
Summary: This may be the golden age of deep learning but a lot can be learned by looking at where deep neural nets aren’t working yet. This can be a guide to calming the hype. It can also be a roadmap to future opportunities once these barriers are behind us.
 We are living in the golden age of deep learning. This is quite literally the technology that launched 10,000 startups (to paraphrase Kevin Kelly’s prophetic prediction from 2014 “The business plans of the next 10,000 startups are easy to forecast: Take X and add AI.”) Well that happened.
We are living in the golden age of deep learning. This is quite literally the technology that launched 10,000 startups (to paraphrase Kevin Kelly’s prophetic prediction from 2014 “The business plans of the next 10,000 startups are easy to forecast: Take X and add AI.”) Well that happened.
Kelly was speaking more broadly about AI, but over the last four years we’ve come to understand that it’s about CNNs and RNN/LSTMs that are actually commercially ready and driving this.
Although the last two years have been fairly quiet in terms of new technique and technology breakthroughs for data science, it hasn’t been totally quiet. Like the emergence of Temporal Convolutional Nets (TCNs) to replace RNNs in language translation, research goes on to see how deep learning and specifically CNN architecture can be pushed into new applications.
Roadblocks to Deep Learning
Which brings us to our current topic which is to understand what some of the major roadblocks in research are in trying to expand deep learning into new areas.
In calling our attention to ‘things that aren’t working in deep learning’, we aren’t suggesting that these things will never work, but rather that researchers are currently identifying major stumbling blocks to moving forward.
The value of this is two-fold. First it can help steer us away from projects that might on the surface look like deep learning will work, but in fact may take a year or years to work out. Second, we should keep our eye on these particular issues since once they are resolved they will represent opportunities that others may have decided weren’t possible.
Here are several that we spotted in the research.
Are Those the Same or Different?
Our CNNs do a remarkably good job at classifying objects. For example the image on the left is reliably identified as a flute.
CNNs also do a good job at spatial relationship (SR) images like the one in the middle. In SR the objective is to detect a geometric relationship among the objects like do they fall along a line or are they stacked vertically or horizontally.
But the third image on the right which any child could identify as being the same two objects is handled very poorly by CNNs. 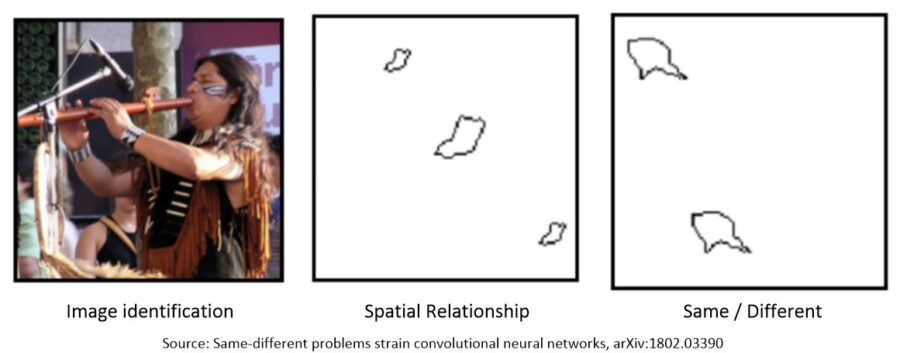
How poorly? Researchers Ricci, Kim, and Serre at Brown University found that over their test program using the best performing CNN for each of 23 test problems, that the spatial relationship samples did quite well while the same-different test sample did very poorly.
