
DVC is an open source tool that could help with achieving code simplicity, readability and faster model development.The idea is to track files/data dependencies during model development in order to facilitate reproducibility and track data files versioning. However, DVC is a language agnostic tool and can be used with any programming language. Here we will describe how we can use DVC in R projects.
R coding — keep it simple and readable
Each development is always a combination of following steps presented below:
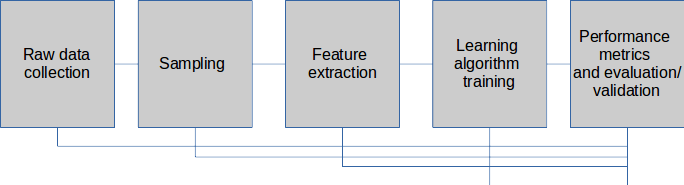
Because of the specificity of the process — iterative development, it is very important to improve some coding and organizational skills. For example, instead of having one big R file with code it is better to split code in several logical files — each responsible for one small piece of work. It is smart to track history development with git tool. Writing “reusable code” is nice skill to have. Put comments in a code can make our life easier.
Beside git, next step in further improvements is to try out and work with DVC. Every time when a change/commit in some of the codes and data sets is made, DVC will reproduce new results with just one bash command on a linux (or Win environment). It memorizes dependencies among files and codes so it can easily repeat all necessary steps/codes instead of us worrying about the order.
R example — data and code clarification
We’ll take an Python example from DVC tutorial (written by Dmitry Petrov) and rewrite that code in R. With an example we’ll show how can DVC help during development and what are its possibilities.
Firstly, let’s initialize git and dvc on mentioned example and run our codes for the first time. After that we will simulate some changes in the codes and see how DVC works on reproducibility.
R codes can be downloaded from Github
A brief explanation of the codes is presented below:
parsingxml.R — it takes xml that we downloaded from the web and creates appropriate csv file.
train_test_spliting.R — stratified sampling by target variable (here we are creating test and train data set)
featurization.R — text mining and tf-idf matrix creation. In this part we are creating predictive variables
train_model.R — with created variables we are building logistic regression (LASSO).
evaluate.R — with trained model we are predicting target on test data set. AUC is final output which is used as evaluation metric.
Firstly, codes from above we will download into the new folder (clone the repository):
mkdir R_DVC_GITHUB_CODE
cd R_DVC_GITHUB_CODE git clone
DVC installation and initialization
On the first site it seemed that DVC will not be compatible to work with R because of the fact that DVC is written in Python and as that needs/requires Python packages and pip package manager. Nevertheless, the tool can be used with any programming language, it is language agnostic and as such is excellent for working with R.
Dvc installation:
$ pip3 install dvc
$ dvc init
With code below 5 R scripts with dvc run are executed. Each script is started with some arguments — input and output file names and other parameters (seed, splitting ratio etc). It is important to use dvc run — with this command R script are entering pipeline (DAG graph).
$ dvc import data/
# Extract XML from the archive.
$ dvc run tar zxf data/Posts.xml.tgz -C data/
# Prepare data.
$ dvc run Rscript code/parsingxml.R data/Posts.xml data/Posts.csv
# Split training and testing dataset. Two output files.
# 0.33 is the test dataset splitting ratio. 20170426 is a seed for randomization.
$ dvc run Rscript code/train_test_spliting.R data/Posts.csv 0.33 20170426 data/train_post.csv data/test_post.csv
# Extract features from text data. Two TSV inputs and two pickle matrixes outputs.
$ dvc run Rscript code/featurization.R data/train_post.csv data/test_post.csv data/matrix_train.txt data/matrix_test.txt
# Train ML model out of the training dataset. 20170426 is another seed value.
$ dvc run Rscript code/train_model.R data/matrix_train.txt 20170426 data/glmnet.Rdata
# Evaluate the model by the testing dataset.
$ dvc run Rscript code/evaluate.R data/glmnet.Rdata data/matrix_test.txt data/evaluation.txt
