

Guys! I hope you all are enjoyed reading my earlier article Part – I 10/20, and I trust that would be useful for you. Let’s discuss the rest of the project quickly.
11. Learn to prepare data for your next machine learning project.

Problem Statement & Solution
When youre dealing with NLP based problem statement, we must focus on Text Data preparation before you can start using it for any NLP algorithm. The foremost step is that text cleaning and processing is an important task in every machine learning project, even if we are working on the text-based task and making sense of textual data. So, when dealing with text, we must take extra causes for Text Classification, Text Summarization, understanding Tokenization, and Bag of Words preparation.
The big challenge here is constructing features from Text Data and creating synthetic features, which are really critical tasks. On top of it how to apply machine learning models to develop classifiers is also tricky.
Indeed, this project would help to understand the text classification and susceptible analysis area in various domains.
Key take away and Outcome and of this project.
- Understanding on
- NLTK library for NLP
- Stop words and use in the context of NLP
- The difference between NLP, NLG, and NLU.
- TFIDF vector and its significance
- Text Specific Analytics
- Sentiment Analysis
- Text Classification
- Topic Modelling
- Text Summarization
- Tokenization and Bag of Words
- Part of Speech (POS) tagging
- Difference between Lemmatization and Stemming
- What is Binary Text classification and Text classification?
- How to apply
- NLP pre-processing for training model
- Linear SVC for binary classification
- One Vs. Rest Classifier for Multi-Label Classification
- Multi-Label Binarizer for Multi-Label Classification
- Understanding the evaluation metrics
- Precision
- F1-score
- Recall
12. Time Series Forecasting with LSTM Neural Network Python
Problem Statement & Solution
Always Time series prediction problems are a challenging form of predictive modelling problems. The Long Short-Term Memory (LSTM) network is a type of recurrent neural network used in deep learning since very large architectures can be successfully trained. It is used to add the complexity of sequences and dependence among the input variables.
LSTM is a type of recurrent neural network that can learn the dependence between items in sequence order. This type itself promises to be able to understand the context required to make predictions in terms of TIME-SERIES FORECASTING problems.
As we know, deep learning is one leading technology where we can implement many things as we do in our day-to-day business operations, including segmentation, clustering, forecasting, prediction, or recommendation, etc. Deep learning architecture has many branches. One of them is the recurrent neural network (RNN). The method that we are going to analyze in this deep-learning project is about Long Short-Term Memory Network (LSTM) to perform time series forecasting for univariate time series data.
Key take away and Outcome and of this project.
- Understanding necessary libraries for applying Neural Networks
- How to
- Install Keras and LSTM
- Perform EDA
- Plotting a Time Series plot
- Creating a Dataset matrix for applying LSTM
- Understanding sequentially initializing a Neural Networks
- Defining the error function
- How to apply LSTM as a training model
- Implementation of visualizing the loss and accuracy with each epoch
- How to tune the final model and using it to make predictions.
13. Bosch Production Line Performance Data Science Project

Problem Statement & Solution
In this data science project, we could predict internal failures of the assembly line in Bosch. The business problem has been addressed during the chocolate souffle manufacturing process, and the process itself bit challenging since the good chocolate souffle is decadent, delicious, and delicate. So, we have to follow up the steps; if something goes wrong, we must retrace the steps we did wrong. But here, we have the major advantage with Boschs mechanical components of the highest quality and safety standards.
And on top of this, they have features that record the data at every step along its assembly lines and can apply advanced analytics to improve the manufacturing processes and its quality. Even though the nature of the data might vary, and its complexity could increase, we certainly need a data science-specific solution to resolve the problems concerning the production line dataset and predict internal failures using data available in each component along the assembly line. This would facilitate Bosch to bring quality products at reducing costs to the end-user benefits.
Key take away and Outcome and of this project.
- Understanding real-time business context along with the Exploratory Data Analysis process
- Handling null values, imbalanced, noisy, and best evaluation metrics dataset.
- Applying
- Probabilistic model BernoulliNB for training
- Ensemble model
- Random Forest Classifier for training
- Extra Tree Classifier for training
- XGBoost Classifier for training
- Defining parameters for applying
- GRID SEARCH CV
- Using
- Cross Folds Validation to prevent overfitting
- Correlation and Violin plot for selecting the best features for the model
14. Classifying Handwritten Digits using MNIST Dataset

