
Kaggle is an excellent place for learning. And I learned a lot of things from the recently concluded competition on Quora Insincere questions classification in which I got a rank of 182/4037. In this post, I will try to provide a summary of the things I tried. I will also try to summarize the ideas which I missed but were a part of other winning solutions.
As a side note: if you want to know more about NLP, I would like to recommend this awesome course on Natural Language Processing in the Advanced machine learning specialization. You can start for free with the 7-day Free Trial. This course covers a wide range of tasks in Natural Language Processing from basic to advanced: sentiment analysis, summarization, dialogue state tracking, to name a few. You can start for free with the 7-day Free Trial.
So first a little bit of summary about the competition for the uninitiated. In this competition, we had to develop models that identify and flag insincere questions. The challenge was not only a test for performance but also a test of efficient code writing skills. As it was a kernel competition with limited outside data options, competitors were limited to use only the word embeddings provided by the competition organizers. That means we were not allowed to use State of the art models like BERT. We were also limited in the sense that all our models should run in a time of 2 hours. So say bye bye to stacking and monster ensembles though some solutions were able to do this by making their code ultra-efficient. More on this later.
Some Kaggle Learnings:
There were a couple of learnings about kaggle as a whole that I would like to share before jumping into my final solution:
1. Always trust your CV
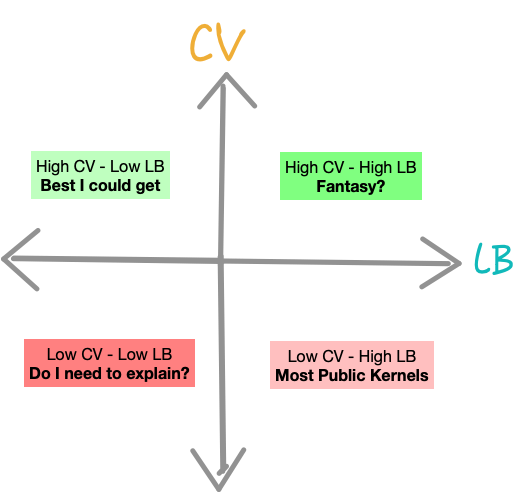
One of the things that genuinely baffled a lot of people in this competition was that a good CV score did not necessarily translate well to a good LB score. The main reason for this was small test dataset(only 65k rows) in the first stage(around 15% of total test data).
A common theme on discussion forums was focussing on which submissions we should select as the final submission:
- The one having the best local CV? or
- The one having the best LB?
And while it seems simple to say to trust your CV, common sense goes for a toss when you see that your LB score is going down or remaining constant whenever your Local CV score increases.
Luckily I didn’t end up making the mistake of not trusting my CV score. Owing to a lot of excellent posts on Kaggle discussion board, I selected a kernel with Public LB score of 0.697 and a Local CV of 0.701, which was around >1200 rank on Public LB as of the final submission. It achieved a score of 0.702 and ranked 182 on the private LB.
While this seems like a straightforward choice post-facto, it was a hard decision to make at a time when you have at your disposal some public kernels having Public LB score >= 0.70
2. Use the code from public kernels but check for errors
This Pytorch kernel by Benjamin Minixhofer is awesome. It made the base of many of my submissions for this competition. But this kernel had a mistake. It didn’t implement spatial dropout in the right way. You can find the correct implementation of spatial dropout in my post here or on my kernel. Implementing spatial dropout in the right way gave a boost of around 0.004 to the local CV.
Nonetheless, I learned pytorch using this kernel, and I am grateful to him for the same.
3. Don’t trust everything that goes on the discussion forums

I will talk about two things here:
-
Seed tuning: While in the middle of the competition, everyone was trying to get the best possible rank on the public LB. It is just human nature. A lot of discussions was around good seeds and bad seeds for neural network initialization. While it seems okay in the first look, the conversation went a stage further where people started tuning seeds in the kernel as a hyper param. Some discussions even went on to say that it was a valid strategy. And that is where a large amount of overfitting to public LB started happening. The same submission would score 0.704 from 0.699 just by changing the seed. For a reference, that meant you could go from anywhere near 400-500 rank to top 50 only by changing seed in a public kernel. And that spelled disaster. Some people did that. They went up the public LB. Went crashing out at the private stage.
