

As Covid-19 continues to shape the global economy, analytics and business intelligence (BI) projects can help organisations prepare and implement strategies to navigate the crisis. According to the Covid-19 Impact Survey by Dresner Advisory Services, most respondents believe that data-driven decision-making is crucial to survive and thrive during the pandemic and beyond. This article provides a step-by-step overview of the typical data science project life cycle, including some best practices and expert advice.
Results of a survey by OReilly show that enterprises stabilise their adoption patterns for artificial intelligence (AI) across a wide variety of functional areas.
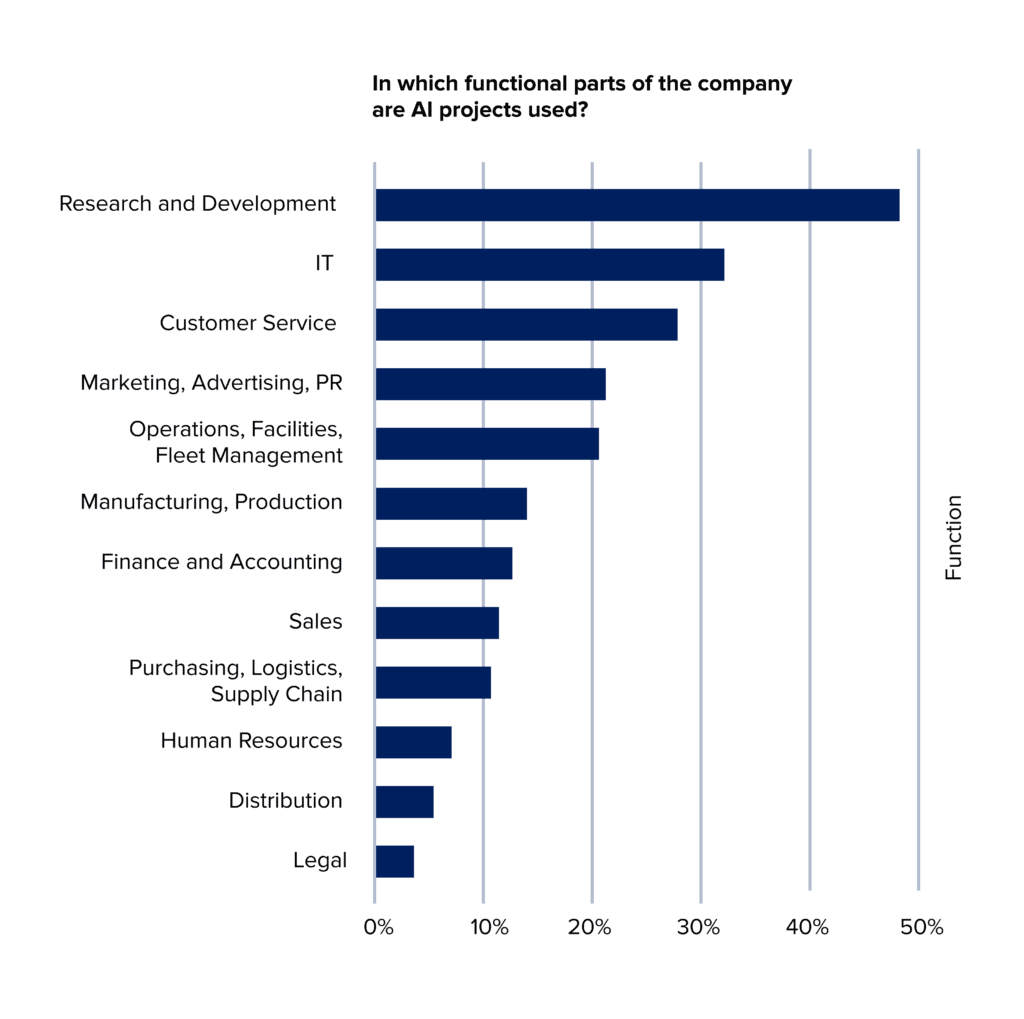
The same survey shows that 53% of enterprises using AI today recognise unexpected outcomes and predictions as the greatest risk when building and deploying machine learning (ML) models.
Being an executive person driving and overseeing data science adoption in your organisation, what can you do to achieve a reliable outcome of your data modelling project while getting the best ROI and mitigating security risks at the same time?
