

Why Question-Answering Engines?
The search only for documents is outdated. Users who have already adopted a question-answering (QA) approach with their personal devices, e.g., those powered by Alexa, Google Assistant, Siri, etc., are also appreciating the advantages of using a “search engine” with the same approach in a business context. Doing so allows them to not only search for documents, but also obtain precise answers to specific questions. QA systems respond to questions that someone can ask in natural language. This technology is already widely adopted and now rapidly gaining importance in the business environment, where the most obvious added value of a conversational AI platform is improving the customer experience.
Another key tangible benefit is the increased operational efficiency gained by reducing call center costs and increasing sales transactions. More recently we have seen a strong developing interest in in-house use cases, e.g., for IT service desk and HR functions. What if you didn’t have to painstakingly sift through your spreadsheets and documents to extract the relevant facts, but instead could just enter your questions into your trusty search field?
This is optimal from the user’s point of view, but transforming business data into knowledge is not trivial. It is a matter of linking and making all the relevant data available in such a way that all employeesnot just expertscan quickly find the answers they urgently need within whichever business processes they find themselves.
With the power of knowledge graphs at ones disposal, enterprise data can be efficiently prepared in such a way that it can be mapped to natural language questions. That might sound like magic, but it’s not. It is actually a well-established method to successfully roll out AI applications like QA systems in numerous industries.
Where do Current Question-Answering Methods Fall Short?
The use of semantic knowledge graphs supports a game-changing methodology to construct working QA engines, especially when domain-specific systems are to be built. Current QA technologies are based on intent detection, i.e., the incoming question must be mapped to some predefined intents. A common example of this is an FAQ scenario, where the incoming question is mapped to one of the frequently asked questions. This works well in some cases, but is not well suited to access large, structured datasets. That is because when accessing structured data, it is necessary to recognize domain-specific named entities and relations.
In these situations, intent detection technology requires a lot of training data and struggles to provide satisfactory results. We are exploiting a different technology based on semantic parsing, i.e., the question is broken down into its fundamental components, e.g., entities, relations, classes, etc., to infer a complete interpretation of the question. This interpretation is then used to retrieve the answer from the knowledge graph. What are the advantages?
- You do not need special configuration files for your QA engineeverything is encoded within the data itself, i.e., in the knowledge graph. By doing so you automatically increase the quality of your data, with benefits for your organization and for applications using this data.
- Contemporary QA engines frequently struggle with multilingual environments because they are typically optimized for a single language. With knowledge graphs in place, the expansion to additional languages can be established with relatively little effort, since concepts and things are processed in their core instead of simple terms and strings.
- This technology scales, so it will not make a difference if you have 100 entities or millions of entities in your knowledge graph.
- Lastly, you do not need to create a large training data corpus before setting up your engine. The data itself suffices and you can fine-tune the system as you go with little additional training data!
Building QA engines on knowledge graphs: an example from HR
What follows is a step-by-step outline of a methodology using a typical human resources (HR) use case as a running example.
Step 1: Gather your datasets
In this step, business users define the requirements and identify the data sources for the enterprises knowledge. After collecting structured, semi-structured and unstructured data in different formats, you will be able to produce a data catalog that will serve as the basis for your enterprise knowledge graph (EKG).
Step 2: Create a semantic model of your data
Here your subject matter experts and business analysts will define the semantic objects and design the semantic schemes of the EKG, which will result in a set of ontologies, taxonomies, and vocabularies that precisely describe your domain.
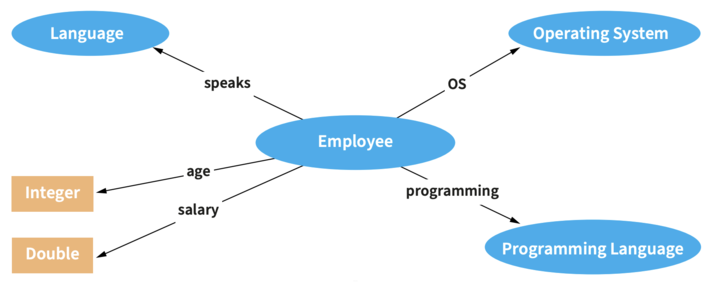
Step 3: Semantify your data
Create pipelines to automatically extract and semantify your data, i.e., annotate and extract knowledge from your data sources based on the semantic model that describes your domain. This is performed by data engineers who automate the ingestion and normalization of data from structured sources, as well as automate the analysis of unstructured content using NLP tools in order to populate the EKG using the semantic model provided. The resulting enriched EKG continuously improves as new data is added. The result of this step is the initial version of your EKG.