-
CV score disclosure on discussion forums: We always try to gauge our performance against other people. In a lot of discussions, people provided their CV scores and corresponding Public LB scores. The scores were all over the place and not comparable due to Different CV schemes, No of folds in CV, Metric reported, Overfitting or just plain Wrong implementation of Cross-Validation. But they ended up influencing a lot of starters and newcomers.
4. On that note, be active on Discussion forums and check public kernels regularly
You can learn a lot just by being part of discussion forums and following public kernels. This competition had a lot of excellent public kernels on embeddings by SRK, Models by Shujian, and Preprocessing by Theo Viel which gave everyone a headstart. As the competition progressed, the discussions also evolved. There were discussions on speeding up the code, working approaches, F1 threshold finders, and other exciting topics which kept me occupied with new ideas and improvements.
Even after the end, while reading up discussions on solutions overview, I learned a lot. And I would say it is very ** vital to check out the winning solutions.**
5. Share a lot
Sharing is everything on Kaggle. People have shared their codes as well as their ideas while competing as well as after the competition ended. It is only together that we can go forward. I like blogging, so I am sharing the knowledge via a series of blog posts on text classification. The first post talked about the different preprocessing techniques that work with Deep learning models and increasing embeddings coverage. In the second post, I talked through some basic conventional models like TFIDF, Count Vectorizer, Hashing, etc. that have been used in text classification and tried to access their performance to create a baseline. In the third post, I will delve deeper into Deep learning models and the various architectures we could use to solve the text Classification problem. To make this post platform generic I will try to write code in both Keras and Pytorch. We will try to use various other models which we were not able to use in this competition like ULMFit transfer learning approaches in the fourth post in the series.
It might take me a little time to write the whole series. Till then you can take a look at my other posts too: What Kagglers are using for Text Classification, which talks about various deep learning models in use in NLP and how to switch from Keras to Pytorch.
6. Beware of trolls 🙂
We were going along happily towards the end of the competition with two weeks left. Scores were increasing slowly. The top players were somewhat stagnant. And then came Pavel and team with a Public LB score of 0.782. The next group had an LB score of 0.713. Such a huge difference. I was so sure that there was some leakage in the data which nobody has caught yet except for Pavel. I spent nearly half a day to do EDA again.
In the end, it turned out that what they did was scraping — nicely played!
They also have some pretty awesome ideas around including additional data, which could have worked but did not in this competition.
My Final Solution:

My main focus was on meta-feature engineering and on increasing embedding coverage and quality. That means I did not play much with various Neural Net architectures. Here are the things that I included in my final submission:
- I noticed that Glove embeddings were doing good on the local CV but not on LB, while meta embeddings(mean of glove and paragram) were doing good on LB but not that good on the CV. I took a mixed approach so some of my models are trained with only glove embedding and some on meta embeddings.
- Included four more features in embedding. Thus my embedding was a 304-dimensional vector. The four new values corresponded to title case flag, uppercase flag, Textblob word polarity, textblob word subjectivity
- Found out NER tokens from the whole train and test data using spacy and kept the tokens and the entities in a dict. I used this dict to create extra features like counts of
GPE,PERSON,ORG,NORP,WORK_OF_ART.Added some value and were highly correlated with the target. - Other features that I used include
total_length,capitals,words_vs_uniqueas well as some engineered features likesum_feat(sum of expletives),question_start_with_why,question_start_with_how_or_what,question_start_with_do_or_are. Might not have added much value but still kept them. - My final solution consisted of a stacked ensemble for four models. I stacked the four models using Logistic regression(with positive weights and 0 intercept) and gave the weights as a list in the final kernel.