Problem Statement & Solution
Hand-written digit recognition is a challenging task for the machine because the hand-written digits are not always perfect and can be made with many different aspects. The objective of this project is to take the hand-written single-digit image and determine what that digit is. Please refer to the above picture(s).
Here were using the popular MNIST database of hand-written digits; the dataset consists of 60,000 images of 28×28 handwritten pixel digits and pre-processed and formatted. The model can be built to accurately read the handwritten digits with 95% accuracy using image recognition techniques and a suitable machine learning algorithm. The rate of accuracy depends on the selected machine learning algorithm.
Key take away and Outcome and of this project.
- How to programmatically use with Python libraries
- Unzipping folders and loading the dataset
- Visualizing different images available in the dataset
- Plotting Confusion matrix and interpreting the results
- Predicting the result and saving it in the form of CSV
- Understanding
- Left-skew and Right-skew of the dataset
- Pre-processing the training dataset
- Ensemble model
- Random Forest
- MeanDecresedGini
- Hyper-parameter tuning Random Forest
- Training Neural Networks for predictions
- Plotting graphs against parameters and OOB errors
- How to be Importing
- FNN library and using K-nearest neighbours
- XGBoost and converting Dataset into DMatrix for performing predictions
- Defining parameters and performing Cross Folds validation using XGBoost model
15. Predict Employee Computer Access Needs in Python

Predicting employee access needs to be based on their job role and responsibilities (R&R) from the employee database. What is the deal? I can understand your question. Yes. Of Course, this is a huge deal like Amazon, Facebook, IBM and Microsoft, Google, Microsoft, etc.,
In this current digital world, when an employee starts his/her work, they should get a laptop and access to proprietary software necessary to fulfill their R&R. It is assumed that employees are fulfilling their functions of a given role on a day-to-day basis.
In some situations, in most of the organization, it is often that the employees chase and figure out the list access they need to accomplish their duties with the help of their counterparts, otherwise as they encounter roadblocks during their daily work at least the initial period.
This is quite interesting that automating the process based on the R&R. Since there is a considerable amount of data regarding an employees R&R generated within an organization, certainly, we could use this information as a base; obviously, we must revisit regularly to fine to the mapping, this mapping would be the resource. We could build the model that automatically determines access privileges and pass on the information to the relevant department and auto-installation process. This is very well applicable even employees enter and leave roles within a company.
Ultimately, this project could build an auto-access machine learning model that eliminates the considerable manual intervention and keeps the highly critical part only routed to manual approvals. At the same time, the model will revoke employee access based on other situations.
Key take away and Outcome and of this project.
- Understanding
- EDA and Visualization techniques
- Univariate Analysis and Data Transformation conversion
- Encoding and Decoding functionalities
- K-fold cross-validation
- Performing approximate greedy feature selection
- Applying
- Logistic Regression
- Hyper-parameter tuning
- Evaluation using AUC score
16. Forecasting Business KPI’s with TensorFlow and Python
As we all know that the important marketing strategies are in trending branding, which helps businesses to grow. Branding helps the standard of the brands and stand out in a crowded business market, So the intention is to reach the brand to targeted customers in the market.
The companies invest an amount in promoting their brand(s), and the return on investment will be nothing but the number of sales of their product(s). This is nothing but Return on investment (ROI).
In this ML project, you will use the video clip of an IPL match played between two teams CSK Vs. RCB, the objective of this project is to forecast a few major KPIs which is related to the number of times that the brand logo is in the frames, longest and shortest area percentage in the given video clip.

Key take away and Outcome and of this project.
- Understanding the business problem.
- Learning
- How to convert the XML files to CSV files.
- How to convert the CSV files to tfrecords files.
- How to use the annotation tool (LabelImg) for generating XML files.
- What and how to clone model.
- Visualization via the tensor boards.
- Generating frozen model from ckpts
- Calculating the various KPI metrics such as
- The number of appearances of logo
- The area, frame
- The shortest and largest area percentage.
- Understanding
- The concept of CKPT file in TensorFlow
- Making predictions using the trained model.
- How to process the videos and break them down into frames.
- How to process the frames to gain predictions.
17. Time Series Python Project using Greykite and Neural Prophet

