
Cross validation is a technique commonly used In Data Science. Most people think that it plays a small part in the data science pipeline, i.e. while training the model. However, it has a broader application in model selection and hyperparameter tuning.
Let us first explore the process of cross validation itself and then see how it applies to different parts of the data science pipeline
Cross-validation is a resampling procedure used to evaluate machine learning models on a limited data sample. In k–fold cross–validation, the original sample is randomly partitioned into k equal sized subsamples. Of the k subsamples, a single subsample is retained as the validation data for testing the model, and the remaining k − 1 subsamples are used as training data.
In the model training phase, Cross-validation is primarily used in applied machine learning to estimate the skill of a machine learning model on unseen data to overcome situations like overfitting. The choice of k is usually 5 or 10, but there is no formal rule. Cross validation is implemented through KFold() scikit-learn class. Taken to one extreme, for k = 1, we get a single train/test split is created to evaluate the model. There are also other forms of cross validation ex stratified cross validation

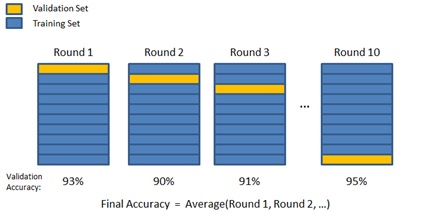
Image source: see here
Now, let’s recap the end to end steps for classification based on THIS classification code which we use in “learn machinelearning coding basics in a weekend“:
Classification code outline
1. Load the data
2. Exploratory data analysis
- Analyse the target variable,
- Check if the data is balanced,
- Check the co-relations
3. Split the data
4. Choose a Baseline algorithm
- Train and Test the Model
- Choose an evaluation metric
- Refine our dataset
- Feature engineering
5. Test Alternative Models — Ensemble models
6. Choose the best model and optimise its parameters
In this context, we outline below two more cases where we can use cross validation
- In choice of alternate models and
- In hyperparameter tuning
we explain these below
1. Choosing alternate models:
If we have two models, and we want to see which one is better, we can use cross validation to compare the two for a given dataset. For the code listed above, this is shown in the following section.
“””### Test Alternative Models
logistic = LogisticRegression()
cross_val_score(logistic, X, y, cv=5, scoring=”accuracy”).mean()
rnd_clf = RandomForestClassifier()
cross_val_score(rnd_clf, X, y, cv=5, scoring=”accuracy”).mean()
2. Hyperparameter tuning
Finally, cross validation is also used in hyperparameter tuning
As per cross validation parameter tuning grid search
“In machine learning, two tasks are commonly done at the same time in data pipelines: cross validation and (hyper)parameter tuning. Cross validation is the process of training learners using one set of data and testing it using a different set. Parameter tuning is the process to selecting the values for a model’s parameters that maximize the accuracy of the model.”
So, to conclude, cross validation is a technique used in multiple parts of the data science pipeline
{kind=link}