You can find the kernel for my final submission here.
Tips and Tricks used in other solutions:
1. Increasing Embeddings Coverage:
In the third place solution kernel, wowfattie uses stemming, lemmatization, capitalize, lower, uppercase, as well as embedding of the nearest word using a spell checker to get embeddings for all words in his vocab. Such a great idea. I liked this solution the best as it can do what I was trying to do and finished at a pretty good place. Also, the code is very clean.
from nltk.stem import PorterStemmerps = PorterStemmer()from nltk.stem.lancaster import LancasterStemmer lc = LancasterStemmer()
from nltk.stem import SnowballStemmer
sb = SnowballStemmer("english")
def load_glove(word_dict, lemma_dict):
EMBEDDING_FILE = '../input/embeddings/glove.840B.300d/glove.840B.300d.txt'
def get_coefs(word,*arr): return word, np.asarray(arr, dtype='float32')
embeddings_index = dict(get_coefs(*o.split(" ")) for o in open(EMBEDDING_FILE))
embed_size = 300
nb_words = len(word_dict)+1
embedding_matrix = np.zeros((nb_words, embed_size), dtype=np.float32)
unknown_vector = np.zeros((embed_size,), dtype=np.float32) - 1.
print(unknown_vector[:5])
for key in tqdm(word_dict):
word = key
embedding_vector = embeddings_index.get(word)
if embedding_vector is not None:
embedding_matrix[word_dict[key]] = embedding_vector
continue
word = key.lower()
embedding_vector = embeddings_index.get(word)
if embedding_vector is not None:
embedding_matrix[word_dict[key]] = embedding_vector
continue
word = key.upper()
embedding_vector = embeddings_index.get(word)
if embedding_vector is not None:
embedding_matrix[word_dict[key]] = embedding_vector
continue
word = key.capitalize()
embedding_vector = embeddings_index.get(word)
if embedding_vector is not None:
embedding_matrix[word_dict[key]] = embedding_vector
continue
word = ps.stem(key)
embedding_vector = embeddings_index.get(word)
if embedding_vector is not None:
embedding_matrix[word_dict[key]] = embedding_vector
continue
word = lc.stem(key)
embedding_vector = embeddings_index.get(word)
if embedding_vector is not None:
embedding_matrix[word_dict[key]] = embedding_vector
continue
word = sb.stem(key)
embedding_vector = embeddings_index.get(word)
if embedding_vector is not None:
embedding_matrix[word_dict[key]] = embedding_vector
continue
word = lemma_dict[key]
embedding_vector = embeddings_index.get(word)
if embedding_vector is not None:
embedding_matrix[word_dict[key]] = embedding_vector
continue
if len(key) > 1:
word = correction(key)
embedding_vector = embeddings_index.get(word)
if embedding_vector is not None:
embedding_matrix[word_dict[key]] = embedding_vector
continue
embedding_matrix[word_dict[key]] = unknown_vector
return embedding_matrix, nb_words 2. Checkpoint Ensembling:
Get a lot of models at no cost. Most of the winning solutions have some version of checkpoint ensembling. For the third place solution, the predictions are a weighted average of predictions after the 4th epoch and predictions after the 5th epoch. I got this idea but forgot to implement it in my ensemble based kernel submission.
3. Meta Embeddings:
A lot of winning solutions ended up using weighted meta embeddings where they provided a higher weight to the Glove embedding. Some solutions also used concatenated embeddings.
4. Model Architecture:
One surprising thing I saw people doing was to use a 1Dconv layer just after the Bidirectional layer. For example, This is the architecture used by the team that placed first in the competition.
