
Self Aware Streaming
1. Problem Statement
By processing data in motion, Real time/stream processing enables you to get insight into your business and make vital decisions.
Challenges in Stream Processing –
- Over-provisioning of resources for peak loads can be wasteful while under-provisioning can have a huge impact on the performance of the streaming applications.
- Recent advancements in technology have led to a deluge of data that require real-time analysis with strict latency constraints.
- How to determine the amount of resources like Memory, Disk or Network Bandwidth.
- Stale Data is of no use as compared to the fresh data in decision making.
We are trying to build the architecture for Stream processing applications that is self aware in a manner to auto scale the data pipeline resources.
2. Constraints in existing architectures
- The majority of research efforts on resource scaling in the cloud are investigated from the cloud provider’s perspective, they focus on web applications and do not consider multiple resource bottlenecks.
- Despite previous research in the field of auto-scaling of resources, current SPEs(Stream Processing Engines), whether open source such as Apache Storm, or commercial such as streaming components in IBM Infosphere and Microsoft Azure, lack the ability to automatically grow and shrink to meet the needs of streaming data applications.
- Moreover, previous research on auto-scaling focuses on techniques for scaling resources reactively, which can delay the scaling decision unacceptably for time sensitive stream applications.
- To the best of our knowledge, there has been no or limited research using machine learning techniques to proactively predict future bottlenecks based on the data flow characteristics of the data stream workload.
3. Our Solution – What? Why?
- We aim to Identify and predict the inflow of data points so that we can understand after X amount of time what will be the influx of data. If a system is able to identify, than it will be able to provision resources to it.
- That is why it is called Self Aware streaming.
- In this POC, we present our vision of a three-stage framework to auto-scale resources for SPEs(Stream Processing Engines) in the cloud.
- The workload model is created using data flow characteristics.
- The output of the workload model to predict future bottlenecks.
- Make the scaling decision for the resources.
4. Self Aware Streaming architecture
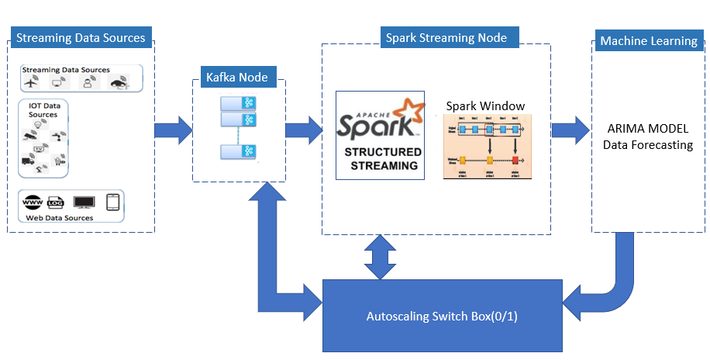
5. Machine Learning models to help here:
There are variety of Machine learning models availabe. Here we have used the ARIMA model.
6. Time Series Data
The autoscaling of resources is done on the basis of Time series data.
7. ARIMA model – The Rescuer
- An ARIMA model is a class of statistical models for analyzing and forecasting time series data.
- ARIMA is an acronym that stands for AutoRegressive Integrated Moving Average. It is a generalization of the simpler AutoRegressive Moving Average and adds the notion of integration.
The parameters of the ARIMA model are defined as follows:
p: The number of lag observations included in the model, also called the lag order.
d: The number of times that the raw observations are differenced, also called the degree of differencing.
q: The size of the moving average window, also called the order of moving average.
8. Train The Model
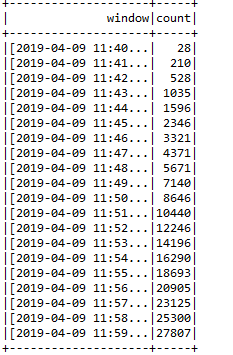
An ARIMA model is trained with some good amount of data.
Generate some data with two fields the time window and count of messages per minute.
9. Approach Followed
- Train the Machine Learning Model.
- Ingest the IoT Streaming data to some Kafka queue.
- Use the Spark Structured Stream to Read the stream.
- Apply the Window function to the incoming stream with some predefined window length and Sliding interval.
- Load the trained ARIMA model and feed it with incoming stream from previous window. ARIMA model will use its parameters to do the forecast for the next value.
- If the forecasted value is more than the Threshold value for 10-15 occurrences that it is Anomaly.
- Now it is the time to react and that’s the surprise !!!!!!
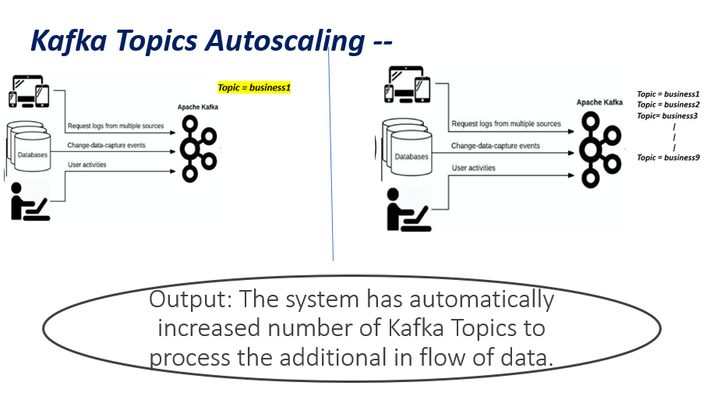
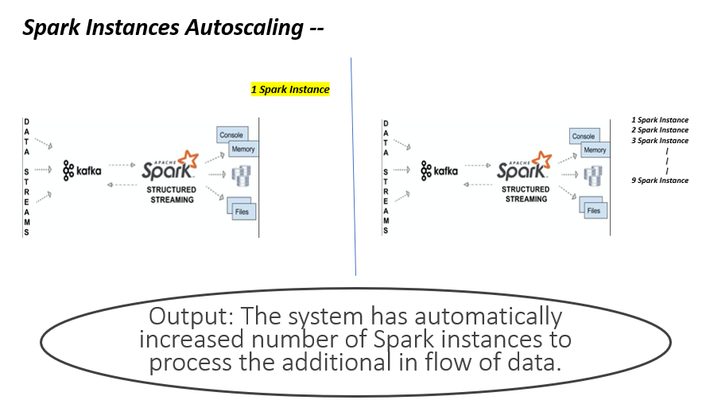
10. Autoscaling
11. Future Improvements
- Currently the system is capable of Automatically adding the resources in real time, in future it could be enhanced to automatically scaling down the resources in real time.
- Publish message on Web UI to inform user that Resource allocation is increased by adding more topics in Kafka Queue and increased the number of Spark job instances.
- Execute System level code to acquire new cloud machine and add it to the Kafka cluster as a new node.
- Execute Script to trigger the Autoscaling provided by cloud providers like AWS and making the reactive decision as predictive decision.
{kind=link}