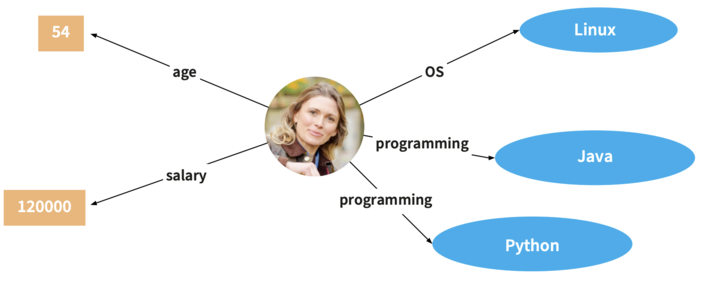
Step 4: Harmonize and interlink your data
After the previous step, your data is represented as things rather than strings. Each object gets a unique URI for links between entities and datasets to be established. This is facilitated by the use of ontologies and vocabularies, which, in addition to mapping rules, allow interlinking to external sources. During this stage, data engineers establish new relations in the EKG using logical inference, graph analysis or link discoveryaltogether enriching and further extending the EKG. The result of this process is an extension of your EKG that is eventually stored in a graph database which provides interfaces for accessing and querying the data.
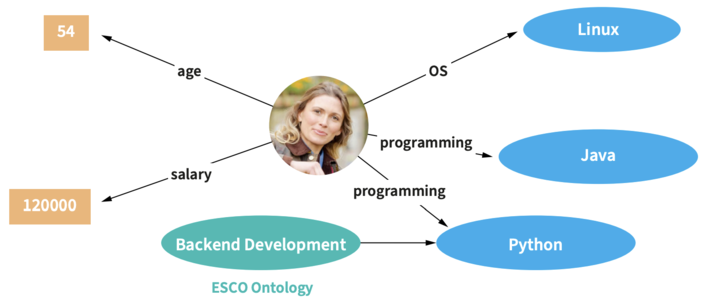 Step 5: Feed the QA system with data
Step 5: Feed the QA system with data
Allowing to ask questions on top of a EKG requires that (a) the data is indexed and (b) ML models are available to understand the questions. Both steps are fully automated in QAnswer. The EKG data is automatically indexed, and pretrained ML models are already provided so that you can start asking questions on top of your data right away.
Step 6: Provide feedback to the QA system
Improving the quality of the answers is done in the following two steps (6 and 7). The business user and a knowledge engineer are responsible for tuning the system together. The business user expresses common user requests and the knowledge engineer checks if the system returns the expected answers. Depending on the outcome, either the EKG is adapted (following Step 2-4) or the system is retrained to learn the corresponding type(s) of questions.
The user can provide feedback to the provided answer either by stating whether it is correct or not or by selecting the right query from a list of suggested SPARQL queries:
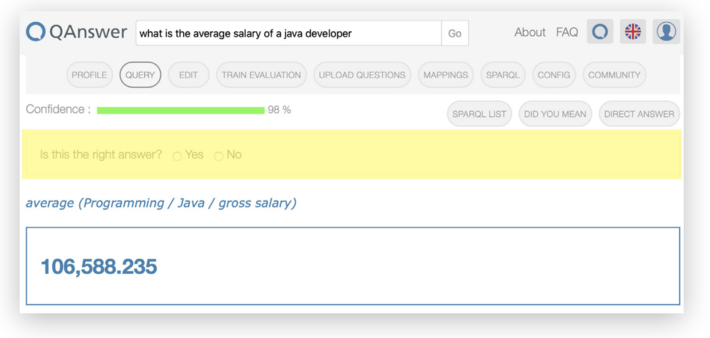
Step 7: Train the QA system
New ML models are generated automatically based on the training data provided in step 6. The system adapts to the type of data that has been put into the EKG and the type of questions that are important for your business. The provided feedback improves the ML model in order to increase the accuracy of the QA system and the confidence of the provided answers:
