
Stock trading has one of the most complex and complicated dynamics in the present day world. In today’s time, multiple algorithms and researches have been produced to understand the complexity of the stocks trading. There is an increasing effort to understand the system dynamics of stock trading to predict the emergent behavior of the stock prices.
In order to predict stock prices adequately, one needs to have access to historical data of the stock prices. Mostly, you will be focussed towards one stock and it’s a predicted value. In order to obtain the historical data of the stock prices, you can use data service providers or you can make use of simple web scrapers to perform this job. This task can be carried out by scraping websites which provide stock prices data. You can proceed with scraping Nasdaq news website or scraping Yahoo finance website for stock prices data!
In this article, we will focus on scraping Nasdaq news website to collect data of stock prices. We will be demonstrating the web scrapping implementation step by step so that you can understand it easily. Before scraping Nasdaq news website, let us first understand more about Nasdaq news in the next section.
What is Nasdaq News?
The Nasdaq Stock Market is an exchange for American stock. It is the world’s second-largest market capitalization stock exchange. Nasdaq Inc. owns the exchange platform, which also owns the Nasdaq Nordic and Nasdaq Baltic stock market network, as well as several exchanges of U.S. stocks and options.
Nasdaq is a global platform for trading securities. Nasdaq, by the National Association of Securities Dealers (NASD), enables traders to trade securities on a computerized, speedy and transparent system. Nasdaq news comprises of the daily information regarding various stocks, commodities, and indices. Furthermore, it serves all the news regarding finance and stock markets useful for stock analysts, business and common people involved in trading.
Web scraping for stock price prediction
Stock price prediction is one of the hottest prediction tasks in the 21st century. Different investment organizations are in the race of developing their own algorithms for accurately predicting the stock prices. There are a lot of underlying algorithms that can help one for the same however complex this scenario may be.
The prime requirement for all these algorithms is the availability of the stock prices data. The stock data is generally available with different data vendors but there is a cost attached to it. If you are an independent researcher and want to have hands-on on stock price prediction, there is a way of obtaining this stock data. In this case, web scraping comes to your rescue. Using web scraping, you can obtain stock data from different stock media platforms such as Nasdaq news, yahoo finance, etc. With stock data available at hand, you can perform the following tasks while the stock market
1. Stock price prediction
Online trading involves stocks trading via an online platform. Online trading portals facilitate the trading of different financial instruments such as stocks, mutual funds, and commodities. In online stock trading, owners of one stock meet different buyers virtually and sell the stocks to buyers. The selling part only happens when a buyer and a seller has negotiated the price of exchange. Furthermore, these prices are market dependent and are provided by scraping yahoo finance. Moreover, stock trading organizations can leverage yahoo finance data to keep a record of changing stock prices and market trend. This analysis will help financial and investment companies to predict the market and buy/sell stocks for maximum profits.
2. Stock market sentiment analysis
Organizations can perform sentiment analysis over the blogs, news, tweets and social media posts in business and financial domains to analyze the market trend. Furthermore, scraping Yahoo finance will help them in collecting data for natural language processing algorithms to identify the sentiment of the market. Through this, one can track the emotion towards a particular product, stock, commodity or currency and make the right investment decision.
3. Equity research
Equity Research refers to analyzing a company’s financial data, perform analysis over it and identify recommendations for buying and selling of stocks. The main aim of equity research is to provide investors with financial analysis reports and recommendations on buying, holding, or selling a particular investment. Also, banks and financial investment organizations often use equity research for their investments and sales & trading clients, by providing timely, high-quality information and analysis.
4. Regulatory compliance
Business and financial investment jobs are high-risk jobs. A lot of investment decisions are directly dependent on the government scheme and policies regarding trade. Hence, it is essential to keep track of the government sites and other official forums to extract any policy changes related to trading. Mainly, risk analysts should crawl news outlets and government sites for real-time actions about the events and decisions which are directly correlated with their business.
Our Goal
Our goal, in this blog, is to learn the process of scraping NASDAQ news. We will be scraping data about most-active stocks and indices. We will be using python to implement our web scraper. Furthermore, we will use BeautifulSoup library for scraping the NASDAQ news. BeautifulSoup is a simple scraping library available in python.
In case, you are completely new to the process of web scraping, we will go step by step in this blog. Hence, in the end, you will able to comprehend the entire scraping pipeline easily. Before directly jumping to the implementation of scraping NASDAQ news, let us have a look a the scraping pipeline we are going to follow.
Pipeline for scraping NASDAQ news
To implement the scraping of NASDAQ news for stock prices data, we need to follow few steps by step procedures and we will be done! Firstly, we will be setting up the target URLs and will download all the data available from the target URL. After that, our main task is to search through the downloaded data for our required information.
This is more like a string matching process where we are looking for specific patterns in the data and extracts them out using these patterns. After the extraction of the data, we will try to visualize this data for better understanding and save it with us.
Stage 1: Deciding the scraping parameters
One of the most important tasks in web scraping is analyzing the HTML structure of the target web page. Here, we are looking to find the patterns in the HTML structure of the data. These patterns are the essentials in extracting data from the web page. We will look for some recurring HTML structure or HTML tags and ids.
Let us try to find some patterns in our case. Below is the HTML snippet of the target stock prices table which we are going to scrape.
