

Before telling about my experience in my career path as an aspiring data scientist, I want to give a brief introduction about myself. I have always been motivated by the fields of Computer Science and Mathematics since High School, which still is an integral part of my life. I always believed that practical usage and applications of a subject make one perfect and get a professional hold on it. As to this fact, I became very curious and wanted to explore the field of Data Science and its applications. This tremendous passion made me start learning Data Science on my own while in my undergraduate studies. Additionally, I have taken a decision and started to explore my future in Data Science. And today I want all the people reading this blog to learn from my experience of my starting steps in my career as an aspiring Data Scientist. By learning about:
- The Field of Data Science and why it’s future?
- How Data Science works?
- When can you start your journey as a data scientist?
- How can you start your journey as a Data Scientist?
- My work as a Big data Scientist?
- Tools used in production by a Big data scientist?
The Field of Data Science and Why It’s our future?
Data science as the same suggests will work on data using scientific a.k.a mathematical model to extract the information the data is trying to convey. Data Science is an interdisciplinary field that is the amalgam of Software Programing, Statistics, Discrete Mathematics, Algorithms, Data Communication, basic calculus, and linear algebra.
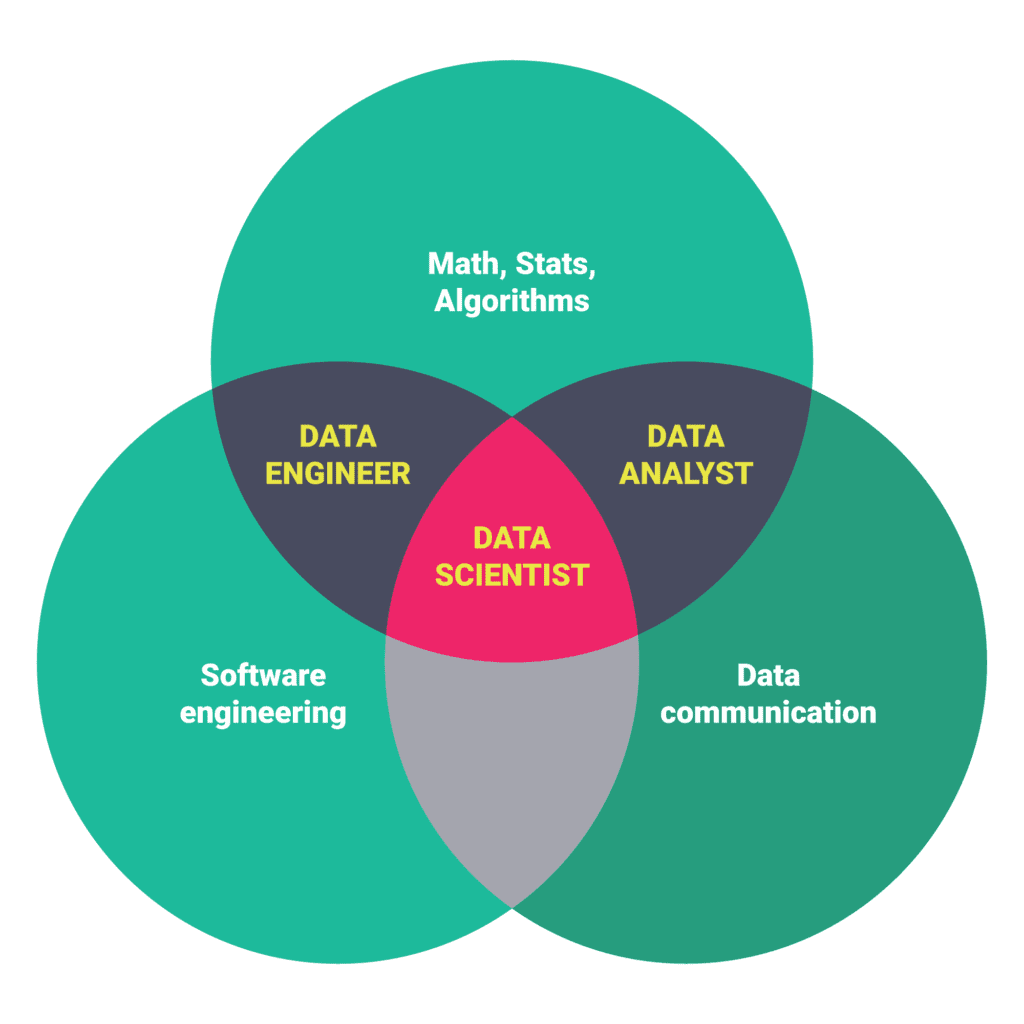
Source: https://prwatech.in/what-is-graph-based-machine-learning-data-scien…
The list may be pretty long but don’t let the pre-requisites scare you or overwhelm you, the good thing about data science is you don’t have to be perfect in a majority of those things. Data science is still fairly a new field in the market but it has grown and is still growing rapidly.
