
GPT can be a great tool to write or summarize articles, and as a chatbot. But one of the most popular uses is to find information. In short, a better alternative to Google search. Yet, all the talk is about deep neural networks, transformers, and embeddings. And how GPT leverage these new technologies, using trillions of tokens.
However, there is some old technology behind this: gathering and organizing the input data. The quality of embeddings critically depends on it. In this article, I focus on this component, present in all LLMs. Along the way, I explain how to built a much faster, simpler system, that better meets your needs. I am currently building one for myself, and will share all the code and documentation later. Here, I provide a high level summary, of interest particularly to developers and professionals with a technical background, including stakeholders. To get an idea of what I am working on, look at Figure 1.
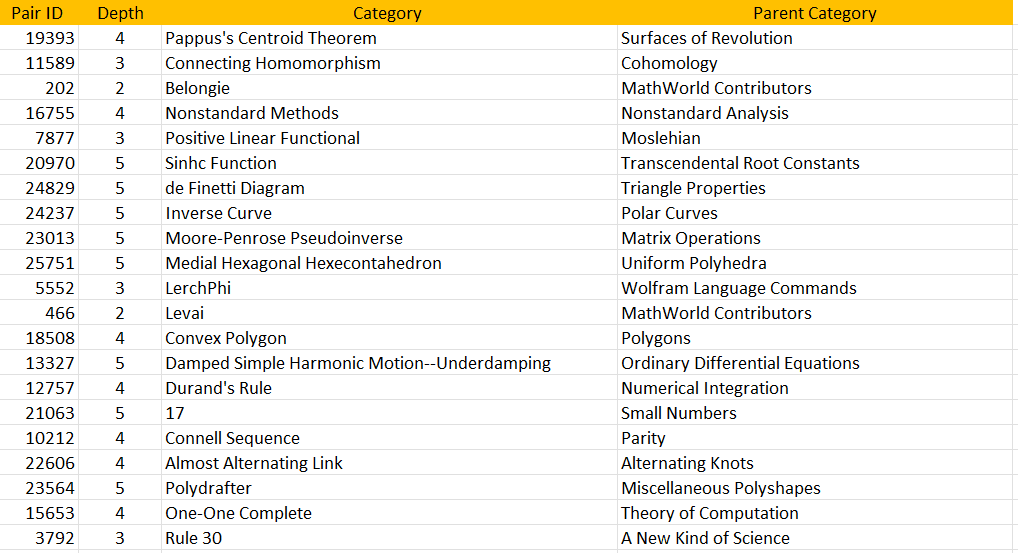
Background
Here I describe a typical case study. I was looking for a specific answer, regarding the “expected range for Gaussian distributions”. The reason I asked this question is as follows. Many GenAI systems cannot generate data outside the observation range in the training set. The result is poor synthetization, especially in the context of synthetic tabular data. The current fix consists in using gigantic training sets, when possible. But how do you generate observations outside the range, that is below the minimum or above the maximum? For instance, in clinical trials where training sets are small. Or if you want to save training time and costs, by using smaller training sets.
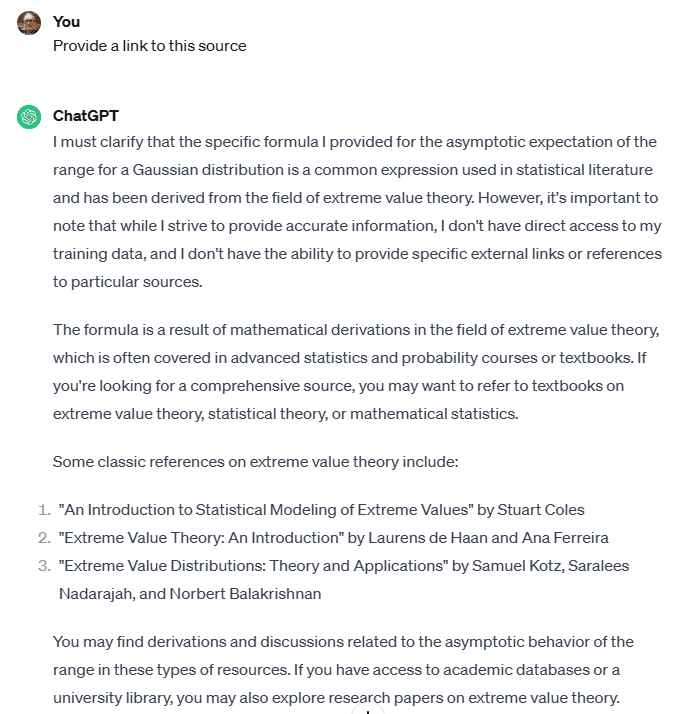
You need to have an idea of how far outside the range you can go, given the number of observations you want to generate and the size of your training set. Thus, the reason why I was interested in this problem, and why I asked GPT for help. Especially since Google and other tools were of no use. GPT did not correctly answer my prompt. But after a few trials, I realized it had access to the correct source, even though its answer was wrong. In particular, it was able to isolate the correct part,
E[R_n] \sim \sigma\sqrt{2\log n},where n is the number of observations, σ is the standard deviation, E is the expectation, and Rn is the range. In Figures 2 and 3, you can see the GPT answers to my prompts.