# The result.
$ cat data/evaluation.txt
Dependency flow graph on R example
Dependency graph is shown on picture below:
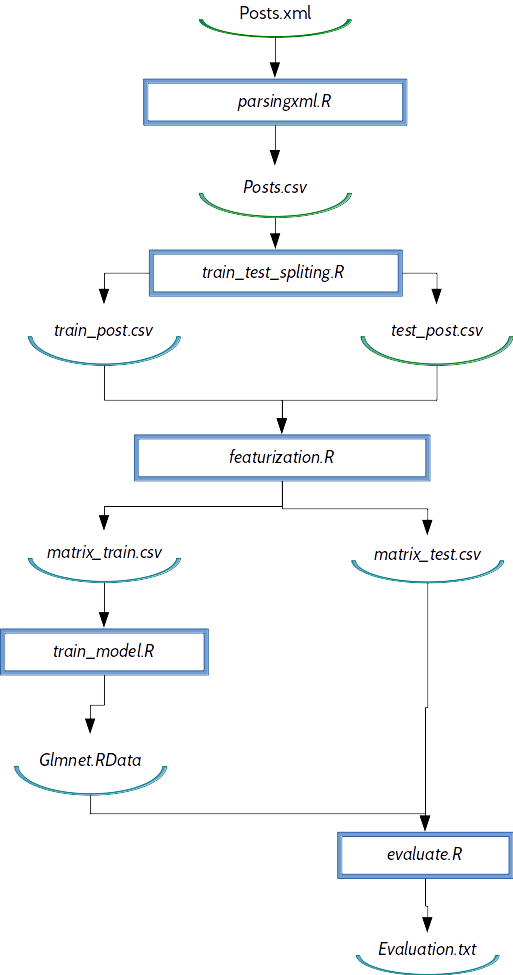
DVC memorizes this dependencies and helps us in each moment to reproduce results.
For example, lets say that we are changing our training model — using ridge penalty instead of lasso penalty (changing alpha parameter to 0). In that case will change/modify train_model.R job and if we want to repeat model development with this algorithm we don’t need to repeat all steps from above, only steps marked red on a picture below:
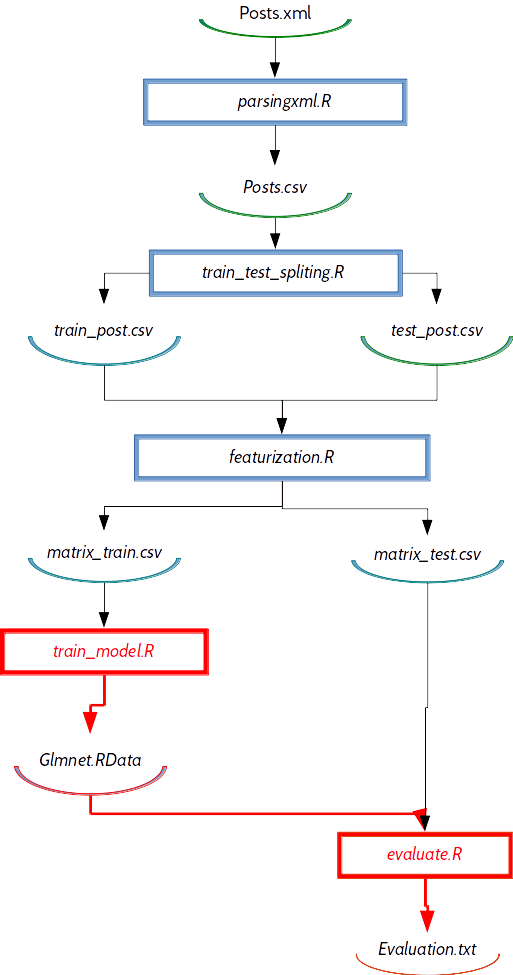
Based on DAG graph DVC knows that changed train_model.R file will only change following files: Glmnet.RData and Evaluation.txt. If we want to see our new results we need to execute only train_model.R and evaluate.R job. It is cool that we don’t have to think all the time what we need to repeat (which steps). “DVC repro” command will do that instead of us. Here is a code example :
$ vi train_model.R
$ git commit -am “Ridge penalty instead of lasso”
$ dvc repro data/evaluation.txt
Reproducing run command for data item data/glmnet.Rdata. Args: Rscript code/train_model.R data/matrix_train.txt 20170426 data/glmnet.Rdata
Reproducing run command for data item data/evaluation.txt. Args: Rscript code/evaluate.R data/glmnet.Rdata data/matrix_test.txt data/evaluation.txt
$ cat data/evaluation.txt
"AUC for the test file is : 0.947697381983095"
Command “Dvc repro“ always re executes steps which are affected with the latest developer changes. It knows what needs to be reproduced.
DVC can also work in an “multiuser environment” . Pipelines (dependency graphs) are visible to others colleagues if we are working in a team and using git as our version control tool. Data files can be shared if we set up a cloud and with dvc sync we specify which data can be shared and used for other users. In that case other users can see the shared data and reproduce results with those data and their code changes.
Summary
DVC tool improves and accelerates iterative development and helps to keep track of ML processes and file dependencies in the simple form. On the R example we saw how DVC memorizes dependency graph and based on that graph re executes only jobs that are related to the latest changes. It can also work in multiuser environment where dependency graphs, codes and data can be shared among multiple users. Because it is language agnostic, DVC allows us to work with multiple programming languages within a single data science project.
To read original blog, click here.
{kind=link}