

The first open-source semantic triple store, the Apache Jena project, traces its origins back to the beginning of the Semantic Web, when HP released its first version in August of 2000. In August 2011, HP contributed Jena to the Apache project, which has continued to develop the software to the present day. While many commercial versions of what would become known as knowledge stores or knowledge engines have dominated the market since then, Jena has long been seen as one of the most current reference implementations of such knowledge engines to date. It is still the best open-source implementation, according to several different benchmarks.
While it is possible to run Jena as a stand-alone engine, in most cases, Jena is paired with the Fuseki HTTP servlet, which both provides a services layer for Jena and incorporates a (very minimal) UI server that can be used to load and query the database through a web interface. Realistically, most applications of the Jena-Fuseki (which I’ll refer to here as Jena collectively) will work through a services interface, often paired with a node.js or similar environment (such as the jena-tbd library).
Although Jena is often perceived as not “industrial grade”, it is nonetheless a surprisingly robust RDF graph database that supports features many older commercial databases don’t have. Its light footprint makes it ideal for running on a laptop, in a docker/Kubernetes container, or even embedded within physical devices. What’s more, Jena’s performance profile, while not as good as some commercial alternatives, is becoming respectable, especially for small-to-midsized triples (e.g., in the 10-100 million assertion range).
Jena’s Recent Enhancements
For those whose experience with Jena goes back to the early 2010s, there are several new capabilities that make Jena worth revisiting:
Support for Text Queries
A major use case for triple stores is to find content within text fields. Ordinarily (in SPARQL 1.1), this can be done with the CONTAINS() and REGEX() functions, which search each string object for either a specific sequence of text or a regular expression for text matching, respectively. However, these functions (run within a filter or bind context) are not indexed, which means that these queries can be very expensive to perform.
Jena currently supports the Lucene open text search (version 8.8) through the use of the text:query predicate:
PREFIX ex: <http://www.example.org/resources#>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX text: <http://jena.apache.org/text#>
SELECT ?s ?lbl
WHERE {
?s a ex:Product ;
text:query (rdfs:label 'printer') ;
rdfs:label ?lbl
}In this case, the text query passes a list of parameters used for identifying the indexed predicates and phrases that need to be contained within the associated triple objects. Note that for this to work, Jena must create a Lucene index. A configuration dataset written in RDF can define the specific types of indexes, making it possible to create specialized indexes for doing case insensitive searches, searches in specific languages, searching looking for terms within a certain distance of an anchor term, multiple OR’d terms, and so on.
Because text:query works against an indexed dataset, it will generally be much faster (and more flexible) than doing a contains() or regex() lookup.
Using the JSON keyword
SPARQL has supported the output of a “rows” of linear content from its inception, using the SELECT statement with the sparql-json mime-type to generate a structure that includes the keys as one element, then rows of structural data with metadata. For instance, if you have RDF data expressed as follows:
@prefix Class: <https://gameExample.org/ns/Class/>.
@prefix PC: <https://gameExample.org/ns/PC/>.
@prefix Entity: <https://gameExample.org/ns/Entity/>.
@prefix Character: <https://gameExample.org/ns/Character/>.
@prefix Gender: <https://gameExample.org/ns/Gender/>.
@prefix Species: <https://gameExample.org/ns/Species/>.
@prefix Vocation: <https://gameExample.org/ns/Vocation/>.
# Rest of the prefixes not included
PC:_AleriaDelamare a Class:_PC;
Entity:hasLabel "Aleria Delamare"^^xs:string;
Character:hasGender Gender:_Female;
Character:hasSpecies Species:_Human;
Character:hasVocation [
Vocation:hasType Vocation:_Mage;
Vocation:hasLevel 5;
];
.
PC:_KiraMcTavish a Class:_PC;
Entity:hasLabel "Kira McTavish"^^xs:string;
Character:hasGender Gender:_Female;
Character:hasSpecies Species:_Human;
Character:hasVocation [
Vocation:hasType Vocation:_Warrior;
Vocation:hasLevel 6;
];
. .Then the SPARQL to generate rows of output might look like this:
SELECT ?name ?species ?gender ?vocationType ?vocationLevel ?species ?alignment
WHERE {
?s a Class:_PC.