The answer lies in thorough project planning and expert execution at every stage of the data science project life cycle. Whether you use your in-house resources or outsource your project to an external team of data scientists, you should:
- Define a business need or a problem that can be solved by data modelling
- Have an understanding of the scope of work that lies ahead
Heres our rundown of a data science project life cycle, including the six main steps of the cross-industry standard process for data mining (CRISP-DM) and additional steps from data science solutions that are essential parts of every data science project. This roadmap is based on decades of experience in delivering data modelling and analysis solutions for a range of business domains, including e-commerce, retail, fashion and finance. It will help you avoid critical mistakes from the start and ensure smooth rollout and model deployment down the line.
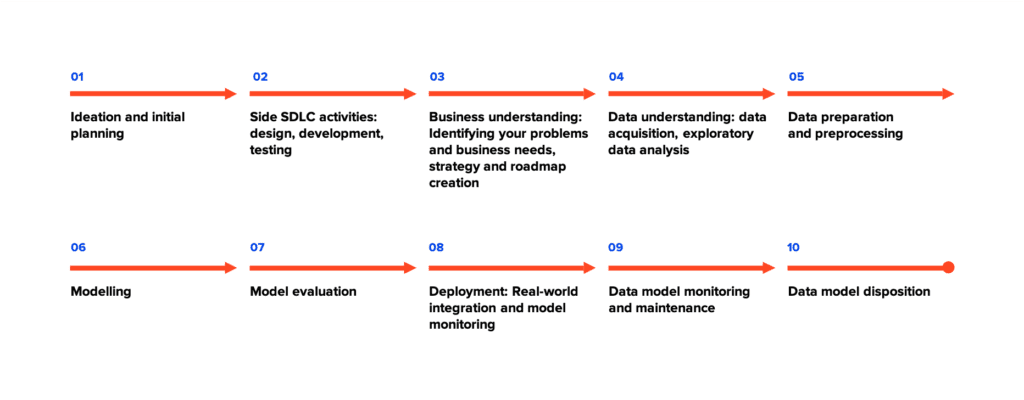
A typical data science project life cycle step by step
1. Ideation and initial planning
Without a valid idea and a comprehensive plan in place, it is difficult to align your model with your business needs and project goals to judge all of its strengths, its scope and the challenges involved. First, you need to understand what business problems and requirements you have and how they can be addressed with a data science solution.
At this stage, we often recommend that businesses run a feasibility study exhaustive research that allows you to define your goals for a solution and then build the team best equipped to deliver it. There are usually several other software development life cycle (SDLC) steps that will run in parallel with data modelling, including solution design, software development, testing, DevOps activities and more. The planning stage is to ensure you have all required roles and skills in your team to make the project run smoothly through all of its stages, meet its purpose and achieve its desired progress within the given time limit.
2. Side SDLC activities: design, software development and testing
As you kick off your data analysis and modelling project, several other activities usually run in parallel as parts of the SDLC. These include product design, software development, quality assurance activities and more. Here, team collaboration and alignment are key to project success.
For your model to be deployed as a ready-to-use solution, you need to make sure that your team is aligned through all the software development stages. Its essential for your data scientists to work closely with other development team members, especially with product designers and DevOps, to ensure your solution has an easy-to-use interface and that all of the features and functionality your data model provides are integrated there in the way thats most convenient to the user. Your DevOps engineers will also play an important role in deciding how the model will be integrated within your real production environment, as it can be deployed as a microservice, which facilitates scaling, versioning and security.
When the product is subject to quality assurance activities, the model gets tested within the teams staging environment and by the customer.
3. Business understanding: Identifying your problems and business needs, strategy and roadmap creation
The importance of understanding your business needs, and the availability and nature of data, cant be underestimated. Every data science project should be business first, hence defining business problems and objectives from the outset.
And in the initial phase of a data science project, companies should also set the key performance indicators and criteria that will be indicative of project success. After defining your business objectives, you should assess the data you have at your disposal and what industry/market data is available and how usable it is.
- Situational analysis. Experienced data scientists should be able to assess your current operational performance, then define any challenges, bottlenecks, priorities and opportunities.
