
Overview of changes TensorFlow 1.0 vs TensorFlow 2.0
Earlier this year, Google announced TensorFlow 2.0, it is a major leap from the existing TensorFlow 1.0. The key differences are as follows:
Ease of use: Many old libraries (example tf.contrib) were removed, and some consolidated. For example, in TensorFlow1.x the model could be made using Contrib, layers, Keras or estimators, so many options for the same task confused many new users. TensorFlow 2.0 promotes TensorFlow Keras for model experimentation and Estimators for scaled serving, and the two APIs are very convenient to use.
Eager Execution: In TensorFlow 1.x. The writing of code was divided into two parts: building the computational graph and later creating a session to execute it. this was quite cumbersome, especially if in the big model that you have designed, a small error existed somewhere in the beginning. TensorFlow2.0 Eager Execution is implemented by default, i.e. you no longer need to create a session to run the computational graph, you can see the result of your code directly without the need of creating Session.
Model Building and deploying made easy: With TensorFlow2.0 providing high level TensorFlow Keras API, the user has a greater flexibility in creating the model. One can define model using Keras functional or sequential API. The TensorFlow Estimator API allows one to run model on a local host or on a distributed multi-server environment without changing your model. Computational graphs are powerful in terms of performance, in TensorFlow 2.0 you can use the decorator tf.function so that the following function block is run as a single graph. This is done via the powerful Autograph feature of TensorFlow 2.0. This allows users to optimize the function and increase portability. And the best part you can write the function using natural Python syntax. Effectively, you can use the decorator tf.function to turn plain Python code into graph. While the decorator @tf.function applies to the function block immediately following it, any functions called by it will be executed in graph mode as well. Thus, in TensorFlow 2.0, users should refactor their code into smaller functions which are called as needed. In general, it’s not necessary to decorate each of these smaller functions with tf.function; only use tf.function to decorate high-level computations – for example, one step of training, or the forward pass of your model. (source stack overflow and TF2 documentation)
To expand this idea, In TensorFlow 1.x we needed to build the computational graph. TensorFlow 2.0 does not build graph by default. However, as every Machine Learning engineer knows, graphs are good for speed. TensorFlow 2.0 provides the user to create a callable graph using a python function @tf.function. The tf.function() will create a separate graph for every unique set of input shapes and datatypes. In the example below we will have three separate graphs created, one for each input datatype.
@tf.function
def f(x): return tf.add(x, 1.)
scalar = tf.constant(1.0)
vector = tf.constant([1.0, 1.0])
matrix = tf.constant([[3.0]])
print(f(scalar))
print(f(vector))
print(f(matrix))
The Data pipeline simplified: TensorFlow2.0 has a separate module TensorFlow DataSets that can be used to operate with the model in more elegant way. Not only it has a large range of existing datasets, making your job of experimenting with a new architecture easier – it also has well defined way to add your data to it.
In TensorFlow 1.x for building a model we would first need to declare placeholders. These were the dummy variables which will later (in the session) used to feed data to the model. There were many built-in APIs for building the layers like tf.contrib, tf.layers and tf.keras, one could also build layers by defining the actual mathematical operations.
TensorFlow 2.0 you can build your model defining your own mathematical operations, as before you can use math module (tf.math) and linear algebra (tf.linalg) module. However, you can take advantage of the high level Keras API and tf.layers module. The important part is we do not need to define placeholders any more.
Simplified conceptual diagram for TensorFlow 2.0
A simplified, conceptual diagram as shown below for TensorFlow 2.0
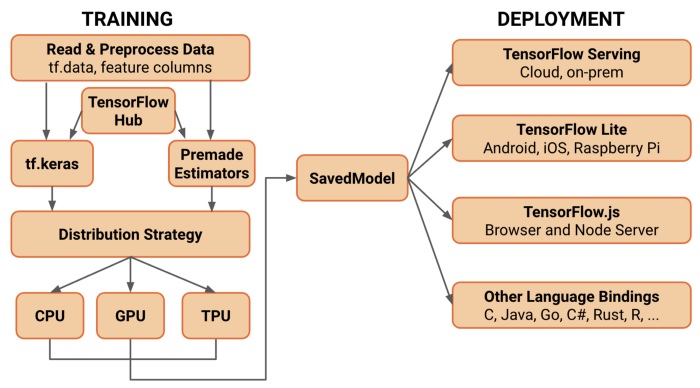
Source: https://medium.com/tensorflow/whats-coming-in-tensorflow-2-0-d36638…
Some important points are:
- Load your data using data. Training data is read using input pipelines which are created using tf.data.
- Use TensorFlow Dataset to get a large variety of datasets to train your model.
- Build, train and validate your model with keras, or use Estimators API.
- TensorFlow Hub in the TensorFlow ecosysytem contains a large number of pretrained models, using the standard interface, you can import any of the models from TensorFlow Hub and either train it from scratch or fine tune it for your data using transfer learning technique.
- Run and debug with eager execution, then use functionfor the benefits of graphs.
- Use Distribution Strategies for distributed training. For large ML training tasks, the Distribution Strategy APImakes it easy to distribute and train models on different hardware configurations without changing the model definition. You can distribute your training load to a range of hardware accelerators like CPUs, GPUs, and TPUs
- Although this API supports a variety of cluster configurations, templatesto deploy training on Kubernetes clusters in on-prem or cloud environments are provided.
- Export to SavedModel. TensorFlow will standardize on SavedModel as an interchange format for TensorFlow Serving, TensorFlow Lite, TensorFlow.js, TensorFlow Hub, and more.
- Once you’ve trained and saved your model, you can execute it directly in your application or serve it using one of the deployment libraries: TensorFlow Serving: A TensorFlow library allowing models to be served over HTTP/REST or gRPC/Protocol Buffers. TensorFlow Lite: TensorFlow’s lightweight solution for mobile and embedded devices provides the capability to deploy models on Android, iOS and embedded systems like a Raspberry Pi and Edge TPUs. js: Enables deploying models in JavaScript environments, such as in a web browser or server side through Node.js. TensorFlow.js also supports defining models in JavaScript and training directly in the web browser using a Keras-like API.
Above section adapted from https://medium.com/tensorflow/whats-coming-in-tensorflow-2-0-d36638…
Observations
On one hand, Tensorflow 2.0 does not feel new. Probably because even in the age of Tensorflow 1.0, almost everyone was using keras!. Keras is now central to Tensorflow 2.0 but Tensorflow 2.0 has much more features as we see above.
with contributions from Dr Amita Kapoor
{kind=link}