
Summary: What do you need to do to get an entry level job in data science?
This article is written for anyone who is considering becoming a data scientist. That includes young people just starting their bachelor’s degrees and folks in the first two or three years of their careers who want to make the switch.
It’s not for folks who know they are going to pursue one of the new Master’s in Data Science or Ph.D. candidates. It’s for folks looking for entry level jobs that are specifically on the data science career ladder.
Is There a Data Science Career Progression That Doesn’t Require an Advanced Degree?
Yes there is. Like many high skill professions that’s not to say that an advanced degree won’t make it easier but there are definitely ways to enter this market with only a bachelor’s degree.
If you’ve been practicing data science for more than five or ten years you also know that the majority of us over 35 don’t have specific data science degrees. We came to data science via a variety of related disciplines and gained our cred largely based on performance and experience. It’s only the cohort under 35 working in data science that’s likely to have a DS-specific degree, advanced or bachelor’s.
The flack this article is likely to draw is not over the level of degree required or the types of experience but the just-below-boiling controversy about who gets to call themselves a data scientist. The problem in our profession, and I’m not going to solve it here, is there is not an accepted nomenclature that differentiates the various skill levels of data scientists or who gets to wear that title at all.
Employers aren’t helping since actual data science jobs may be called engineer, analyst, developer, team lead or many other less exciting sounding titles. Other employers are giving data science titles to folks who are not really doing data science, but more descriptive analytics and straight EDW work.
So for simplicity’s sake I’m going to call our target audience folks who are seeking positions as Junior or Associate Data Scientists. Specifically that means doing work that involves detecting signals in the data that can be used to make predictions about future behavior. Not simple descriptive historical analysis of what’s happened in the past.
For Beginners What Does the Market Look Like and What Type of Work Will You Do?
 There are two key points to understand here. The first is that the data science market has divided into two distinctly different segments, Production and Development.
There are two key points to understand here. The first is that the data science market has divided into two distinctly different segments, Production and Development.
Production: This is by far the largest and most mature segment where predictive analytics has been used for longest and where it is best integrated to create truly data-driven businesses. Large B2C service businesses dominate this group, specifically insurance, financial services, cable and telecos, healthcare, plus retail, ecommerce, and some manufacturing. These companies are widely distributed geographically so you can work pretty much anywhere. The primary data science activities are predictive analytics and recommenders.
Development: This is the new and sexy world of data science that gets all the press coverage. In these enterprises the data science and the code are the product. Think Google, Facebook, eHarmony, Apple, and the thousands of start-ups that are either developing new analytic and big data platforms, or products with embedded analytics. This is also where you find the newest developments in data science including deep learning for image, text, and speech recognition, much of IoT (some crossover here to the production world), and all the flavors of AI.
The Development world is geographically concentrated in a few areas that we all know: the Bay area, Silicon Beach, New York, Boston, and maybe Austin. This is exciting and heady stuff where you will probably devote upwards of 60% to 70% of your substantial starting salary to rent.
As a new Associate Data Scientist you are much more likely to find your first career step in the Production world.
The Four Paths of Data Science
The second main point is that your career progression in DS will probably take you down one of four paths represented by different types of data scientists. These four types are ultimately differentiated by what they spend their time doing.
The best analysis that I’ve seen on this comes from the O’Reilly paper “Analyzing the Analyzers” by Harris, Murphy, and Vaisman, 2013. You can find the original at http://www.oreilly.com/data/free/analyzing-the-analyzers.csp and I strongly encourage you to read it.
There are 40 pages of good analysis here or for the Cliff Notes version see my previous article How to Become a Data Scientist.