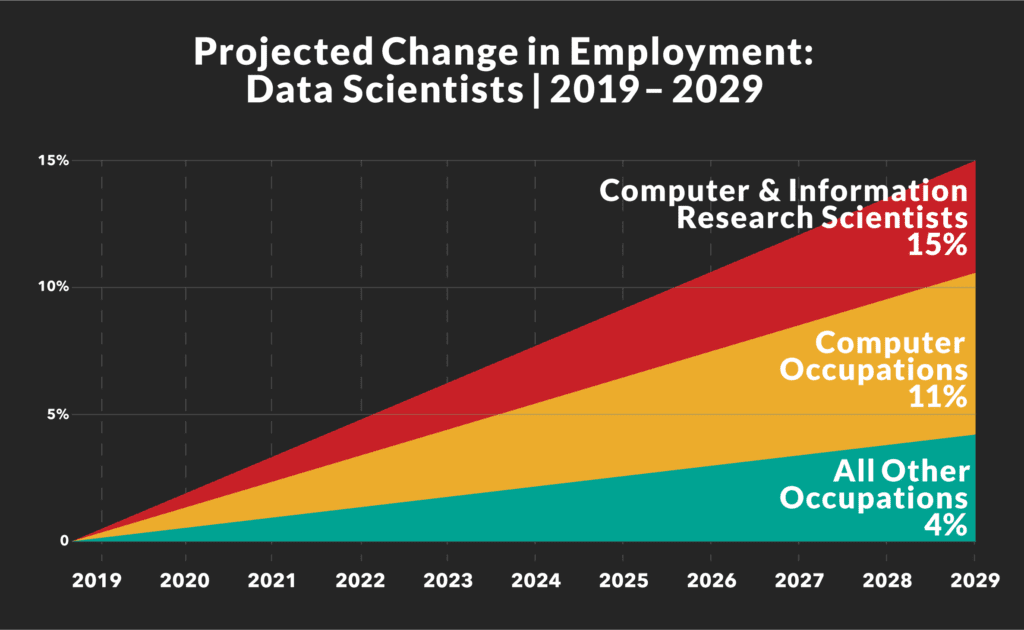
Source: https://www.datasciencedegreeprograms.net/faq/job-outlook-data-scie…
How does Data Science work?
Being such a broad interdisciplinary field the types of activities and tasks a data scientist may perform may differ from company to company. But in conventional setup activities of Data scientists may include
1.)data collection and storage
2.)data cleaning or data pre-processing
3.)data wrangling or data organization
4.)dashboard generation or data visualization
5.) Developing ML models
5.) Trail and error
6.) Evaluation of the model
expanding each of these things may take an entire course and is more than the scope of this blog. But I am going to cover the tools that are used for each of these processes. If you are interested in knowing what actions are performed in each of these activities I recommend you to have a look at this video by Edureka as they have explained the actions of each of these activities by giving real-life examples.
When can you start your journey as a Data Scientist?
There is no particular time to start your journey as a data scientist, If you are reading this blog you are already old enough to learn basic statistics and experiment with those concepts in programming. In the same way, you can never be too old to start learning data science if you’re passionate about it.
How can you start your journey as a Data Scientist?
No matter what your background is, with enough hard work and passion you too can have a great career in data science.
