
Summary: Convolutional Neural Nets are getting all the press but it’s Recurrent Neural Nets that are the real workhorse of this generation of AI.
 We’ve paid a lot of attention lately to Convolutional Neural Nets (CNNs) as the cornerstone of 2nd gen NNs and spent some time on Spiking Neural Nets (SNNs) as the most likely path forward to 3rd gen, but we’d really be remiss if we didn’t stop to recognize Recurrent Neural Nets (RNNs). Why? Because RNNs are solid performers in the 2nd gen NN world and perform many tasks much better than CNNs. These include speech-to-text, language translation, and even automated captioning for images. By count, there are probably more applications for RNNs than for CNNs.
We’ve paid a lot of attention lately to Convolutional Neural Nets (CNNs) as the cornerstone of 2nd gen NNs and spent some time on Spiking Neural Nets (SNNs) as the most likely path forward to 3rd gen, but we’d really be remiss if we didn’t stop to recognize Recurrent Neural Nets (RNNs). Why? Because RNNs are solid performers in the 2nd gen NN world and perform many tasks much better than CNNs. These include speech-to-text, language translation, and even automated captioning for images. By count, there are probably more applications for RNNs than for CNNs.
Recurrent Neural Net Basics
On one scale RNNs have much more in common with the larger family of NNs than do CNNs which have very unique architecture. But RNNs are unique in their own ways, the most important of which are:
Time
RNNs allow inputs of strings of data to be assessed together and those strings can be of widely varying lengths. Some examples:
- Blocks of text.
- Audio speech signals.
- Strings of stock prices.
- Streams of sensor data.
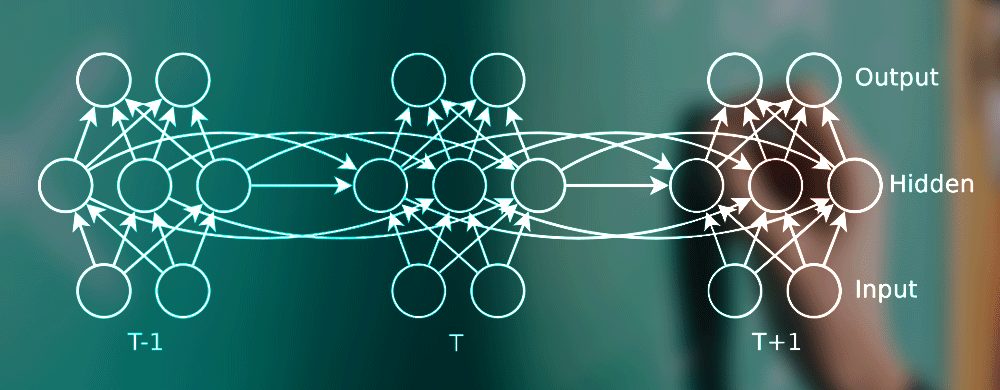
Unlike many other types of NNs which are feedforward networks, RNNs have bi-directional data flow. Although each unit of data will enter the RNN and be analyzed one unit at a time, in this model some of the data from later processing stages is fed back to early stages to influence the processing of subsequent data items. In other words, it introduces a sense of TIME.
This design is referred to as back propagation through time. Where other types on NNs assume that the inputs are independent of one another, RNNs specifically deal in sequences of data where each data item clearly does have a relationship to the ones before and after.
While strings of stock prices or sensor data may easily be seen as time series data, it’s also possible to see strings of text or speech as time series when you understand that these are being processed one character at time and in the sequence in which they naturally occur (over time). This is called ‘character level’ language modeling. So RNNs learn on any data which can be presented as sequence.
Memory
The feed backwards loop in RNNs is not just one data unit backwards. It can be as many units backwards as you specify. In other words, the impact of the current calculation can be felt in the processing of data items dozens or thousands of units later. This means that the RNN model is said to ‘remember’ and apply learning over a time scale that the data scientist controls.
The challenge of memory is that the longer the time we ask the RNN to remember (process together) the weaker is the influence of the current action on all subsequent data. There are clearly diminishing returns involved.
Several approaches have evolved to deal with this all of which can be said to create a kind of sliding window or gate over which the backward flow of information can extend. In tuning, this gives the author direct control over how much influence current learning should have over data received later and how rapidly the RNN should ‘forget’.
Outputs Can Be Sequences Also
While we are accustomed to the output of most NNs to be a single value (classifier, forecast, or unsupervised vector creation like a picture) RNNs can give both single answers and can also create sequences of outputs. For example, although language or text may be analyzed one character at a time, it is only valuable if the output is entire words, phrases, or even much longer blocks of text.
For fun, Andrej Karpathy, a PhD student at Stanford trained a 3-layer RNN with 512 hidden nodes on each layer with all the works of Shakespeare. The RNN can generate long blocks of text that are difficult to differentiate from the original bard, like this one (part of a much longer entry).
PANDARUS:
Alas, I think he shall be come approached and the day
When little srain would be attain’d into being never fed,
And who is but a chain and subjects of this death
I should not sleep.