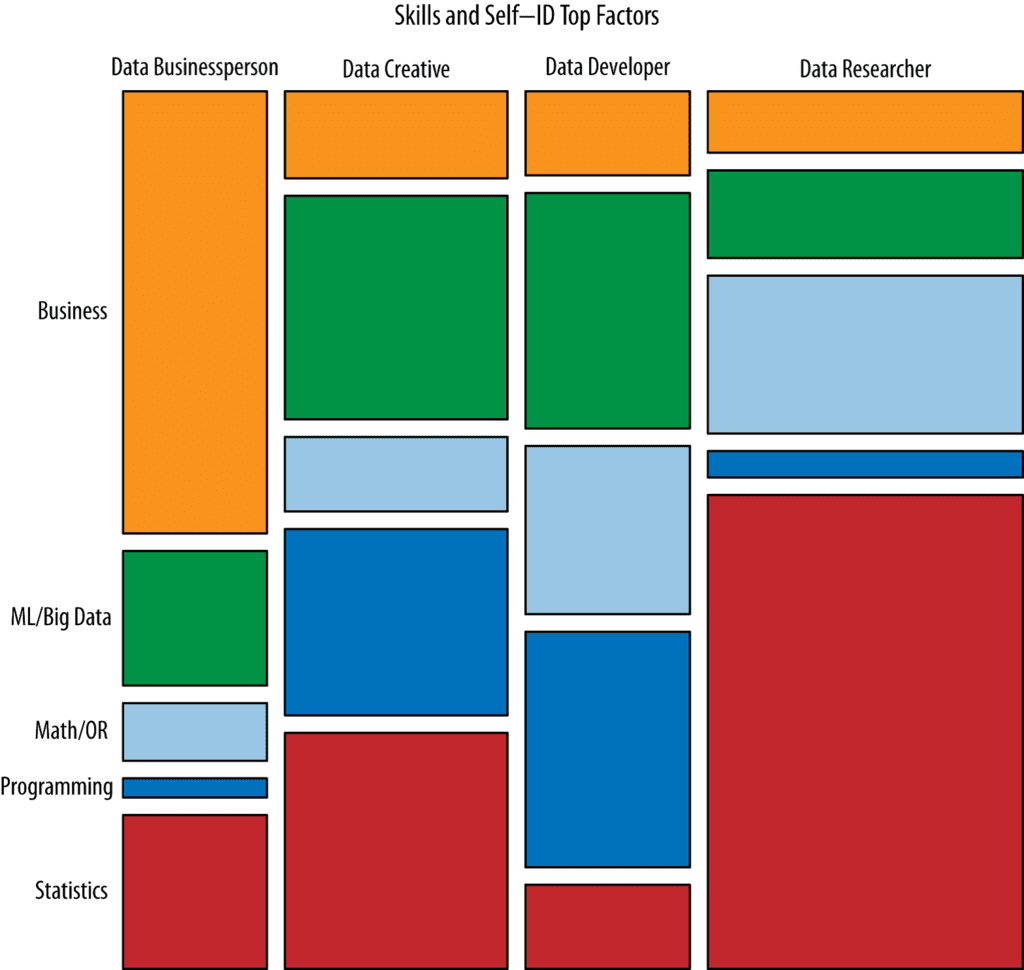
In short, they conclude there are four types of Data Scientists differentiated not so much by the breadth of knowledge, which is similar, but their depth in specific areas and how each type prefers to interact with data science problems.
- Data Businesspeople are those that are most focused on the organization and how data projects yield profit. At the entry level you’ll be performing the junior duties of blending and cleaning data and preparing basic predictive models.
- Data Developer. Focused on the technical problem of managing data — how to get it, store it, and learn from it. At the entry level you’ll be working with Hadoop as well as structured data. If you are more interested in the data science infrastructure side this may be for you and is a particularly good path for a current analyst and IT staff to move up into the data science career path.
- Data Creatives. Often tackle the entire soup-to-nuts analytics process on their own: from extracting and blending data, to performing advanced analyses and building models, to creating visualizations and interpretations. This is a more senior role innovating new types of predictive analytic use cases, data products, and services. This may also be you if you find yourself in a company with little or no experience with advanced analytics but you’re unlikely to get this job fresh out of college with no experience. Data Creatives are heavily present in the Development world.
- Data Researchers. Nearly 75% of Data Researchers have published in peer-reviewed journals and over half have a PhD. These are folks who are innovating data science at its most fundamental level.
According to Harris, Murphy, and Vaisman it’s not the skills that are different but the way we choose to emphasize them in our approach to Data Science problems. Here’s their chart.
This is an important decision since you need to do activities within data science that you like. This may lead you toward an advanced degree or simply to develop you skills through experience. It’s not something you have to decide from day one but one that you’ll want to consider early in your career.
The Skills You’ll Need to Enter the Data Science Market
If you were shopping for a two-year Master’s Degree in Data Science you’d have lots to pick from. If you search for Bachelor’s degrees in Data Science you’ll find a good selection but at many institutions the undergraduate degree is more likely to be titled ‘Computer Science’ leaving you to wonder if you’re actually getting the knowledge that you need.
If you have a choice, pick a college that specifically offers a Data Science degree. If you don’t have that choice you’ll have to analyze and select the blocks of learning that you’ll need.
Yes you need to be grounded in the broad aspects of computer science but in addition there are specific skills and knowledge you’ll need to master. The best description I’ve seen for this incremental learning is also an excellent guide for those of you who have recently finished your bachelors. It’s from an article by Amy Gershkoff, the Chief Data Officer at Zynga and describes their in-house program for growing their own data scientists.
Zynga’s in-house program is 12 to 18 months. To be considered there are a variety of performance requirements and academically the candidate needs a minimum of two previous semesters of coursework in statistics, economics, computer science, or similar. At Zynga, some of this is in an on-line academic environment and some is mentored by their in-house data scientists. This could easily be the course list for your undergraduate program. I have added some observations of my own.
Phase I: Foundational Statistical Theory
Participants learn the basics of probability theory and statistical analysis including sampling theory, hypothesis testing, and statistical distributions. For statistical analysis, topics include correlation, standard deviations, and basic regression analysis, among others. Usually one to two semesters of an online statistics course (such as Princeton University’s online course) covers this material.
Phase II: Foundational Programming Skills
To be an effective data scientist, knowledge of scripting languages is a requirement. Selecting which ones is a matter of discussion. My take is this:
SQL: Not really a hard data science language but reflects the fact that you’re likely to have to extract data yourself from relational databases. Also, SQL is now almost universally available as a query language on Hadoop (it’s really no longer accurate to call it NoSQL).
