
Summary: Our starting assumption that sequence problems (language, speech, and others) are the natural domain of RNNs is being challenged. Temporal Convolutional Nets (TCNs) which are our workhorse CNNs with a few new features are outperforming RNNs on major applications today. Looks like RNNs may well be history.
 It’s only been since 2014 or 2015 when our DNN-powered applications passed the 95% accuracy point on text and speech recognition allowing for whole generations of chatbots, personal assistants, and instant translators.
It’s only been since 2014 or 2015 when our DNN-powered applications passed the 95% accuracy point on text and speech recognition allowing for whole generations of chatbots, personal assistants, and instant translators.
Convolutional Neural Nets (CNNs) are the acknowledged workhorse of image and video recognition while Recurrent Neural Nets (RNNs) became the same for all things language.
One of the key differences is that CNNs can recognize features in static images (or video when considered one frame at a time) while RNNs exceled at text and speech which were recognized as sequence or time-dependent problems. That is where the next predicted character or word or phrase depends on those that came before (left-to-right) introducing the concept of time and therefore sequence.
Actually RNNs are good at all types of sequence problems, including speech/text recognition, language-to-language translation, handwriting recognition, sequence data analysis (forecasting), and even automatic code generation in many different configurations.
In a very short period of time, major improvements to RNNs became dominant including LSTM (long short term memory) and GRU (gated recurring units) both of which improved the span over which RNNs could remember and incorporate data far from the immediate text into its meaning.
Solving the ‘Not’ Joke Problem
With RNNs reading characters or words from left-to-right in time, context became a problem. For example, in trying to predict the sentiment of a review, the first few comments might be positive (e.g. good food, good atmosphere) but might end with several negative comments (e.g. terrible service, high price) that might ultimately mean the review was negative. This is the logical equivalent of the ‘Not’ joke. ‘That’s a great looking tie. NOT!’.
The solution was to read the text in both directions at once by having two LSTM encoder working at once (bi-directional encoders). This meant having information from the future (further down the text) leaking into the present but it largely solved the problem. Accuracy improved.
Facebook and Google Have a Problem
Early on when Facebook and Google were launching their automatic language translators, they realized they had a problem. The translations were taking too long.
RNNs have an inherent design problem. Because they read and interpret the input text one word (or character) at a time, the deep neural network must wait to process the next word until the current word processing is complete.
This means that RNNs cannot take advantage of massive parallel processing (MPP) in the same way the CNNs can. Especially true when the RNN/LSTMs are running both ways at once to better understand context.
It also means they are very compute intensive since all the intermediate results must be stored until the processing of the entire phrase is complete.
In early 2017 both Google and Facebook came to similar solutions, a way to use CNNs with their MPP capability to process text for language-to-language translation. In CNNs the computation doesn’t rely on information from the previous time step, freeing each computation to be conducted separately with massive parallelization.
Google’s solution is called ByteNet, Facebook’s is FairSeq (named after their internal Facebook Artificial Intelligence Research (FAIR) team. FairSeq is available on GitHub.
Facebook says their FairSeq net runs 9X faster than their RNN benchmark.
How Does It Work – The Basics
Thinking about CNNs and how they process images as a 2D ‘patch’ (height and width), making the jump to text requires only that you think of text as a 1D object (1 unit high and n units long).
But while RNNs do not directly predefine object length, CNNs do so by definition. So using CNNs requires us to add more layers until the entire receptive field is covered. This can and does result in very deep CNNs, but with the advantage being, no matter how deep, each can be processed separately in parallel for the huge time savings.
The Special Sauce: Gating + Hopping = Attention
Of course it’s not quite as simple as that and both the Google and Facebook techniques add something called an ‘Attention’ function.
The original Attention function appears to have been introduced last year by researchers at Google Brain and the University of Toronto under the name Transformer. Read the original research paper here.
By the time the basically identical function was adopted by both Facebook and Google it had become the ‘Attention’ function which has two unique features.
The first is identified by Facebook as ‘multi-hoping’. Rather than the traditional RNN approach of looking at the sentence only once, multi-hoping allows the system to take multiple ‘glimpses’ of the sentence in a manner more like human translators.
Each glimpse might focus on a noun or verb, not necessarily in sequence, which offers the most insight into meaning for that pass. Glimpses might be independent or might be dependent on the previous look to then focus on a related adjective, adverb, or auxiliary verb.