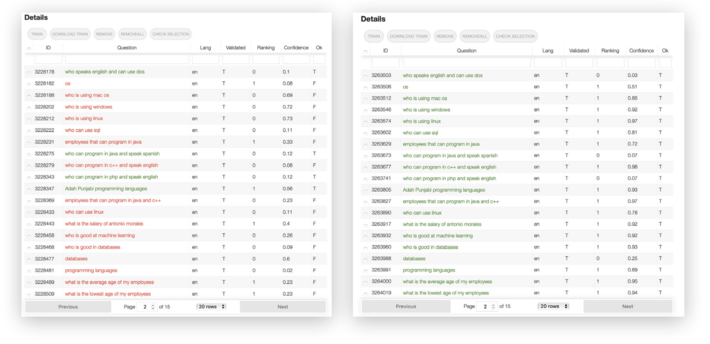
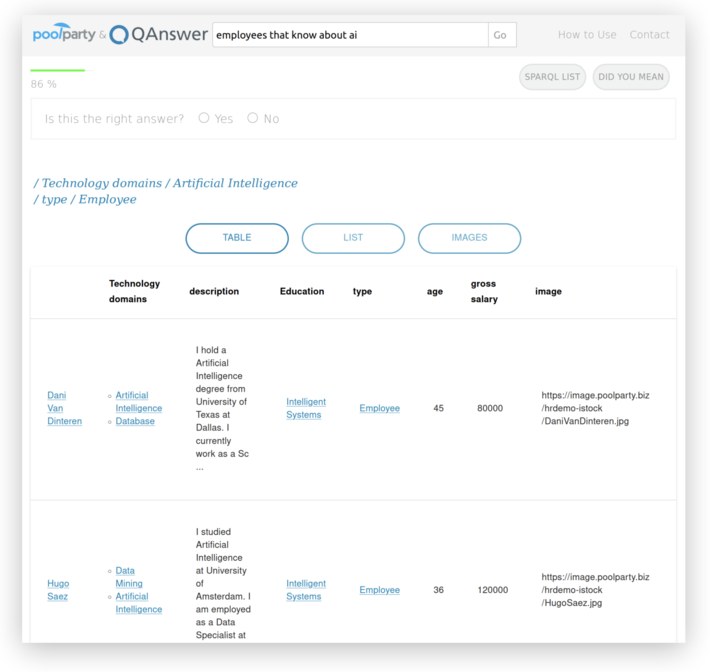
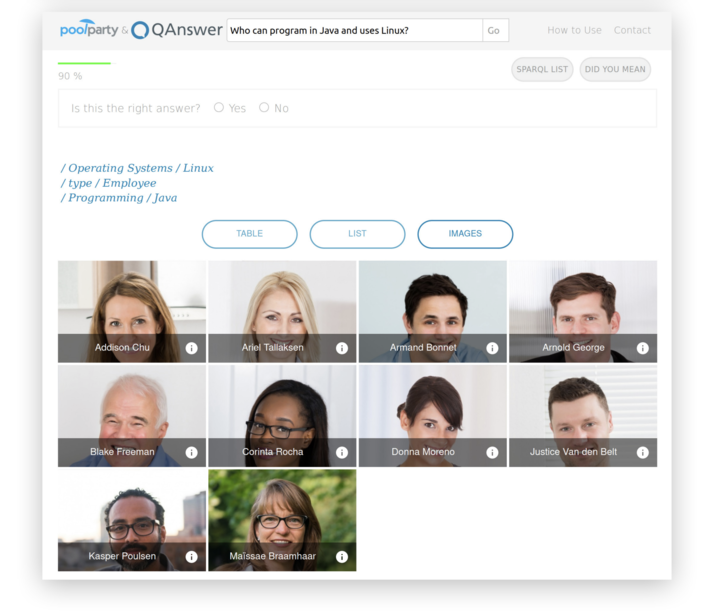
Step 8: Gain immediate insight into your knowledge
With the HR dataset now at your fingertips, you can ask questions like the following: Who are my employees? What languages do my staff speak? Who knows Javascript? Who has experience as Project Leader? Who can program in Java and knows MySQL? Who speaks English and Chinese? Who knows both Java and SPARQL? What is the salary range of my employees? How many people can code in Java and Javascript? What is the average salary of a C++ programmer? Who is the top paid employee?
Looking to the future
In order to have a conversation with your Excel files and the rest of the disparate data that has accumulated over the years, you will need to begin by breaking up the data silos in your organization. While the EKG will help you dismantle the data silos, the Semantic Data Fabric solution allows you to prepare the organizations data for question answering. This approach combines the advantages of Data Warehouses and Data Lakes and complements them with new components and methodologies based on Semantic Graph Technologies.
A lot of doors will open for your company by combining EKGs and QA technologies, and several domain-specific applications that allow organizations to quickly and intuitively access internal information can also be built on top of our solution.
One of the challenges we address is the difficulty of accessing internal information fast, intuitively and with confidence. People can find and gather useful information as they normally would when asking a humanin natural language. The capabilities of the technology we have presented in this article go well beyond what can be achieved with todays mainstream voice assistants. This new direction offers organizations a significant opportunity to simplify human-machine interaction and profit from the improved access to the organizations’ knowledge while also offering new, innovative and useful services to their customers.
The future of question-answering systems is in leveraging knowledge graphs to make them smarter.
{kind=link}