?s Entity:hasLabel ?name.
?s Character:hasSpecies ?species.
?s Character:hasGender ?gender.
?s Character:hasVocation ?vocation.
?vocation Vocation:hasType ?vocationType.
?vocation Vocation:hasLevel ?vocationLevel.
}and the output from the query would be as follows:
{
"head": {
"vars": [ "name" , "species" , "gender" , "vocationType" , "vocationLevel" , "alignment" ]
} ,
"results": {
"bindings": [
{
"name": { "type": "literal" , "value": "Aleria Delamare" } ,
"species": { "type": "uri" , "value": "https://kaleidoscope.org/ns/Species/_Human" } ,
"gender": { "type": "uri" , "value": "https://kaleidoscope.org/ns/Gender/_Female" } ,
"vocationType": { "type": "uri" , "value": "https://kaleidoscope.org/ns/Vocation/_Mage" } ,
"vocationLevel": { "type": "literal" , "datatype": "http://www.w3.org/2001/XMLSchema#integer" , "value": "5" }
} ,
{
"name": { "type": "literal" , "value": "Kira McTavish" } ,
"species": { "type": "uri" , "value": "https://kaleidoscope.org/ns/Species/_Human" } ,
"gender": { "type": "uri" , "value": "https://kaleidoscope.org/ns/Gender/_Female" } ,
"vocationType": { "type": "uri" , "value": "https://kaleidoscope.org/ns/Vocation/_Warrior" } ,
"vocationLevel": { "type": "literal" , "datatype": "http://www.w3.org/2001/XMLSchema#integer" , "value": "6" }
}
]
}
}While there is a fair amount of useful metadata here, reconstructing it into something simpler would be helpful. This is where the Jena JSON keyword command comes in. This keyword allows you to create an array of name-value pair objects.
JSON {
"name":?name,
"species":?species,
"gender":?gender,
"vocationType":?vocationType,
"vocationLevel":?vocationLevel
}
WHERE {
?s a Class:_PC.
?s Entity:hasLabel ?name.
?s Character:hasSpecies ?species.
?s Character:hasGender ?gender.
?s Character:hasVocation ?vocation.
?vocation Vocation:hasType ?vocationType.
?vocation Vocation:hasLevel ?vocationLevel.
}The output of this should look much more amenable to JSON users:
[
{
"name" : "Aleria Delamare" ,
"species" : "https://kaleidoscope.org/ns/Species/_Human" ,
"gender" : "https://kaleidoscope.org/ns/Gender/_Female" ,
"vocationType" : "https://kaleidoscope.org/ns/Vocation/_Mage" ,
"vocationLevel" : 5
} ,
{
"name" : "Kira McTavish" ,
"species" : "https://kaleidoscope.org/ns/Species/_Human" ,
"gender" : "https://kaleidoscope.org/ns/Gender/_Female" ,
"vocationType" : "https://kaleidoscope.org/ns/Vocation/_Warrior" ,
"vocationLevel" : 6
}
]This shortcuts the need to set up AS mappings to names, and makes the output much easier to query. There are some limitations – the JSON object is a simple map (name/value set), and can’t necessarily encode arrays or other maps, and the JSON keys reflect the name of the variable, rather than a different label. Finally, the JSON capability is not standardized (it is a good candidate for a SPARQL 2.0 capability, however).
Lists and Magic Property Predicates
One of the bigger problems that many people have when working with RDF and SPARQL is taming ordered lists. Creating unordered lists is trivial – you simply use the ORDER BY keyword in SPARQL to determine where a list of items is given alphabetically, numerically, by date, by codepoint, or by some more complex sorting arrangement. However, suppose that you needed something like a Javascript array, where the items in that array are listed in a very specific (non-algorithmic) manner.
Turtle makes use of the RDFList structure to build such lists, hiding it by using a bit of syntactic sugar. For instance, in pure RDF, a list might be expressed as:
:subject :hasList _:b1.
_:b1 rdf:first :item1.
_:b1 rdf:rest _:b2.