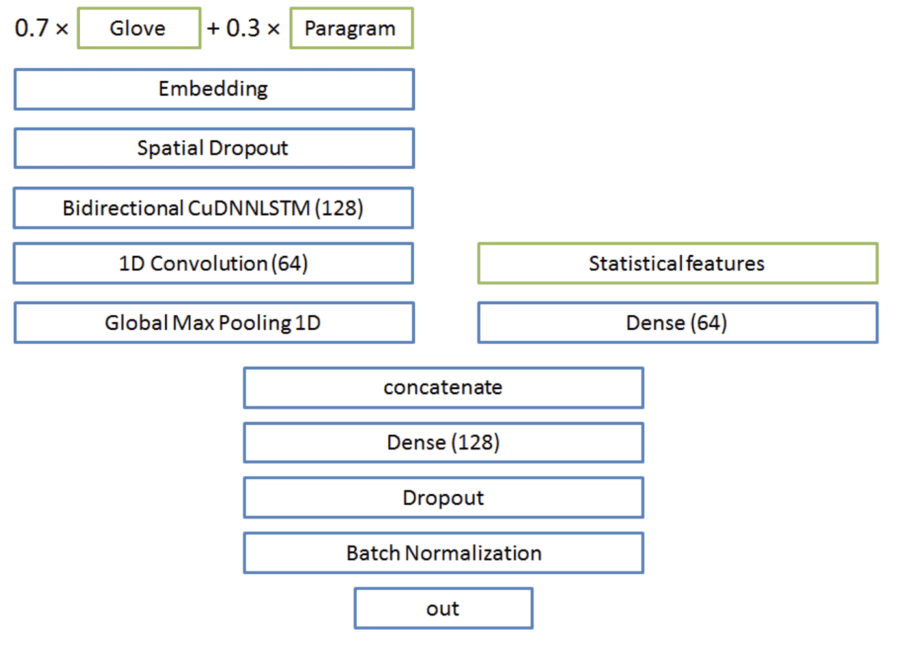
5. Bucketing/Variable Sequence Length and increased hidden units:
Another thing I noticed is the increased number of hidden units as compared to many public kernels. Most of the public kernels used a hidden unit size of 60 due to time constraints. I used 80 units at the cost of training one less network. A lot of high scoring kernels were able to use a higher number of hidden units owing to variable sequence length idea or bucketing. From the 1st place kernel discussion:
We do not pad sequences to the same length based on the whole data, but just on a batch level. That means we conduct padding and truncation on the data generator level for each batch separately, so that length of the sentences in a batch can vary in size. Additionally, we further improved this by not truncating based on the length of the longest sequence in the batch but based on the 95% percentile of lengths within the sequence. This improved runtime heavily and kept accuracy quite robust on single model level, and improved it by being able to average more models.
Also from 7th place discussion:
Bucketing is to make a minibatch from instances that have similar lengths to alleviate the cost of padding. This makes the training speed more than 3x faster, and thus I can run 9 epochs for each split of 5-fold.
Thus the use of this technique also allowed some competitors to fit many more epochs in less time and run more models at the same time. Pretty Neat!
6. For those winners who didn’t use bucketing, Maxlen = 72 was too large:
Most of us saw a distribution of question length and took the length that covered maximum questions fully as the maxlen parameter. I never tried to tune it, but it seems like it could have been tuned. One of the tricks was to use maxlen ranging from 35 to 60. This made the kernels run a lot faster.
7. Time taking models/complex architectures like Capsule were mostly not used:
Most of the winning solutions didn’t use capsule networks as they took a lot of time to train.
8. Backprop errors on embeddings weights in last few epochs:
Another thing I saw was in the 18th place kernel which uses a single model
if epoch >= 3: model.embedding.embeddings.weight.requires_grad = TrueConclusion:
It was a good and long 2-month competition, and I learned a lot about Text and NLP during this time. I want to emphasize here is that I ended up trying a lot of things that didn’t work before reaching my final solution. It was a little frustrating at times, but in the end, I was happy that I ended up with the best data science practices. Would also like to thank Kaggle master Kazanova who along with some of his friends released a “How to win a data science competition” Coursera course. I learned a lot from this course.
Let me know in the comments if you think something is missing/wrong or if I could add more tips/tricks for this competition.
{kind=link}