Main Issues with GPT
In my above example (and many others), GPT retrieves different pieces of data, via embeddings based on crawled content. Then it blends these pieces together. However, in the process, it mixes the correct answer with irrelevant information, resulting in a wrong answer. If only GPT could cite its sources, it would be easy, via a quick reference check, to uncover the correct solution. Yet, no matter how I ask it, GPT refuses to reveal its sources. See my attempts in Figures 4 and 5.

Here is another example. I was interested in a well-known alternative to Taylor series, using different types of polynomials. More specifically, how to write a function as
f(x) = A_0 + A_1 \cdot x + A_2\cdot x(x-1) + A_3 \cdot x(x-1)(x-2) + \cdots
What is the name of this series? How do you compute the coefficients? If you don’t know keywords such as factorial polynomials, exact interpolation, falling factorials, and backward differences, good luck obtaining a meaningful answer! I ended up in a few minutes solving this mathematical problem on my own, reinventing the wheel. It was much faster than using search tools or GPT. If you are curious, these are called Newton series, but I had forgotten the name. This is a result that was discovered several centuries ago, pre-dating Taylor series. I may use it in my articles or books, but usually without a proof for such elementary formulas. Instead, I like to provide a reference. Typically, a link.
The Real Secret Sauce in LLMs
Using high quality sources is the key to provide good answers. In my case, I don’t need nice English and long sentences stating rudimentary facts. A few links and bullet points will do. A specialized LLM should come with a very good taxonomy. It should know that when you are looking for “expectation of the range”, related keywords include “expectation of the maximum”, “rank statistics asymptotic theory”, “Gumbel distribution”, “extreme value theory”. And the fact that “shooting range” has nothing to do with it.
I found the answer to my question on Stack Exchange, in particular on the Cross-Validated website. Yet, the search boxes on these websites were of no help. Nor were the sections “related questions”. Nor was a Google search that included the names of these websites. I found it on my own, by looking for “asymptotic expectation of maximum for Gaussian distributions”. I knew that from there, I could reconstruct the formula for the range, on my own. Yet what I just mentioned can be fully automated. To this day, none of the tools I tried have that capability combined with the possibility to share the sources.
How to Use the Secret Sauce to Build your LLM
Here I explain how I solve this problem for myself. The difficulty is not crawling billions of webpages, or using trillion-parameter models, or sophisticated neural networks. My solution involves a few million webpages at most, and no neural network. The power is in the quality of the selected material to crawl, the ability to uncover and reconstruct great taxonomies (see Figure 1), and create high-quality keyword correlation tables. In short, good old-fashioned NLP combined with extensive knowledge of all the existing good sources. And efficient, smart, scalable crawling.
In my case, as I focus on mathematics and statistics for now, I started crawling Wolfram, a well structured website with great categorization. This will help create high-quality embeddings. I will use this initial architecture to selectively crawl ArXiv, Wikipedia, Google Scholar, Stack Exchange, and other places. I will crawl not only directories and webpages, but search result pages and “related topics” sections from various websites, as well as online indexes. Search queries used in my crawling will be enhanced thanks to good keyword associations further refined over time. I may even use GPT APIs to complement the material gathered by my tool. And unlike GPT, my tool will perform some real-time crawling when asked, to provide the most recent content. Of course, the goal is to return links, rather than English prose.
I just started. Smart crawling is not for the faint-hearted. It requires solid hacking and reverse-engineering skills. It also requires imagination, and a very good knowledge of the content (and quality sources) you are interested in. Which is why I believe this is the difficult part. I will share my progress on GitHub, here.
Author

Vincent Granville is a pioneering GenAI scientist and machine learning expert, co-founder of Data Science Central (acquired by a publicly traded company in 2020), Chief AI Scientist at MLTechniques.com and GenAItechLab.com, former VC-funded executive, author and patent owner — one related to LLM. Vincent’s past corporate experience includes Visa, Wells Fargo, eBay, NBC, Microsoft, and CNET.
Vincent is also a former post-doc at Cambridge University, and the National Institute of Statistical Sciences (NISS). He published in Journal of Number Theory, Journal of the Royal Statistical Society (Series B), and IEEE Transactions on Pattern Analysis and Machine Intelligence. He is the author of multiple books, including “Synthetic Data and Generative AI” (Elsevier, 2024). Vincent lives in Washington state, and enjoys doing research on stochastic processes, dynamical systems, experimental math and probabilistic number theory. He recently launched a GenAI certification program, offering state-of-the-art, enterprise grade projects to participants.
{kind=link}