_:b2 rdf:first :item2.
_:b2 rdf:rest _:b3.
_:b3 rdf:first :item3.
_:b3 rdf:rest rdf:nil.
This is intuitively obvious, right? Well, no, not especially. This is basically what a linked list looks like semantically, and is one reason why in general linked lists often did not figure heavily in earlier RDF. With Turtle (which debuted in the early 2010s), some important syntactic magic was applied. Rather than building out the linked list directly, the Use of parentheses as a notation for containing a linked list began to take off. The above set of assertions instead were indicated in Turtle (and later TRIG) as:
:subject :hasList (:item1 :item2 :item3).
While this simplified the process of writing such lists in Turtle, it didn’t necessarily make it that much easier to get that ordered list in SPARQL. Jena laid out a strategy that other knowledge graph companies have followed, albeit with different functions. Jena’s solution was to create a set of magical properties for lists (among other functions) that could be added in via the list namespace (PREFIX list: <http://jena.apache.org/ARQ/list#>), specifically with the functions list:member, list:index and list:length. For instance, suppose that the following triples were defined:
PC:_AleriaDelamare a Class:_PC;
Entity:hasLabel "Aleria Delamare"^^xs:string;
Character:hasGender Gender:_Female;
Character:hasSpecies Species:_Human;
Character:hasVocation [
Vocation:hasType Vocation:_Mage;
Vocation:hasLevel 5;
];
Character:hasSocialClass SocialClass:_Gentry;
Character:hasAlignment Alignment:_NeutralGood;
Character:hasOccupation Occupation:_Detective;
Character:hasSpellList (Spell:_ReadMagic Spell:_DetectMagic Spell:_Ward Spell:_Wind Spell:_DispelMagic Spell:_Reveal);
.
PC:_KiraMcTavish a Class:_PC;
Entity:hasLabel "Kira McTavish"^^xs:string;
Character:hasGender Gender:_Female;
Character:hasSpecies Species:_Human;
Character:hasVocation [
Vocation:hasType Vocation:_Cleric;
Vocation:hasLevel 6;
];
Character:hasSocialClass SocialClass:_Clergy;
Character:hasAlignment Alignment:_ChaoticGood;
Character:hasOccupation Occupation:_Priest;
Character:hasSpellList ( Spell:_Light Spell:_ReadMagic Spell:_MinorHealing Spell:_DispelUndead Spell:_Purify Spell:_DispelMagic Spell:_MajorHealing);
.The property Character:hasSpellList defines a list of spells from least powerful to most powerful, using the parentheses notation to identify these as being a specifically ordered list. Note that this list is space separated, not comma separated. It would be useful to determine what the index (position) of each member item in the list is, as well as being able to retrieve the items in order they are entered, rather than either randomly or based upon some other criterion. The predicates in the list: show how to retrieve the items in order, the order that they’re in, and the number of items in the list:
prefix Character: <https://gameExample.org/ns/Character/>
prefix Spell: <https://gameExample.org/ns/Spell/>
prefix Property: <https://gameExample.org/ns/Property/>
PREFIX list: <http://jena.apache.org/ARQ/list#>
select distinct ?s ?spell ?index ?length where {
?s ?p ?o.
?s Character:hasSpellList ?spellList.
?spellList list:member ?spell.
?spellList list:index (?index ?spell).
?spellList list:length ?length.
}
In this particular case, the list:member takes the list in question to retrieve the associated member, the index and the length of the list as parameters in another list. Again, the parentheses indicate a list of variables, some of which may have already been bound to a value. This is somewhat different from passing a list of parameters in other languages – though the syntax looks close enough that the notation should be self-evident.