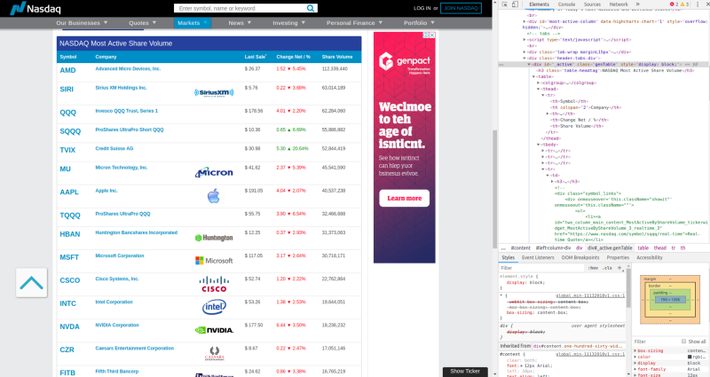
On the most-active stock page, you can use left-click and do inspect element on the page. After that, you can use hover functionality to find the HTML code for the target stocks table. Here, you can see in the image that the stocks table is mapped to a class named “genTable” in the code. This gives us the hook to look for the entire table in the HTML code while scraping it. Hence, here our approach will be that we will look for the specified table first. After finding the table, we will iterate over the table rows one by one and extract the stock data one by one.
Stage 2: Python implementation for scraping NASDAQ news
In this section, we will start with the implementation of the scraping of NASDAQ news for stock prices. We are using python to implement the web scraper here. Our very first is task is to import all the libraries first.
import requests
from bs4 import BeautifulSoup
import csv
import pandas as pd
After importing all the libraries, we need to set the target URL. Once we set the target URL, our code will parse through the web page and store all the HTML content in one variable. After that, we are searching through the HTML code for our required information using the inbuilt functions available with BeautifulSoup library. You can find the entire implementation below!
mostActiveStocksUrl = "https://www.nasdaq.com/markets/most-active.aspx"
r= requests.get(mostActiveStocksUrl)
data=r.text
soup=BeautifulSoup(data)
table=soup.find_all(‘div’, attrs={"class":"genTable"})
all_rows=table[1].find_all(‘tr’)
symbols=[]
names=[]
last_sales=[]
change_nets=[]
share_volumes=[]
for row in all_rows:
cols=row.find_all(‘td’)
if(len(cols)):
names.append(cols[1].text)
last_sales.append(cols[2].text)
change_nets.append(cols[3].text)
share_volumes.append(cols[4].text)
data=pd.DataFrame({"Names":names,"Last Sale": last_sales,"Change Net": change_nets,"Share Volume": share_volumes})
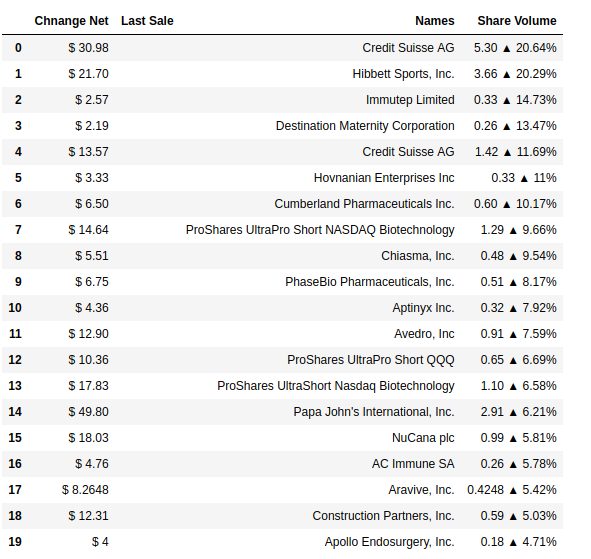
Stage 3: Visualising the results
In this stage, we will organise the collected data in a table and view the stored results. We are using pandas library available in python for constructing a simple data frame from the scraped information. Implementation is below!
data=pd.DataFrame({"Names":names,"Last Sale": last_sales,"Chnange Net": change_nets,"Share Volume": share_volumes})
Datahut as a reliable scraping partner
There are a lot of tools that can help you scrape data yourself. However, if you need professional assistance with minimal technical know-how, Datahut can help you. We have a well-structured and transparent process for extracting data from the web in real time and provide in the desired format. We have helped enterprises across various industrial verticals. From assistance to the recruitment industry python/ to retail solutions, Datahut has designed sophisticated solutions for most of these use-cases.
You should join the bandwagon of using data-scraping in your operations before it is too late. It will help you boost the performance of your organisation. Furthermore, it will help you derive insights that you might not know currently. This will enable informed decision-making in your business processes.
Summary
In this article, we had a look at how simple scraping Nasdaq news for stock market data can be using python. Furthermore, the data about stocks, commodities and currencies were also collected by scraping Nasdaq news website. Beautiful soup is a simple and powerful scraping library in python which made the task of scraping Nasdaq news website really simple.
Also, the data collected by scraping Nasdaq news website by the financial organisations to predict the stock prices or predict the market trend for generating optimised investment plans. Apart from financial organisations, many industries across different verticals have leveraged the benefits of web scraping.
{kind=link}