- Defining your ultimate goals. Undertake a rigorous analysis of how your business goals match the modelling approach and understand where the gaps in performance and technology are to define the next steps.
- Building your data modelling strategy. When defining your strategy, two aspects are essential your assets available and how well the potential strategy answers your business goals before building business cases to kick start the process.
- Creating a roadmap. After you have a strategy in place, you need to design a roadmap that encompasses programs that will help you reach your goals, what the key objectives are within each program and all necessary project milestones.
The most important task within the business understanding stage is to define whether the problem can be solved by the available or state-of-the-art modelling and analysis approaches. The second most important task is to understand the domain, which allows data scientists to define new model features, initiate model transformations and come up with improvement recommendations.
4. Data understanding: data acquisition and exploratory data analysis
The preceding stages were intended to help you define your criteria for data science project success. Having those available, your data science team will be able to prepare your data for analysis and recommend which data to use and how.
The better the data you use, the better your model is. So, an initial analysis of data should provide some guiding insights that will help set the tone for modelling and further analysis. Based on your business needs, your data scientists should understand how much data you need to build and train the model.
How can you tell good data from bad data? Data quality is imperative, but how are you to know if your information really isnt up to the required standard? Here are some of the red flags to watch out for:
- It has missing variables and cannot be normalised to a unique basis.
- The data has been collected from lots of very different sources. Information from third parties may come under this banner.
- The data is not relevant to the subject of the algorithm. It might be useful, but not in this instance.
- The data contains contradicting values. This could see the same values for opposing classes or a very broad variation inside one class.
- Upon meeting any one of these red flags, theres a chance that your data will need to be cleaned prior to your implementation of an ML algorithm.
Types of data that can be analysed include financial statements, customer and market demand data, supply chain and manufacturing data, text corpora video and audio, image datasets, as well as time series, logs and signals.
Some types of data are a lot more costly and time-consuming to collect and label properly than others; the process can take even longer than the modelling itself. So, you need to understand how much cost is involved, how much effort is needed and what outcome you can expect, as well as your potential ROI before you make a hefty investment in the project.
5. Data preparation and preprocessing
Once youve established your goals, gained a clear understanding of the data needed and acquired the data, you can move on to data preprocessing. The best method for this depends on the nature of the data you have: there are, for example, different time and cost ramifications for text and image data.
Its a pivotal stage, and your data scientists need to tread carefully when theyre assessing data quality. If there are data values missing and your data scientists use a statistical approach to fill in the gaps, it could ultimately compromise the quality of your modelling results. Your data scientists should be able to evaluate data completeness and accuracy, spot noisy data and ask the right questions to fill any gaps, but its essential to engage domain experts, for consultancy.
Data acquisition is usually done through an Extract, Transform and Load (ETL) pipeline.

The ETL (Extract, Transform and Load) pipeline
ETL is a process of data integration that includes three steps that combine information from various sources. The ETL approach is usually applied to create a data warehouse. The information is extracted from a source, transformed into a specific format for further analysis and loaded into a data warehouse.
The main purpose of data preprocessing is to transform information from images, audio, log, and other sources into numerical, normalised, and scaled values. Another aim of data preparation is to cleanse the information. Its possible that your data is usable; it just serves no outlined purpose. In such a case,70%-80% of total modelling time¯may be assigned to data cleansing or replacing data samples that are missing or contradictory.
In many situations, you may need additional feature extraction from your data (like calculating the square from the room width and length for the rent price estimation).
Proper preparation from kick-off will ensure that your data science project gets off on the right foot, with the right goals in mind. An initial data assessment can outline how to prepare your data for further modelling.
6. Modelling
We advise that you start from proof of concept (PoC) development, where you can validate initial ideas before your team starts pre-testing on your real-world data. After youve validated your ideas with a PoC, you can safely proceed to production model creation.
Define the modelling technique
Even though you may have chosen a tool at the business understanding stage, the modelling stage begins with choosing the specific modelling technique youll use. At this stage, you generate a number of models that are set up, built and can be trained. ML models linear regression, KNN, Ensembles, Random Forest, etc. and deep learning models RNN, LSTN and GANs are part of this step.
