

The still young discipline of the management and governance of knowledge graphs (KG) is gradually beginning to consolidate on the basis of concrete project experience. It has been clearly recognized that the underlying methodology is multidisciplinary and that it cannot simply be covered by existing, often classical roles and skills in data and information management. Rather, there is a need for new roles in which the ‘Knowledge Scientist‘ is to be given a central position because he or she is able to bring together the two archetypical, sometimes rivalling roles of the ‘Data Engineer‘ and the ‘Knowledge Engineer‘.
What an enterprise knowledge graph (EKG) is and how it is created, there are (at least) two different answers to that in the current discourse. These two points of view are often understood as if they were mutually exclusive and incompatible; however, these are two approaches to semantic data modeling that should be combined in the concrete development of a knowledge graph. For practitioners and potential users, these supposed opposites naturally cause confusion, because the two approaches are often understood as alternatives to each other, if presented in simplified form. Here are the two views in simple words:
Approach 1—Principle ‘Knowledge’: A knowledge graph is a model of a knowledge domain that is curated by corresponding subject-matter experts (SMEs) with the support of knowledge engineers, e.g., taxonomists or ontologists, whereby partially automatable methods can be used. Knowledge domains can overlap and represent in most cases only a subdomain of the entire enterprise. Knowledge modelers tend to create specific, expressive and semantically rich knowledge models, but only for a limited scope of an enterprise. This approach is mainly focused on the expert loop within the entire knowledge graph lifecycle.
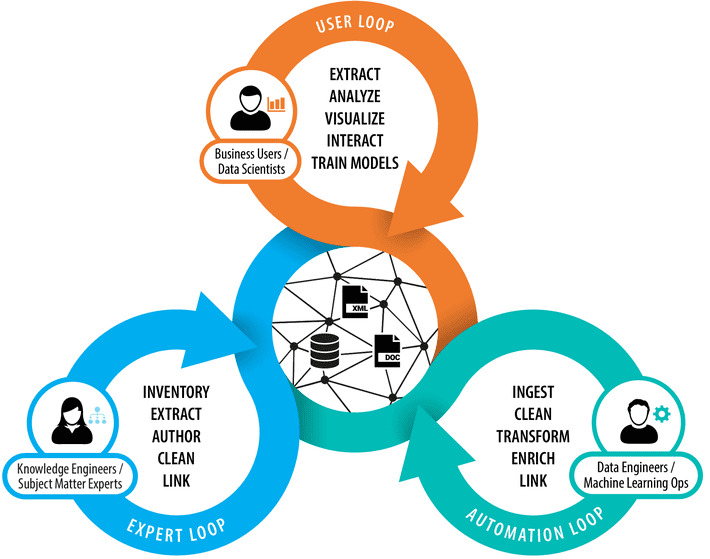
Approach 2—Principle ‘Data’: A knowledge graph is a graph-based representation of already existing data sources, which is created by data engineers with the help of automatable transformation, enrichment and validation steps. Ontologies and rules play an essential role in this process, and data lineage is one of the most complex problems involved. In this approach, data engineers focus on the automation loop of the KG lifecycle and aim to reuse and integrate as many data sources as possible to create a data graph. The ontologies and taxonomies involved in this approach provide only the level of expressiveness needed to automate data transformation and integration.
With the principle ‘Data’, the graph-based representation of often heterogeneous data landscapes moves into the center so that it can roll out agile methods of data integration (e.g., ‘Customer 360’), data quality management, and extended possibilities of data analysis.
The ‘Knowledge’ principle, on the other hand, introduces to a greater extent the idea of linking and enriching existing data with additional knowledge as a means to, for example, support knowledge discovery, automated reasoning, and in-depth analyses in large and complex databases.
So, are these two approaches mutually exclusive? The acting protagonists and proponents of both scenarios look at the same corporate knowledge from two different perspectives. This sometimes seems as if they are pursuing different goals, especially when participants’ mindsets can vary significantly.
The view of ‘Knowledge engineers’: Approach 1 involves knowledge modelers/engineers, computer linguists and partly also data scientists who have a holistic view of data, i.e., they want to be able to link data and bring it into new contexts in order to be able to provide extended possibilities for data analysis, knowledge retrieval, or recommender systems. This is done without ‘container thinking’, no matter whether information or facts are locked up in relational databases or proprietary document structures, they should be extracted and made (re-)usable. Proponents of approach 1 often assume that the data quality—especially of so-called ‘structured data’—is high enough for fully automated approaches, which is seldom the case in reality. Accordingly, the phase of data preparation and data transformation involving ontologies to build a robust nucleus for a knowledge graph at scale is underestimated, thus there is a risk of unnecessarily increasing the proportion of manual work in the long run.
The view of ‘Data engineers’: Approach 2 mainly employs data engineers who want to solve various problems in enterprise data management, e.g., insufficient data quality, cumbersome data integration (keyword: data silos), etc. This is often done independently from concrete business use cases. Restrictions due to rigid database schemata are a central problem that should be addressed by knowledge graphs. Data engineers see ontologies as central building blocks of an EKG, sometimes ontologies are even equated with a KG. Taxonomic relationships between entities and unstructured data (e.g., PDF documents) are often ignored and find no or merely a subordinate place in the design of a data engineer’s KG, where the danger exists that one might waive existing data sources unnecessarily. Approach 2 therefore, creates a virtual data graph that mirrors existing data virtually 1:1. The focus is more on data integration and better accessibility rather than enriching the data with further knowledge models.
Obviously, both approaches and mindsets have good reasons to work with graph technologies, and they each involve different risks of having produced significant gaps and relying on inefficient methods at the end of the journey to develop a fully-fledged enterprise knowledge graph. The way out is therefore to network both directions of thought and to get the respective proponents out of their isolation. How can this be achieved? How can knowledge engineers, data engineers and their objectives be linked?
The view of ‘Knowledge scientists’: Knowledge scientists combine the more holistic and connected views of the knowledge engineers with the more pragmatic views of the data engineers. They interact with knowledge graphs, extract data from them to train new models and provide their insights as feedback for others to use. Knowledge scientists work closely together with businesses and understand their actual needs, which are typically centered around business objects and facts about them. Ultimately, this leads to a more complete and entity-centric view of knowledge graphs that produce so-called 360-degree views (e.g., Customer 360, Product 360, etc.).
Approach 3—Principle ‘Entity’: A knowledge graph is a multi-layered, multidimensional network of entities and introduces a fundamentally new perspective on enterprise data: the entity-centric view. Each layer of a KG represents a context in which a business object, represented by an entity, can occur. Each dimension represents a way to look at an entity that occurs in a particular data source, whether structured, semi-structured, or unstructured. KGs contain facts about entities that can be very concrete but also abstract, and are represented in the form of instance data, taxonomies, and ontologies. In this approach, the knowledge and data perspectives are consolidated and the business users’ perspective is included.
Conclusion: While some work on linking existing data (“data graphs”) and others mainly focus on the development of semantic knowledge models (“semantic graphs”), a third perspective on knowledge graphs, which includes the user perspective has become increasingly important: “entity graphs”. The focus is on all relevant business objects including the users themselves, which in turn, should be linked to all facts from the other two layers. This clearly entity-centered view of the knowledge graph ultimately introduces the business view. All the questions that are linked to the respective business objects are formulated by the ‘knowledge scientist’ and partly answered with the help of machine learning methods, partly by SMEs and then returned to the knowledge graphs.
{kind=link}