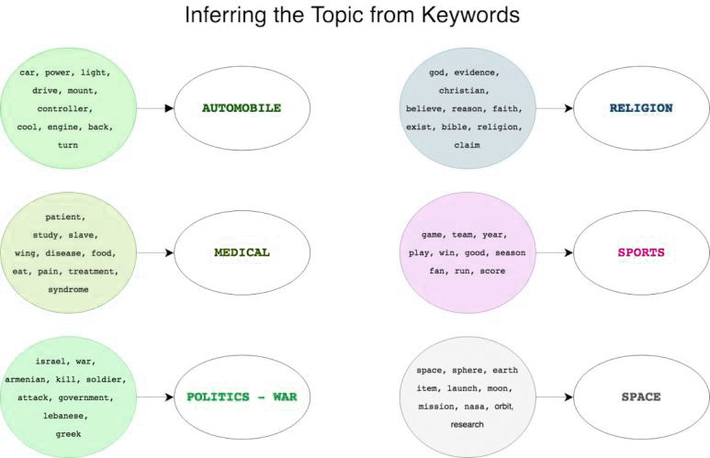
Image credit: devopedia
Topic Modeling methods and techniques are used for extensive text mining tasks. This approach is known for handling long format content and lesser effective for working out with short text. It is essentially used in machine learning for finding thematic relations in a large collection of documents with textual data.
Application of Topic Modeling
The application of Topic Modeling has become diverse with supervised, unsupervised, and semi-supervised approaches being modified and invented to apply in text mining, text classification, machine learning, information retrieval, and recommendation engines.
Occupying a central part in Information Retrieval or IR in Natural language processing or NLP tasks, Topic Modeling is performed chiefly on document repositories with textual information or data. Mathematically, information retrieval in the application includes – representation of documents, queries, the framework, and the ranking system. To quote further, IR is utilized by search engines like Google, Bing to provide appropriate information basis the user query.
Topic Modeling is also utilized to provide clear textual classification in the databases of genomics which normally have vast amounts of textual content. The search engines used for genomics make use of Topic Modeling to collate and present relevant information as per user queries. The application of Topic Modeling sounds simple, however, the methodologies applied to sort and represent information matters the most.
Important Events in the Evolution of Topic Modeling
Like other methodologies or techniques, Topic Modeling has passed many milestones to appear as perfect as it works now. In 1990, Deerwester applied Singular value decomposition for information retrieval and auto-indexing, and quoted that user wants to see information based on a concept rather than words; proposing LSA and LSI for information retrieval using Topic Modeling.
The year 1998 marks the beginning of the usage of probabilistic models for information retrieval; leading to the adoption of PLSA or Probabilistic Latent Semnatic Analysis based aspect model that associated words and topics in a generative model.
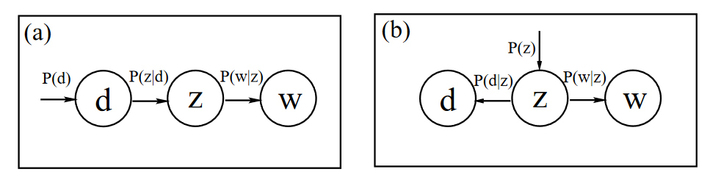
The introduction of LDA in 2003 added to the value of using Topic Modeling in many other complex text mining tasks. In 2007, Topic Modeling is applied for social media networks based on the ART or Author Recipient Topic model summarization of documents. Since then, many changes and new methods have been adopted to perform specific text mining, classification, and clustering tasks for a variety of real-world applications. The evolution of Topic Modeling and its techniques have changed the way the world has looked at information on diverse information-driven platforms. More recently, Topic Modeling was combined with a community detection approach leading to a mesh of both approaches and the birth of Hierarchal SBM for Topic Modeling for identifying communities or groups with similar patterns.
{kind=link}