Come up with a test design
Before model creation, the testing method or system should be developed to review the quality and validity. Lets take classification as a data mining task. Error rates can be used as quality measures; thus, you can separate datasets in train, validation sets. And build the model using a train set and make a quality assessment based on the separate test set (a validation set is used for the model/approach selection, not for the final error/accuracy measurement).
Build a model
To develop one or more models, use the modelling tool on the arranged dataset.
- Parameter settings¯ modelling tools usually allow the adjustment of a wide range of parameters. Make a parameters rundown with their chosen values together with the parameter settings choice justification.
- Models¯ models suggested by the modelling tool and not the models report.
- Model descriptions¯ outline the resulting models, report the models interpretations and detail any issues with meanings.
7. Model evaluation
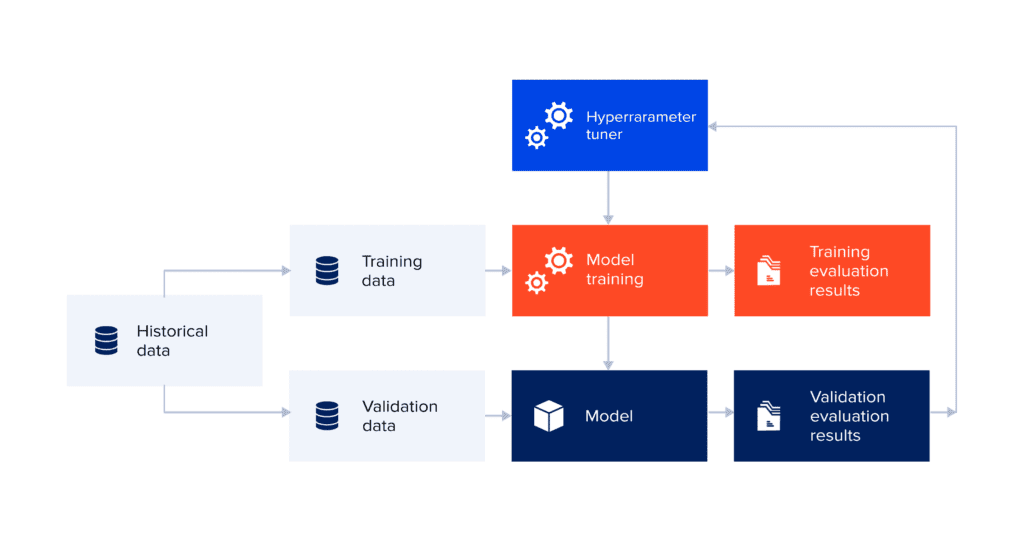
Model selection during the prototyping phase
To assess the model, leverage your domain knowledge, criteria of data mining success and desired test design. After evaluating the success of the modelling application, work together with business analysts and domain experts to review the data mining results in the business context.
Include business objectives and business success criteria at this point. Usually, data mining projects implement a technique several times, and data mining results are obtained by many different methods.
- Model assessment¯ sum up task results, evaluate the accuracy of generated models and rank them in relation to each other.
- Revised parameter settings¯ building upon the evaluation of the model, adjust parameter settings for the next run. Keep modifying parameters until you find the best model(s). Make sure to document modifications and assessments.
Here are some methods used by data scientists to check a models accuracy:
- Lift and gain charts¯ used for problems in campaign targeting to determine target customers for the campaign. They also estimate the response level you can get from a new target base.
- ROC curve¯ performance measurement between the false positive rate and true positive rate.
- Gini coefficient¯ measures the inequality among values of a variable.
- Cross-validation¯ dividing data into two or three parts; the first is used for model training and the second for the approach selection, and then the third, the test set, is used for the final model performance measurement.
- Confusion matrix¯ a table that compares each classs number of predictions to its number of instances. It can help to define the models accuracy, true positive, false positive, sensitivity and specificity.

The confusion matrix
- Root mean squared error¯ the average amount of error made. Most used in regression techniques; help to estimate the average amount of wrong predictions.
The assessment method should fit your business objectives. When you turn back to preprocessing to check your approach, you can use different preprocessing techniques, extract some other features and then turn back to the modelling stage. You can also do factor analysis to check how your model reacts to different samples.
8. Deployment: Real-world integration and model monitoring
When the model has passed the validation stage, and you and your stakeholders are 100% happy with the results, only then you can move on to full-scale development integrating the model within your real production environment. The role of engineers like DevOps, MLOps and DB is very important at this stage.