The output of this, then is the following table:
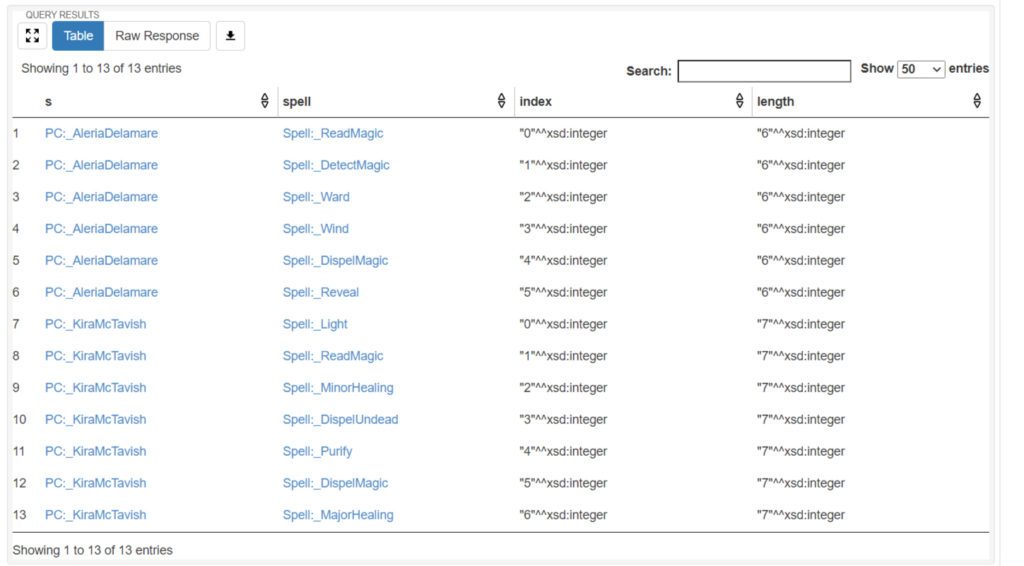
This ability to work with ordered lists should be something that’s an intrinsic part of SPARQL, as such lists figure prominently in everything from publishing to APIs to analytics. That the list capability is supported by Jena only reinforces this.
Quick IRI Tricks
There are a few additional tricks that you can use to simplify IRI construction and deconstruction. Jena, like a number of other SPARQL engines, lets you work with prefixes and have them resolve directly to their corresponding namespace. For instance, suppose that you had a string (such as a name), and wanted to create from that string a meaningful IRI for the person (or PC, for player character, given the above examples). Within Jena’s SPARQL, you can do it as follows:
PREFIX fn: <http://www.w3.org/2005/xpath-functions#>
SELECT ?name ?localName ?uri WHERE {
LET (?name := "Jane Doe")
LET (?localName := fn:replace(?name,' ',''))
BIND (iri(fn:concat( PC: , '_' ,?localName)) as ?uri)
}The LET syntax is a holdover from the Sparql algebraic expressions, and can be considered an alternative form of BIND expressions. Don’t use it if portability between systems is an issue.
In the above expression, the use of PC: in the bind statement is a way of specifying the naked namespace. In a string context, this expression will map to the string https://gameExample.org/ns/PC/. The underscore is a convention to make it evident that the URI is a resource rather than a property, then the local name is the specific name of the object. This generates a simple table:
| name | localName | uri |
|---|---|---|
| Jane Doe | JaneDoe | https://gameExample.org/ns/PC/_JaneDoe |
There are times as well where you will find you need to break apart a resource URI into both a namespace and a local name. With Jena, you can use the apf:splitIRI property to do just that.
PREFIX apf: <http://jena.apache.org/ARQ/property#>
select ?uri ?namespace ?localname WHERE {
?uri apf:splitIRI (?namespace ?localname)
}| uri | namespace | localname |
|---|---|---|
| https://gameExample.org/ns/PC/_JaneDoe | https://gameExample.org/ns/PC/ | _janeDoe |
Again notice the distinction between a “magic” property and a function. A function takes a sequence of comma-separated parameters and is a self-contained expression. A magic property works upon a subject and an RDF list containing the appropriate variable to which you want to assign values. Magic properties are slowly going out of vogue in most SPARQL engines, primarily because of their somewhat inverted structure, but they are still quite pervasive in this space.
Summary
This covers a few of the more interesting features of Jena, though in an upcoming article I hope to address Jena’s RDF-Star support as well as SHACL components, while a final article will discuss the potential role of Jena for personal knowledge graphs and publisher systems.
{kind=link}