A Challenge and a Solution
There is a technical challenge for many types of NNs that use common gradient descent types of fitness functions that is exponentially worse for RNNs. This is the so-called ‘vanishing gradient’ problem. The reason for this is that each time step in an RNN is equivalent to an entire layer in a feedforward NN. So training a RNN for 100 time steps is equivalent to training a feedforward NN with 100 layers. This leads to exponentially smaller gradients between layers and a decay of information through time.
Basically this results in early ‘layers’ in the RNN becoming insensitive and also giving RNNs their reputation for being difficult to train. A number of solutions based on gating, telling the RNN when to remember and when to forget can largely resolve the problem. The most common technique is called LSTM (long short term memory). RNN/LSTM models can also handle situations where there are long delays (as might occur with IoT sensors) or where there is a mix of high and low frequency data components.
What Are They Best For
The importance of RNNs and CNNs together is that they are two of three main legs of the AI stool. CNNs and RNNs are the eyes, ears, and mouth. SNNs may someday be the brain.
The magic of RNNs however is their ability to process sequences of data either as inputs and/or as outputs. This diagram illustrates the value of not being constrained to a single vector for input and output.

Source: Andrej Karpathy blog
The one-to-one diagram is the architecture for feedforward NNs including CNNs that limits us to a single input and output vector. Good, for example, for image classification.
But RNNs are extremely flexible in both input and outputs.
- One-to-many (a sequence output) could be used to create a sentence of words that might caption an image used as input.
- Many-to-one takes in a sequence as input, for example a block of text from social media, and characterizes with a single output as either negative or positive.
- Many-to-many takes in a sequence and outputs a sequence. This is the heart of language translation, for example Spanish to English.
- Synchronized many-to-many could be used in video classification to label each frame from a video.
Here’s a brief chart that reflects general agreement of problem type versus type of neural net most appropriate to the task.
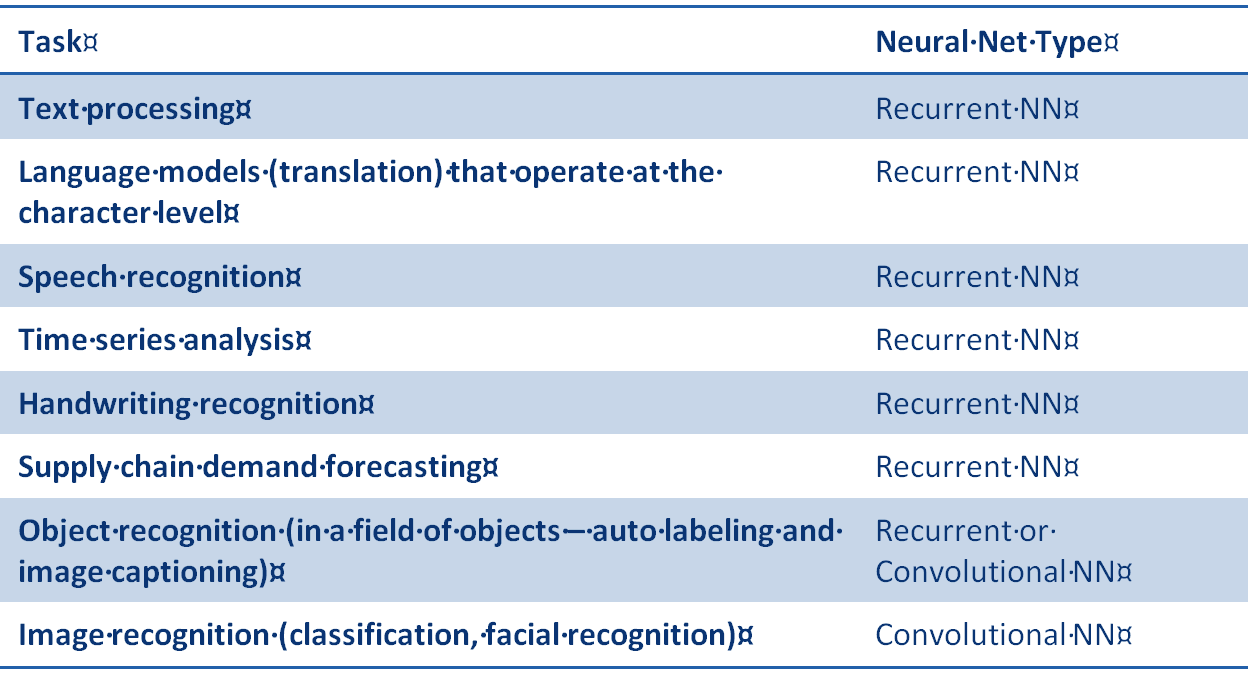
As you can see, there are more applications for RNNs and they lie mostly in speech, text, translation, and time series problems.
While ‘deep learning’ takes its name from the large number of layers in CNNs, it’s RNNs that are the real work horse of this generation of neural nets.
About the author: Bill Vorhies is Editorial Director for Data Science Central and has practiced as a data scientist and commercial predictive modeler since 2001. He can be reached at:
{kind=link}