- Learning Path:
If you are an outliner like me you want to know what all skills you need to learn in your learning path visit this link learning path
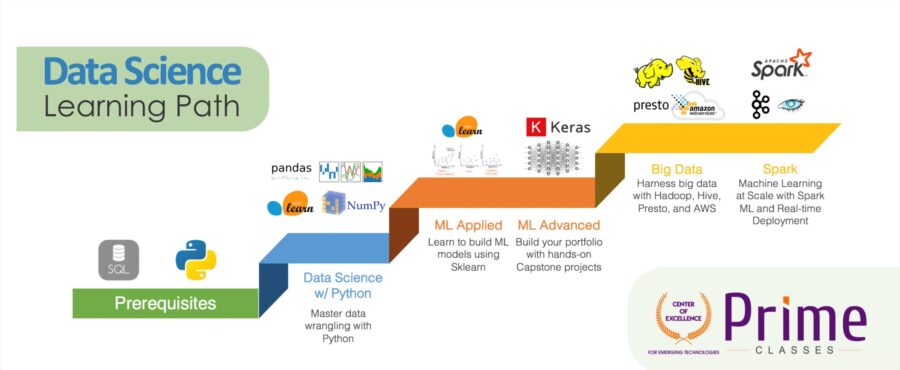
Source: http://www.primeclasses.in/blog/2019/06/29/data-science-learning-an…
- Learning Curve:
For your learning curve, I want to tell you a trend called #66daysofdata where people learn data science and the relevant skills required for data science in 66 days. If you want to familiarize yourself more about the challenge I would recommend you to watch the video of Ken Jee where he will explain this challenge.
What does a big data Analyst do?
ETL(Extract Transform Load) is the common development a big data Engineer does in a company. ETL is a method where the big data engineer first extracts any type of structure, unstructured or semistructured data. This data is extracted from the servers like on-premises servers, cloud servers like SAP, AWA, Azure synapse and then performs transformations on the data based on the requirement of processing, then load the data according to the requirements of developing a Machine Learning model.
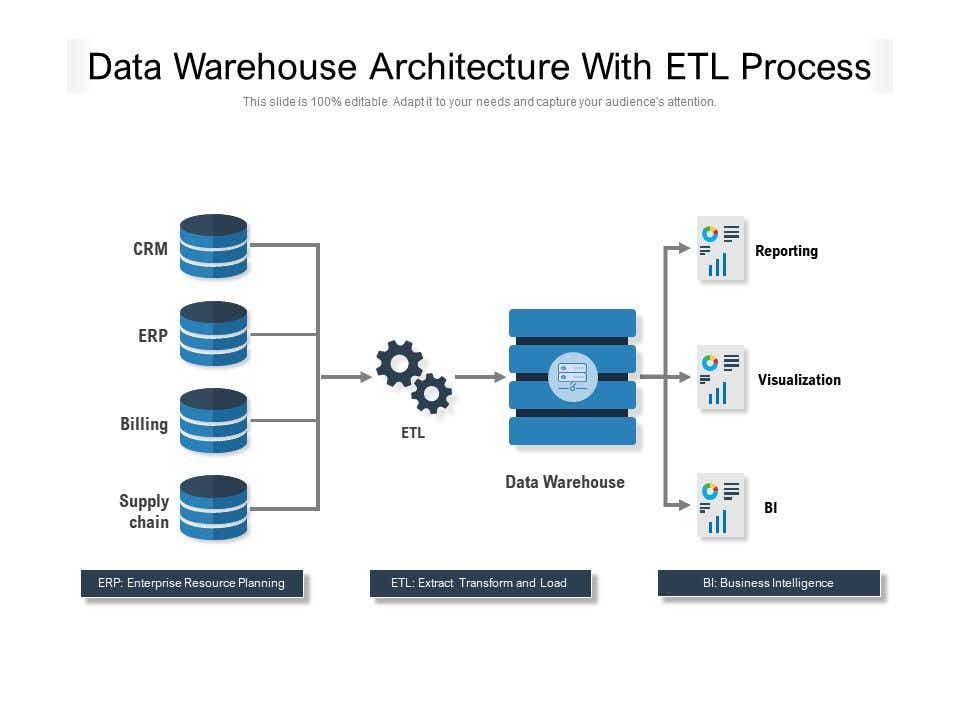
Source: https://www.slideteam.net/data-warehouse-architecture-with-etl-proc…
Tools in Big data Analysis:
Some important tools Big data analysts use in ETL development are:
- Azure Data Factory(any cloud service): ADF has been used the load the data from on-premises or cloud servers to SQL servers for performing transformations on the data.
- SQL server: SQL Server is used to run procedurals on the data to process the data and make it suitable to build ML models or make Dashboards with it.
- Apache Spark: SPARK is used to process big data in a cluster using algorithms in an optimized way
- Power BI: Power BI is a dashboard-building software used to generate business or any kind of reports that can be seen in a dashboard.
{kind=link}