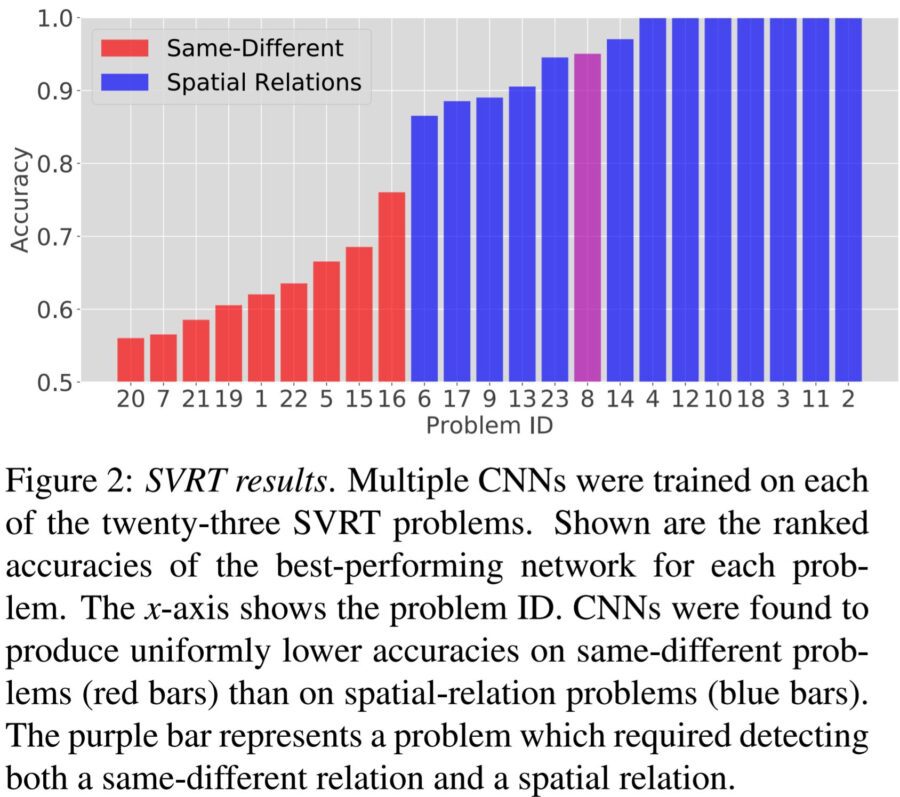 Being able to detect same-different objects would be quite useful but the accuracy on even the best performing samples is still very far below being commercially acceptable.
Being able to detect same-different objects would be quite useful but the accuracy on even the best performing samples is still very far below being commercially acceptable.
What’s more, they found that with SD problems, better accuracy was achieved on simpler images. Their hypothesis is that regardless of how many nodes or layers are added, more complex SD problems simply overwhelm the discriminatory ability of the CNN which may also suggest that on the simpler problems, the CNN was merely memorizing from the training data.
For more on this see the original paper here, or this more accessible summary here.
Problem status: Not resolved. Research continues.
Computer Vision Doesn’t Work Very Well
 If all you want is to identify photos on Facebook or to keep your robot butler from spilling your drink you’d probably be satisfied with current state of computer vision. But if you are going to entrust yourself or strangers to that self-driving car, you’ll need to wait until its vision gets a lot better.
If all you want is to identify photos on Facebook or to keep your robot butler from spilling your drink you’d probably be satisfied with current state of computer vision. But if you are going to entrust yourself or strangers to that self-driving car, you’ll need to wait until its vision gets a lot better.
Zeeshan Zia who holds a PhD in Computer Vision and Machine Learning and is a Senior Scientist at Microsoft would like you to know that things are not as rosy as the popular press may lead you to believe.
The problems in computer vision for robotics breakdown into a couple of major subsets, one being ‘object detection’ and the other being ‘classification and localization’. The integration of these two is SLAM (simultaneous localization and mapping).
Zeeshan argues that these techniques may work well in static environments but the evidence is that in dynamic environments the accuracy isn’t there. There’s an annual competition for this called the Imagenet Large Scale Visual Recognition Challenge (ILSVRC).
The results cited are from 2017 so hopefully things have gotten a little better, but the results are not reassuring.
For Object Detection, the 47 competitive submissions by roughly 20 different teams, ranged from a low of 0.2067 mean average precision (map) to a high of only 0.7322 mean average precision. For comparison, in 2016 the top score was 0.6628 so the field is progressing.
Object Detection from video, perhaps more akin to real self-driving cars, ranged from a low of 0.1958 map to a high of 0.8183 map (up from 0.8083 in 2016 – much less improvement in this category). You can see the full results here.
Over the last three or four years the introduction of deep learning has in fact improved these results much more rapidly than before. But as Zeeshan observes, making this work means more than just reading a few papers. He says,
“I have seen only three commercial products where SLAM really works; and all three teams had multiple SLAM PhDs and leading professors working on them. These three are Microsoft’s HoloLens, Google’s Project Tango, and Dyson’s 360 Eye robot. Many other commercial teams are having a hard time building working SLAM pipelines.”
Problem Status: Getting there slowly but certainly not there yet for robotic applications.