In this Machine Learning Project, were going to discuss the TIME SERIES; Walmarts sample data has been used to forecast sales over time using the time series forecasting library called Greykite, which helps us automate time series-based problems.
As we know that the time series is nothing but a sequence of data points that have been collected at a constant time interval, with These historical data points would help us to do the forecasting of the business by applying the statistical model by deriving the patterns out of it.
In the supply chain domain, this time series playing a vital role in various aspects, in which DEMAND and SALES are critical factors in business; the objective of this project is to address the second one.
Key take away and Outcome and of this project.
- Understanding
- Business context and objective and Inference of data
- Data Cleaning and Feature Engineering
- Time-series components,
- Trend and Seasonality Analysis
- Understanding Greykite library and building Greykite model
- Understanding Neural Prophet library and building Neural Prophet model
- Understanding
- AR net model
- Model Predictions
- Model Evaluation
- Flask Deployment
18. Deploying auto-reply Twitter handle with Kafka, Spark, and LSTM
As we know, natural language processing (NLP) focuses on interpreting text and speech in the same manner as humans do. It helps the computer to understand by breaking down the human text in ways that make sense to absorbs and store the information. NLPs role in social media is beyond our thought process, which helps to finds hidden data insights, especially in the space of Sentiment Analysis, in which by analyzing the languages used in social media reviews, comments again the post and extracts attitudes and emotions on the post(s) Eventually, this helps to promote the events and products.
The companies have used this analysis for various purposes – campaigns of the product, customer mindset on the product. The whole architecture can be clubbed with NER (Named Entity Recognition), a technique for recognizing words or sentences as valuable entities.
The objective of this auto-reply Twitter project is to listen to live tweets and respond back using the NLP pipeline. The tweets will be classified based on the sentiment and categorised using Machine Learning models as LSTM using Flask and tweepy API and Big Data techniques which is deployed on AWS cloud services.
Key take away and Outcome and of this project.
- Understanding
- Exploring Tweepy API and dataset.
- Text classification and its applications.
- NER (Named Entity Recognition) technique.
- LDA and data labelling.
- Spark and Kafka basics
- Implementing
- Data cleaning and preparation procedure for NLP tasks using regex.
- Flask API and Kafka.
- Google Colab for training purposes.
19. Resume parsing with Machine learning – NLP with Python OCR and Spacy

The project is quite interesting and very innovative thought. In this project, the resume would be parsed and extract the Location/Designation/Name/Years of Experience/College/Degree/Graduation Year/Companies worked at/Email address put it back into the dataset, by making HRs resume selection process simple and quicker way. This resume parser uses the popular Spacy library – for OCR (Optical character recognition) and Text classifications. Ultimately it saves time, money, and productivity for the company by reducing the tough time of scanning thousands of qualified resumes manually.
Key take away and Outcome and of this project.
- Understanding
- Machine learning framework
- Natural Language Processing
- OCR (Optical character recognition)
- Named Entity Recognition
- Annotations & Entities in Spacy
- Spacy Custom Model Building
- Incremental Spacy Model Building
- TIKA OCR process
- How to Extract the text from PDF
20. Create Your First Chatbot with RASA NLU Model and Python
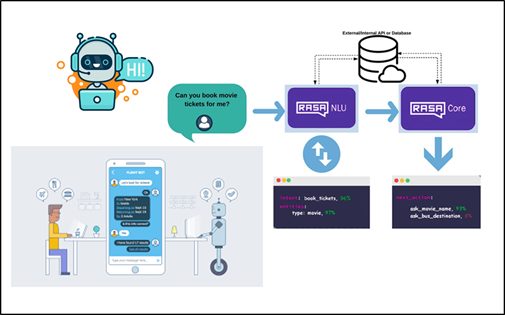
A chatbot simulates and processing human conversation, it could be either way [written or spoken]. This is computer programming allowing humans to interact with digital devices as a real person interaction. We could build two types of chatbots – Rule-based chatbots and AI-based chatbots.
RULE-BASED CHATBOTS: Pre-defined rules, User input must align with these pre-set rules to get an approximate answer.
AI-BASED CHATBOTS: Artificial intelligence (AI) based chatbots make use of Machine Learning algorithms to understand the situation and meaning of a question before preparing a response back to an interacting person. Answers are prepared by using Natural-Language responses. Based on the usage these bots use to train themselves and support questions

Guys, Hope you had a very good experience by reading all these projects and benefits, Will get back to you with a different topic shortly, see you soon, Cheers! Shanthababu.
){kind=link}