Python: The big discussion over the last five or so years has been around R versus Python. Python is my pick as a production language with a very generous data science library. More importantly, as SPARK has come on so quickly as the preferred tool on Hadoop, Python works easily here while R does not. In the most recent surveys you’ll see Python pulling away from R.
SAS: Yes SAS. SAS was practically the original DS scripting language before R and Python. Although it’s included here under programming skills you can learn to use the SAS packages via drag-and-drop UI just as easily. Depending on what survey you’re reading you may or may not see SAS on each list, but in the Production world SAS is extremely common and having this skill is a definite competitive advantage. IBM SPSS is an option but SAS has a huge lead in adoption. You will rarely encounter SAS in the Development world.
Phase III: Machine Learning
Participants learn both supervised and unsupervised learning techniques. Supervised learning techniques include decision trees, Random Forrest, logistic regression, Neural Networks, and SVMs. Unsupervised learning techniques include clustering, principal components analysis, and factor analysis.
Only a matter of a year or two ago you could not be an effective data scientist without knowing the inner workings of these algorithms including how to manipulate their tuning parameters to optimize results. The late breaking news however is the new availability of completely automated predictive analytic platforms where selection and operation of the ML algorithms is handled by AI.
The likelihood that your new employer will have any of these new platforms on hand is still fairly slim but growing by the day. Perhaps you will be the one to suggest they utilize them. They can really speed up the modeling process. Until then, you need to know what’s going on under the hood of all the major ML algorithms.
Phase IV: Big Data Toolbox
It is important for data scientists to not only learn the necessary algorithms, but also to learn how those algorithms need to be adapted for large datasets. For this reason, basic knowledge of tools such as Hadoop, Spark, and an analytics platform for large data sets constitutes a dedicated module.
It’s here that you’ll learn how those models you built in the last section are put into operation to assist business decisions. Until they’re operationalized, they’re of no value.
It’s also here that you’ll learn the basics of streaming versus batch both in model development and implementation. Spark has come on very fast with extremely high adoption rates and is the basic tool now for both batch and streaming.
Should You Specialize Early?
In the Development world you will increasingly only be selected if you have a specialty. In the Production world you are likely to have more opportunities if you don’t specialize. Having said that there are two areas you may want to examine which can be picked up fairly rapidly and are considered specializations within the Production world.
Supply Chain Forecasting: There are some very specific techniques and packages associated with true demand driven supply chain forecasting that can provide an unique entre in the world of manufacturing or logistics.
IoT for Manufacturing: This is the use of predictive models on streaming data from SCADA systems and the like to predict the quality of output during a production run or the imminent failure of a piece of capital equipment.
If you wanted to make your living in an area dominated by manufacturing you would consider adding these to your portfolio early in your career.
For the most part however, if you’re in the Production world, predictive modeling and recommenders will be a complete toolset for several years.
Remember also that our profession is changing fast. It is already well past the time that a single data scientist could master the entire field. Employers may still be looking for unicorns but very rapidly there will be emerging specialty fields you may consider as your career progresses. Deep learning, natural language processing, image processing, and AI are all examples that will take either additional education or serious OJT.
What about the rumors of those outsized salaries even for beginners? Well they are at least partly true in that you will earn a well above average salary compared to other analyst or IT staff positions. You’re not going get a Silicon Valley salary if you’re working in Milwaukee.
The best salary and skills studies come from O’Reilly. Their most recent survey for example says that a Master’s degree will only add about $3,500 per year to your earnings. This is a well done survey that evaluates not only salary but time spent in different tasks, tools used, and other factors. Be sure to carefully evaluate who filled out the surveys and whether you think they are representative. There are no purely objective bias-free surveys in our profession.
As Your Career Progresses
 Data science has been and continues to be a field in which knowledge of tools as well as business in paramount. We utilize a complex toolbox to extract, blend, clean, transform, engineer, model, and implement models that can create business value from data that only a few years ago was not considered valuable.
Data science has been and continues to be a field in which knowledge of tools as well as business in paramount. We utilize a complex toolbox to extract, blend, clean, transform, engineer, model, and implement models that can create business value from data that only a few years ago was not considered valuable.
It should come as no surprise that innovation is simplifying and automating the toolbox of existing tools even as new tools are arising. In the past if we were expert carpenters with great skill with our tools, in the future we will be more like architects bringing a broad range of tools and design skills to bear to build value.
In management consulting where I spent many years we used to say that a consultant needs three legs to stand on, domain knowledge (knowledge of a particular industry), process knowledge (deep understanding a particular process such as planning, manufacturing, or accounting), and methodology (in management consulting this means process improvement, reengineering, strategy development, or package implementation among others). As your career progresses you should build your own foundation on these three principles where methodology becomes the skills of data science that you’ve mastered. The other two legs, deep knowledge of one or more industries and one or more business processes will be why future employers seek you out.
About the author: Bill Vorhies is Editorial Director for Data Science Central and has practiced as a data scientist and commercial predictive modeler since 2001. He can be reached at:
{kind=link}