The model consists of a set of scripts that process data from databases, data lakes and file systems (CSV, XLS, URLs), using APIs, ports, sockets or other sources. Youll need some technical expertise to find your way around the models.
Alternatively, you could have a custom user interface built, or have the model integrated with your existing systems for convenience and ease of use. This is easily done via microservices and other methods of integration. Once validation and deployment are complete, your data science team and business leaders need to step back and assess the projects overall success.
9. Data model monitoring and maintenance
A data science project doesnt end with the deployment stage; the maintenance step comes next. Data changes from day to day, so a monitoring system is needed to track the models performance over time.
Once the models performance falls down, monitoring systems can indicate whether a failure needs to be handled, or whether a model should be retrained, or even whether a new model should be implemented. The main purpose of maintenance is to ensure a systems full functionality and optimal performance until the end of its working life.
10. Data model disposition
Data disposition is the last stage in the data science project life cycle, consisting of either data or model reuse/repurpose or data/model destruction. Once the data gets reused or repurposed, your data science project life cycle becomes circular. Data reuse means using the same information several times for the same purpose, while data repurpose means using the same data to serve more than one purpose.
Data or model destruction, on the other hand, means complete information removal. To erase the information, among other things, you can overwrite it or physically destroy the carrier. Data destruction is critical to protect privacy, and failure to delete information may lead to breaches, compliance problems among other issues.
Conclusion
AI will keep shaping the establishment of new business, financial and operating models in 2021 and beyond. The investments of world-leading companies will affect the global economy and its workforce and are likely to define new winners and losers.
The lack of AI-specific skills remains a primary obstacle on the way to adoption in the majority of organisations. In the survey by OReilly, around 58% of respondents typically mentioned the shortage of ML modellers and data scientists, among other skill gaps within their organisations.
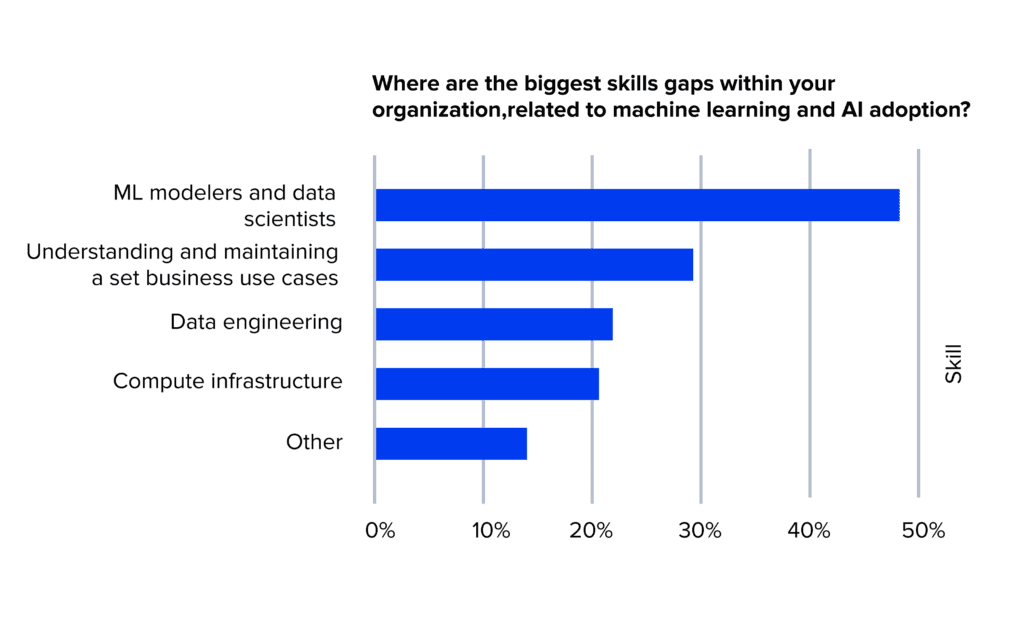
Source: AI adoption in the enterprise 2020
Having questions on how your data can be used to help you boost your business performance? We will be happy to answer them. Drop us a line.
Originally published at ELEKS Labs blog.
{kind=link}