
That’s correct. 1 server and 10 lines of code are all you need to search among 1 billion images in a few hundred milliseconds. Its ease of use a few lines of code to handle massive-scale reverse image search. Its superior standalone performance satisfies your need for low-latency, real-time searches. Its support for distributed systems and cloud-native extensions can always deal with 10-billion or 100-billion scale searches. It is Milvus, a fantastic vector search engine with high performance. On November 5, the Milvus team officially declared Milvus an open source project in GitHub for developers and AI scientists across the globe.
Unstructured Data, AI, and Vector Search
With the development of information technology, we are experiencing both data explosion and interesting changes of data types. Since the advent of electronic computers in the mid 1900s, developers have been processing structured data (integers and floats, etc.), semi-structured data (webpages and logs) in the internet era around 2000, and unstructured data (images, videos, voices, and texts, etc.) in the AI era around 2012.
For each type of data, computer scientists have created indexing algorithms to organize, search, and analyze data. For structured data, common indexing algorithms include Bitmap, hash table, and B-tree that are used in relational databases such as Oracle and DB2. For semi-structured data, common indexing algorithms include Inverted Index that are used in search engines such as Solr and ElasticSearch.
It is difficult to use traditional computation methods and processors to process and mine unstructured data. This bottleneck in computer science did not have a breakthrough before the advent of AI algorithms, which uses models (CNN, RNN, VGG, and BERT, etc.) to convert images, videos, voices, and texts to corresponding feature vectors. Each feature vector is composed of a string of integers or floats. AI algorithms convert complex unstructured data processing to vector computations that are more friendly to computer processors. Tasks such as reverse image search, reverse video search, and natural language processing (NLP) become computations of vector similarities based on Euclidean distance or cosine similarity.
AI algorithms convert unstructured data to vectors
Although it is relatively simple to compute vector similarity, the quantity of unstructured data is much larger than traditional structured and semi-structured data (by more than 3 orders of magnitudes) and grows faster (1 KB of structured data is generated with 1 GB unstructured data). Similarity computation of massive-scale vectors have become one of the challenges of large-scale deployment of AI algorithms. Thus, ANNS (Approximate Nearest Neighbor Search) comes into being. ANNS clusters similar vectors to decrease the search space and reduce computation load, resulting in faster vector search speed. Common ANNS algorithms include quantization, tree, graph, and combined algorithm (tree-graph, quantization-graph), etc.
A High-Performance Vector Search Engine
Using the world-leading ANNS indexing technique, Milvus has a 99% recall rate of top 5 search. The data loading speed reaches more than 1 million entries per minute. Milvus supports heterogenous acceleration and is compatible with x86/GPU/ARM/Power architecture. In the future, It will also support TPU and other ASIC processors. In the standalone scenario, Milvus can search among billion-scale vectors within a second. Distributed systems and cloud-native extensions can also deal with 10-billion or 100-billion scale searches. Milvus is licensed under Apache License, Version 2.0.
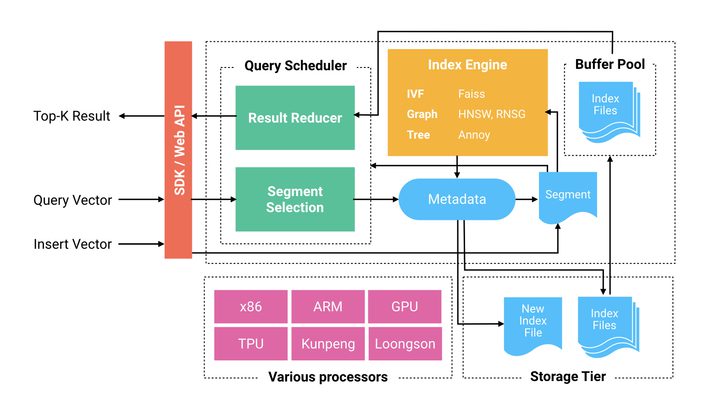
Milvus architecture
During the development of Milvus, we did deep research into the ANNS algorithm and went through lots of thesis and references. We constantly adjusted the hardware and software architecture, carefully designed and adjusted each algorithm, and implemented numerous optimizations per different processors and instruction sets. In summary, we have completed more than 3,600 commits, 5 versions, and 70,000 lines of source code.
After 300 days of hard work, we finally released the first stable version of Milvus, 0.5.1, and completed rigorous tests and production deployment in multiple well-known technology companies. We open sourced Milvus recently to help more developers deal with opportunities and challenges in unstructured data for more AI scenarios. We also wish to attract a group of geeks to our open source community to continue developing and improving Milvus. Our goal is to make Milvus a next-generation search engine for unstructured data with global influence.
Application Scenarios
So, what are some of the fields that we can apply Milvus to? For example, an e-commerce website contains about 50 million product SKUs. In average, each product has 20 images from vendors and customer comments. 1 billion images are stored in the backend in total. Developers can use pre-trained AI models to convert these 1 billion images to 1 billion feature vectors and then use Milvus to search products by images. Thus, customers can conveniently find their favorite products via reverse image searches.
Apart from reverse image searches, Milvus can also handle massive-scale unstructured data, such as videos, voices, and texts. For example, 1 million short videos are uploaded to a video UGC website per day and each short video is 1 minute in length and 720 P in resolution. For every 2 seconds, a keyframe image is retrieved. There will be 900 million keyframes per month and 10.8 billion keyframes per year. Developers can use AI models to convert 10.8 billion keyframes to 10.8 billion vectors and then use Milvus to perform reverse video searches so that users can conveniently navigate to their interested video fragments.
Milvus can also help NLP developers deal with tasks such as massive-scale duplicate text detection and semantics search. In this way, search engine developers can implement recommendation systems and precise advertising.
Currently, Milvus is adopted by more than 10 renowned technology companies to boost fields such as internet entertainment (reverse image/video search), new retail (product search by image), intelligent finance (user authentication), and smart logistics (vehicle identification), etc.
If you would like to experience using 10 lines of code to search among 1 billion images, please refer to the see here .
{kind=link}