
Right on cue, this past week heralded in an announcement of OpenAI, a new non-profit started by a number of tech luminaries to spearhead AI research that is publicly accessible. The motivation is that apparently these scions of capitalism lose faith in Adam Smith’s invisible hand when it comes to AI R&D. Musk continues to promote the idea that AI will be humanity’s largest existential threat. Challenging this view, the HBR asks if “OpenAI [is] Solving the Wrong Problem“, pointing to the implied lack of trust in capitalism. This is similar to my own parry: that the biggest existential threat to humanity is humanity. Under this premise, the idea of focusing on AI/human symbiosis seems downright crazy, since AI don’t have amygdalas.
Credit: Karlsruhe Institute of Technology, et al.
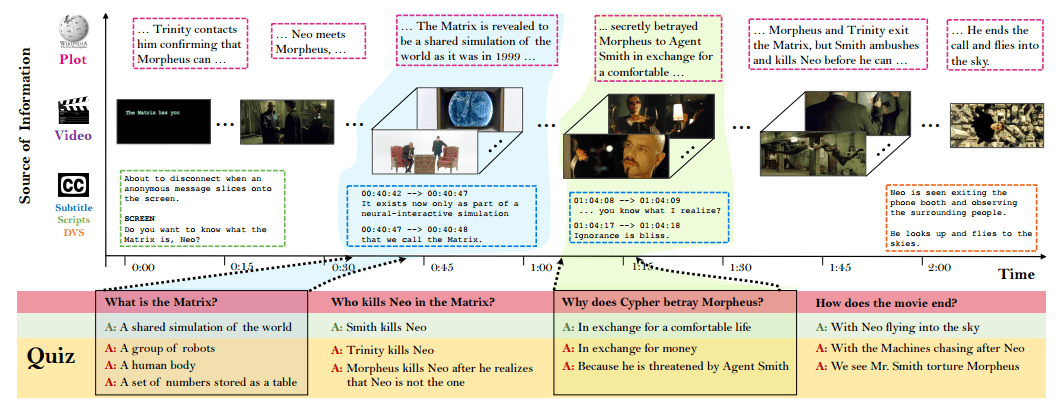
Returning to more tangible issues, the HBR article notes that the organizations best able to exploit the knowledge coming out of OpenAI would be those with the most computational resources and best data. This is no different from the status quo, since most research is already public. This is basically an extension of the academic system, which already follows this model. Research institutions, whether academic or corporate, know the value of publicly publishing research. The secret sauce is still the data, along with the methodology for encoding information. A good example of this is research from Karlsruhe Institute of Technology, MIT, and U Toronto on using deep learning for story comprehension. This is impressive research with a lot of moving parts (video frames, script dialogue, Q&A). Judging from the article and the associated paper, at its core the system appears to be a probabilistic classifier that uses video frames and dialogue as supplementary data. Again the point is how important the dataset and the encoding of the data is to the overall solution.
Deep Learning
I spent the better part of the weekend setting up TensorFlow. Initially I tried installing the GPU version on my laptop, which has 384 CUDA cores. However, TensorFlow only supports version 7.0 of the NViDIA CUDA drivers on Ubuntu 14, which is not compatible with my system (Ubuntu 15). So I switched to building a new machine with the Tesla K80 that has 4992 cores and 24 GB memory. Getting CUDA configured is not as simple as it could be, but with some grit you can do it. You definitely need to have good working knowledge of Linux to do so. Combined with TensorFlow, you need to really pay attention to version numbers of all pieces, or you might end up with esoteric errors.
Having tinkered a bit more with TensorFlow and also the GenSim Word2Vec library, my assessment is that you should only use TensorFlow if you intend to do AI research. Otherwise, use something with a high-level interface, like GenSim.
For R users, the best choice for deep learning appears to be H2O. It is easy to set up and their R library is nicely designed. This is to be expected since Trevor Hastie and Rob Tibshirani are on the advisory board. H2O can run atop Hadoop and Spark while also being able to cluster on its own. The primary drawback I see is that there is no GPU support. But if you don’t have an Nvidia Tesla lying about, you’re probably better off using H2O over multiple machines.
JIT in R
A user of my futile.logger logging package submitted a pull request to enable JIT for the package. Just-in-time compilation is an optimization technique popularized by Java. In short, it compiles bits of code on the fly and caches them for reuse. Think of it as memoisation for functions. Tal Gilili has a great overview of JIT in R that is worth a read. One thing that isn’t mentioned is how to enable JIT for a whole package. To do this, simply add ByteCompile: yes to your DESCRIPTION file, and you’re all set! This is a great example of how R has become more user friendly over time.
There are two drawbacks to JIT: 1) it can reduce the initial load time of you package, and 2) it can add to the file size of the built package. Most of the time, this shouldn’t be significant, so give it a go.
Something Wow
East Coast readers are either lapping up the lovely weather or are lamenting the probable lack of a ski/ice season this year. This December has blown past numerous records and has been in the 70s as far north as Virginia. Here in NY, the Japanese maples are just losing their leaves, and we still have some roses in bloom. If this keeps up, southern winter real estate may soon be replaced by northern summer real estate.
Brian Lee Yung Rowe is Founder and Chief Pez Head of Pez.AI // Zato Novo, a conversational AI platform for data analysis. Learn more at Pez.AI. The original blog can be seen here.
.
{kind=link}