Deep Reinforcement Learning Doesn’t Work Yet
Reinforcement Learning (RL) is arguably the hottest research area in AI today because it appears RL can be adapted to any problem that has a well-defined reward function. That encompasses game play, robotics, self-driving cars, and frankly pretty much else in machine learning.
 Within RL, the hottest research area is Deep RL which means using a deep neural net as the ‘agent’ in the training. Deep RL is seen as the form of RL with the most potential to generalize over the largest number of cases and perhaps the closest we’ve yet come to AGI (artificial general intelligence).
Within RL, the hottest research area is Deep RL which means using a deep neural net as the ‘agent’ in the training. Deep RL is seen as the form of RL with the most potential to generalize over the largest number of cases and perhaps the closest we’ve yet come to AGI (artificial general intelligence).
Importantly, Deep RL is also the technique used to win at Alpha Go which brought it huge attention.
The problem is, according to Alex Irpan, a researcher on the Google Brain Robotics team that about 70% of the time they just don’t work.
Alex has written a very comprehensive article critiquing the current state of Deep RL, the field with which he engages on a day-to-day basis. He lays out a whole series of problems and we’ve elected to focus on the three that most clearly illustrate the current state of the problem with notes from his work.
- If performance is all you care about there are other RL techniques that can get you there better than Deep RL.
 For example, in the famous MuJoCo robot training scenario, extremely good performance can be achieved with online trajectory optimization. The correct actions are computed in near real-time, online, with no offline training
For example, in the famous MuJoCo robot training scenario, extremely good performance can be achieved with online trajectory optimization. The correct actions are computed in near real-time, online, with no offline training
Atari is another famous demonstration problem where you can outperform Deep RL with off-the-shelf Monte Carlo Tree Search.
And those fantastic robots at Boston Dynamics? Not Deep RL. Based on their published papers you find reference to mostly classical robotic techniques like time-varying LQR, QP solvers, and convex optimization.
Alex says “The rule-of-thumb is that except in rare cases, domain-specific algorithms work faster and better than [deep] reinforcement learning. This isn’t a problem if you’re doing deep RL for deep RL’s sake, but I personally find it frustrating when I compare RL’s performance to, well, anything else.”
- Deep RL is horribly sample inefficient.
It’s not new news that deep neural nets require very large quantities of training data. But since one of RL’s primary advantages is that it’s supposed to create its owning training data, it’s interesting that this is still a barrier.
Alex quotes several examples but the one from Atari sticks with us. Several of the variant techniques in Deep RL have indeed surpassed human level performance in about 40 of the roughly 57 games in the Atari universe. But they took a very long time to train.
Atari runs at 60 frames per second and each frame is a learning instance. In 2017 the record for fastest training was 70 million frames. This year the best technique reduced that to 18 million frames. However this still equates to about 83 hours of game play where humans can pick this up in just a few hours.
Worse, of the roughly seven main versions of Deep RL, several of them failed to equal human performance after even 200 million frames.
- When Deep RL works the results can be unstable and hard to reproduce. Even where it does work it may be just overfitting patterns in the environment.
Taking the last point first, if you want your Deep RL to work in a closed environment like Atari, you really don’t care if it over fits. Just don’t expect it to generalize to other environments.
More broadly though, when deep neural nets are used in supervised learning the hyperparameters are pretty well understood, and even modifying them results in changes that are reasonably predictable.
But RL in general is the very definition of unsupervised learning. In Deep RL the behavior of the hyperparameters is not well understood at all and is mostly nonlinear and therefore pretty unpredictable. Researchers in Deep RL are where researchers in CNNs and RNNs were several years back, still guessing and hand tuning their networks.
Alex says that he started off his training by trying to reproduce models from well-known Deep RL papers and this inevitably took 2X or 3X times as long as it should have. It also means that many times Deep RL models can’t be reproduced, fail to generalize, or simply fail to train.
The reasons for this still aren’t well understood, but likely one issue is the use of random seeds to start the training process so that no two training instances are truly the same.
So we come back to Alex’s original contention. Based on today’s state of the art, Deep RL is going to fail about 70% of the time. On the other hand, there’s the spectacular win of Deep RL in Alpha Go that shows that the future can be bright.
Problem Status: Working on it. Progress is slow but there’s a lot of research interest. Eventually we’ll get it.
Other articles by Bill Vorhies.
About the author: Bill Vorhies is Editorial Director for Data Science Central and has practiced as a data scientist since 2001. He can be reached at:
[email protected] or [email protected]
{kind=link}