
Predictive analytics uses current and historical data in order to determine the probability of a particular outcome. This is a particularly powerful approach when it is applied to medical diagnosis. In an effort to reduce misdiagnosis, historical data of former patient’s symptoms may be applied to the assessment of a new patient.
While doctors are the ultimate experts and decision-makers, using predictive analytics as a means of establishing precedent for particular patient ailments can be of significant benefit in lieu of a second or even a third or fourth opinion. Predictive analytics can help doctors to make even more informed and insightful diagnoses by using current and/or historical data. After all, the diagnosis phase is certainly the most important when it is put into the context of the patient’s overall journey from definition of initial symptoms to ultimate recovery. This is particularly important when one considers that misdiagnosis accounts for as much as one third of all medical errors, and diagnosis error can be three times more common than prescription error.*
The latest version of FlexRule includes a new sample project called Predictive Analytics. This describes how a patient’s history at a particular medical centre during a specific period of time could help doctors validate the diagnoses for new patients with a similar set of symptoms during the same time frame.
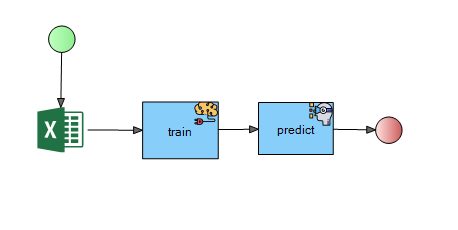
At the highest level, the FlexRule project involves three main actions. These are as follows:
- Read the patient’s historical data
- Use the Naïve Bays (NB) Algorithm to train the model
- Predict the diagnosis
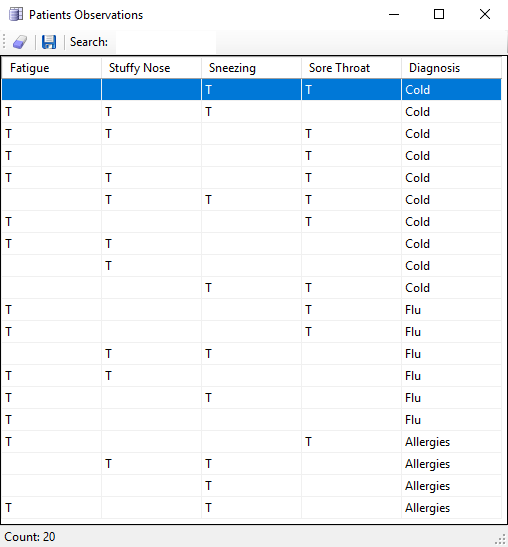
- Reading the Patient’s Historical Data During this first stage of the FlexRule project, the patient’s data is read from a Data Sheet (in this case a CSV file). This data sheet includes 20 patients, all of whom have different symptoms associated with their doctor’s final diagnoses and associated lab tests. For example, the patient on the first row experienced a sore throat and sneezing, whereas the second patient did not have a sore throat, but did have a stuffy nose, as well as symptoms of fatigue. Both patients were subsequently diagnosed with colds.
- Use the Naïve Bays (NB) Algorithm to train the model The next step is to train the new predictive model or reload an existing model by using the Naïve Bayes (NB) algorithm. This is a scalable classification algorithm for the type of dataset used in the FlexRule project. The NB algorithm is often applied successfully to medical problems with large repositories of data and features. At this point, the FlexRule model is ready to predict a diagnosis for patients who display similar symptoms to those already assessed.
- Predict the Diagnosis
In the final step, the data relating to a new patient’s symptoms is passed to the predictive model. For example:
{
“Fatigue”: null,
“Stuffy Nose”: “T”,
“Sneezing”: “T”,
“Sore Throat”: “T”
}
Using all of the available historical data allied with the new patient’s symptoms, the FlexRule predictive model now calculates the percentage probability of particular diagnoses as shown below:
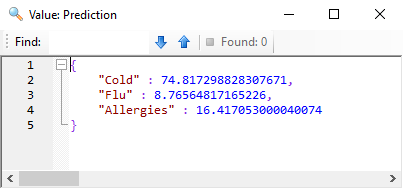
In this example, it is very clear that our new patient will most likely be diagnosed as having a cold, as the probability is shown as 74.81%. The probability of our patient having the flu or allergies is 8.76% and 16.41% respectively.
While this is a very simple example, it shows how FlexRule and predictive modelling can help a doctor make better quality patient diagnosis.
No doubt most patients would also agree with this type of approach to medical diagnoses!
Read more here.
* Ian Ayres; Super Crunchers, How anything can be predicted, page 97
{kind=link}