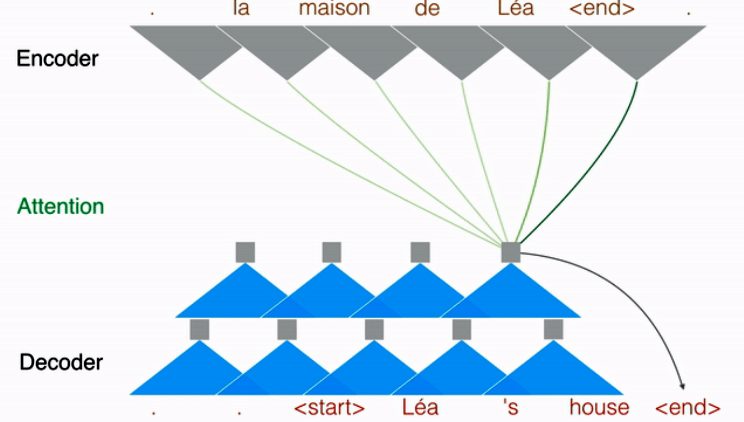 Facebook offers this illustration to show the first pass of the French-to-English translation is a single pass to encode each French word, then the multi-hoping routine of the decoder to select the most appropriate English translation.
Facebook offers this illustration to show the first pass of the French-to-English translation is a single pass to encode each French word, then the multi-hoping routine of the decoder to select the most appropriate English translation.
The second feature is gating which controls the information flow between the hidden layers. Gating determines what information best produces the next word by essentially allowing the CNN to zoom in or out on the translation in process to achieve the best context for making the next decision.
Beyond Language Translation – Temporal Convolutional Nets (TCNs)
By mid-2017 Facebook and Google had solved the problem of speed of translation by using CNNs combined with the attention function. The larger question however was this technique good for more than just speeding up translation. Should we be looking at all the problem types previously assumed to be solvable only with RNNs? And the answer of course is yes.
There were a number of studies published in 2017; some coming out literally at the same time that Facebook and Google published. One which does a good job of covering the broader question of what’s beyond translation is “An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling” by Shaojie Bai, J. Zico Kolter, and Vladlen Koltun (original here).
These are the folks who have labeled this new architecture Temporal Convolutional Nets (TCNs) though it’s possible that may change as the industry continues to implement them.
Their study is a series of head-to-head benchmark competitions of TCNs versus RNNs, LSTMs, and GRUs across 11 different industry standard RNN problems well beyond language-to-language translation.
Their conclusion: TCNs are not only faster but also produced greater accuracy in 9 cases and tied in one (bold figures in the table below drawn from the original study). 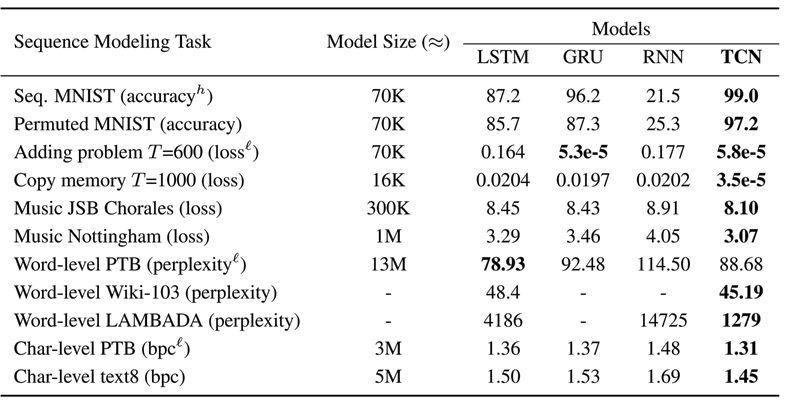
TCN Advantages / Disadvantages
Shaojie Bai, J. Zico Kolter, and Vladlen Koltun also provide this useful list of advantages and disadvantages of TCNs.
- Speed is important. Faster networks shorten the feedback cycle. The massive parallelism available with TCNs shortens both training and evaluation cycles.
- TCNs offer more flexibility in changing its receptive field size, principally by stacking more convolutional layers, using larger dilation factors, or increasing filter size. This offers better control of the model’s memory size.
- TCNs have a backpropagation path different from the temporal direction of the sequence. This avoids the problem of exploding or vanishing gradients which are a major issue with RNNs.
- Lower memory requirement for training, especially in the case of long input sequences.
However, the researchers note that TCNs may not be as easy to adapt to transfer learning as regular CNN applications because different domains can have different requirements on the amount of history the model needs in order to predict. Therefore, when transferring a model from a domain where only little memory is needed to a domain where much longer memory is required, the TCN may perform poorly for not having a sufficiently large receptive field.
Going Forward
TCNs have been implemented in major applications with significant benefits that appear to apply across all types of sequence problems. We’ll need to rethink our assumption that sequence problems are exclusively the domain of RNNs and begin to think of TCNs as the natural starting point for our future projects.
About the author: Bill Vorhies is Editorial Director for Data Science Central and has practiced as a data scientist since 2001. He can be reached at:
%20Take%20Over%20from%20RNNs%20for%20NLP%20Predictions){kind=link}